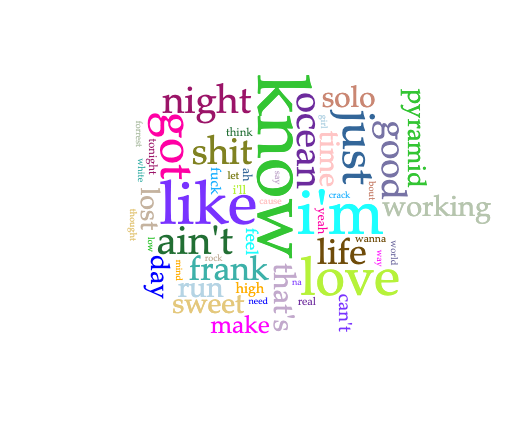For my first foray into Voyant, I decided to take a look at a guilty pleasure of mine: the scathing book review. I know I’m not the only one who likes reading a sharp, uncompromising take on a book. Reviews along the lines of Lauren Oyler’s excoriation of Jia Tolentino’s debut essay collection go viral semi-regularly; indeed, when Oyler herself wrote a novel, some critics were ready to add to the genre. (“It’s a book I’d expect her to flambé, had she not written it.”)
I was curious if these reviews differed from less passionate (and less negative) reviews in any way that would show up in text mining.
Initial Process
To investigate, I assembled two corpora: a small set of scathing reviews, and a small set of mildly positive ones. The parameters:
- Each corpus included 5 reviews.
- I drew the reviews from Literary Hub’s Bookmarks site, which aggregates book reviews from notable publications. Bookmarks categorizes reviews as “pan,” “mixed,” “positive,” and “rave.” I drew the “scathing” corpus from reviews tagged as pans, and the control set from positive reviews.
- I used the same 5 reviewers for both sets. (This was tricky, since some of the reviewers I initially chose tended to only review books that they either truly hated or — more rarely — unequivocally loved. Call this “the hater factor.”)
- I only selected books I haven’t read yet — unintentional at first, but I decided to keep with it once I noticed the pattern.
- I tried to select only reviews of books that fell under the umbrella of “literary fiction,” (though what that means, if anything, is a debate in itself) though American Dirt is arguably not a great fit there (but was reviewed so scathingly in so many places, I couldn’t bear to leave it out — maybe call this “the hater’s compromise”).
- I specifically stayed away from memoir/essays/nonfiction, since those are so often critiqued on political, moral, or fact-based grounds, which I didn’t want to mix with literary reviews (but if this post has made you hungry for some takedowns along these lines, the Bookmarks Most Scathing Book Reviews of 2020 list contains memoirs by Michael Cohen, John Bolton, and Woody Allen — you’re welcome).
Here are my corpora:
The Scathing Corpus
| Review Title | Review Author | Published In | Book | Author |
| I couldn’t live normally | Christian Lorentzen | London Review of Books | Beautiful World, Where Are You | Sally Rooney |
| Ad Nauseam | Rebecca Panokova | Harpers | To Paradise | Hanya Yanagihara |
| Yesterday’s Mythologies | Ryan Ruby | New Left Review | Crossroads | Jonathan Franzen |
| American Dirt | Parul Sehgal | The New York Times | American Dirt | Jeaninne Cummims |
| Pressure to Please | Lauren Oyler | London Review of Books | You Know You Want This | Kristen Roupenian |
The Control/Positive Corpus
| Review Title | Review Author | Published In | Book | Author |
| Can You Still Write a Novel About Love? | Christian Lorentzen | Vulture | The Answers | Catherine Lacey |
| Either/Or | Rebecca Panokova | Bookforum | Either/Or | Elif Bauman |
| When Nations Disappear, What Happens to Nationalities? | Ryan Ruby | New York Times Book Review | Scattered All Over the Earth | Yoko Tawada |
| Lauren Oyler’s ‘Fake Accounts’ Captures the Relentlessness of Online Life | Parul Sehgal | The New York Times | Fake Accounts | Lauren Oyler |
| Why are some people punks? | Lauren Oyler | London Review of Books | Detransition, Baby | Torrey Peters |
Analyzing each corpus in Voyant
Voyant was pretty easy to get started with — but I quickly realized how much more I’ll need to know in order to really get something out of it.
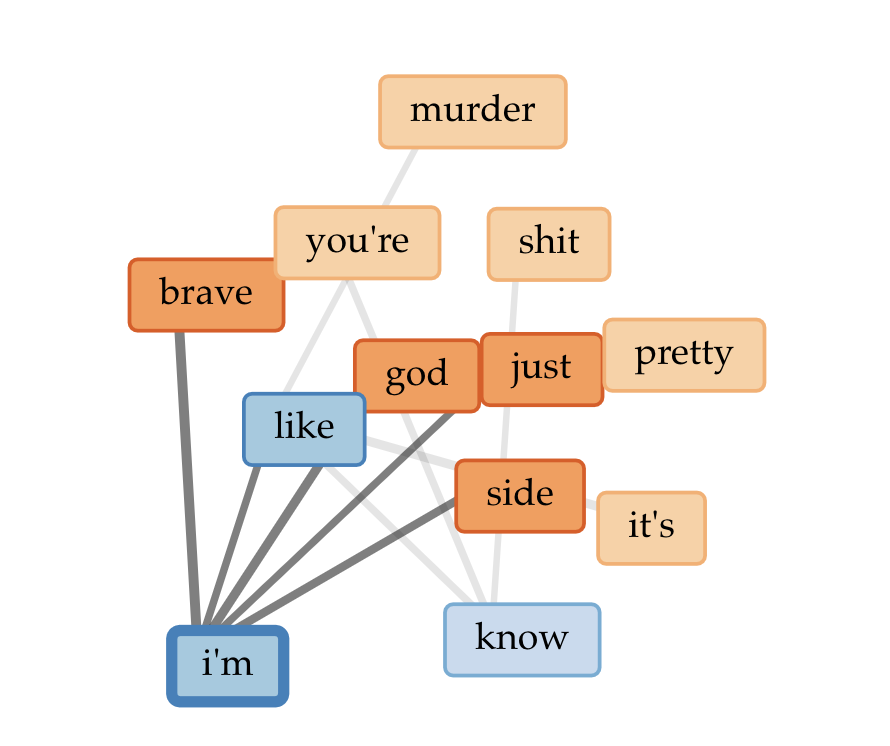
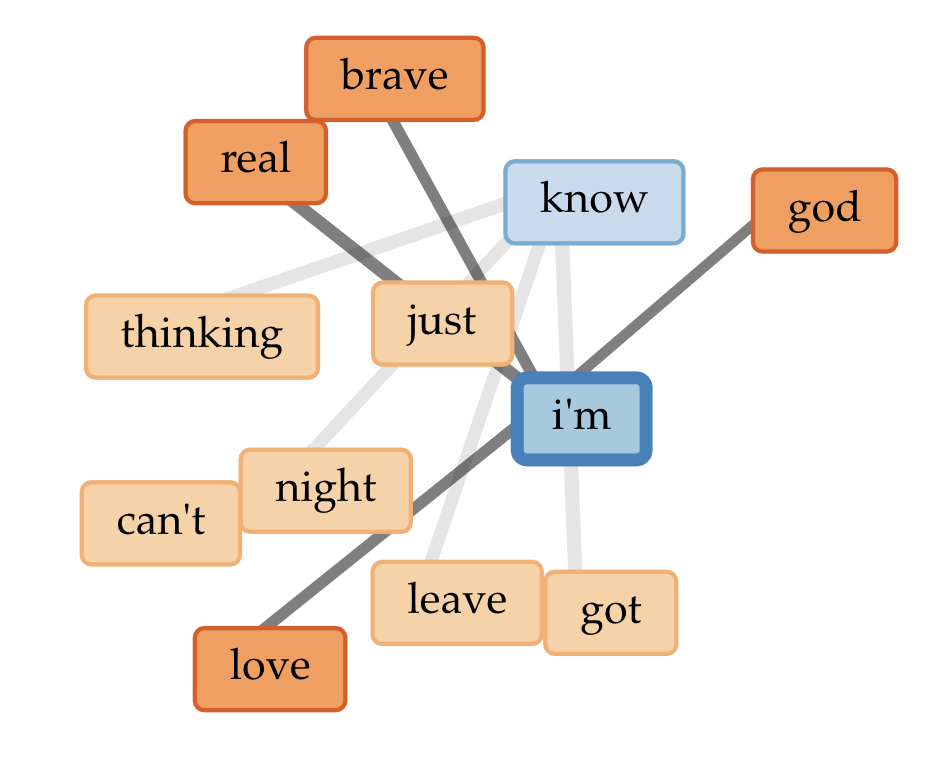
I created my corpora by pasting the review URLs into two Voyant tabs. My first observation: an out-of-the-box word cloud or word frequency list, perhaps especially for a small corpus of short texts like mine, is going to contain a lot of words that tell you nothing about the content or sentiment.

I read Voyant’s guide to stopwords, then attempted to eliminate the most obvious unhelpful words, including:
- Author names (Yanagihara, Franzen) and parts of book or review titles (Paradise, Detransition) – these would have been way less significant if I’d started with a large corpus
- Words scraped from the host websites, rather than review text (email, share, review, account)
- Words with no sentiment attached to them (it’s, book, read)
If I were doing this as part of a bigger project, I’d look for lists of stopwords, or do more investigation into tools (within or beyond Voyant) related to sentiment analysis, which would fit better with what I was hoping to learn.
Even with my stopword lists, I didn’t see much difference between the two corpora. However, when I compared the two corpora by adding the Comparison column to my Terms grid on one of them, I did start to see some small but interesting differences — more on that below.
What I learned
Frankly, not much about these reviews — I’ll get to that in a second — but a little more about Voyant and the amount of effort it takes to learn something significant from text mining.
Some things I would do differently again next time:
- Add much more data to each corpus. I knew five article-length items wasn’t much text, but I hadn’t fully realized how little I’d be able to get from corpora this small.
- Set aside more time to research Voyant’s options or tools, both before and after uploading my corpora.
- Create stopword lists and save them separately. Who would have guessed that my stopwords would vanish on later visits to my corpus? Not me, until now.
- Use what I’ve learned to refine my goals/questions, and pose questions within each corpus (rather than just comparing them). Even with this brief foray into Voyant, I was able to come up with more specific questions, like: Are scathing reviews more alike or unlike each other than other types of reviews? (i.e., could Tolstoy’s aphorism about happy and unhappy families be applied to positive and negative reviews?) I think having a better understanding the scathing corpus on its own would help me come up with more thoughtful ways to compare it against other reviews.
Very minor takeaways about scathing book reviews
As I mentioned, I did gain some insight into the book reviews I chose to analyze. However, I want to point out that none of what I noticed is particularly novel. It was helpful to have read Maria Sachiko Cecire’s essay in the Data Sitters Club project, “The Truth About Digital Humanities Collaborations (and Textual Variants).” When Cecire’s colleagues are excited to “discover” an aspect of kid lit publishing that all scholars (and most observers) of the field already know, she points out that their discovery isn’t a discovery at all, and notes:
“To me, presenting these differences as a major finding seemed like we’d be recreating exactly the kind of blind spot that people have criticized digital humanities projects for: claiming something that’s already known in the field as exciting new knowledge just because it’s been found digitally.”
So here’s my caveat: nothing that I found was revelatory. Even as a non-expert in popular literary criticism, the insights I gained seemed like something I could have gotten from a close read just as easily as from a distant one.
The main thing I really found interesting — and potentially a thread to tug on — came from comparing word frequency in the two corpora. There weren’t any huge differences, but a few caught my eye.
- The word “bad” appeared with a comparative frequency of +0.0060 in the “scathing” corpus, compared to the “positive” corpus. When I used the contexts tool to see how they occurred, I saw that all but one of the “scathing” uses of bad came from Christian Lorentzen and Lauren Oyler’s reviews. Neither reviewer used the word to refer to the quality of the text they’re reviewing (e.g., “bad writing”). Instead, “bad” was used as a way to paraphrase the authors’ moral framing of their characters’ actions. For Lorentzen, Salley Rooney’s Beautiful World, Where Are You includes “…a relentless keeping score… not only of who is a ‘normal’ person, but of who is a ‘good’ or ‘bad’ or ‘nice’ or ‘evil’ person.” Oyler uses the word to discuss Kristen Roupenian’s focus on stories that feature “bad sex” and “bad” endings. That literary reviewers pan something for being didactic, or moralistic, or too obvious is nothing surprising, but it’s interesting to see it lightly quantified. I’d be interested to see if this trend would carry out with a larger corpus, as well as how it would change over time with literary trends toward or against “morals” in literature.
- I found something similar, but weaker, with “power” — both Oyler and Ryan Ruby (panning a Jonathan Franzen novel) characterize their authors’ attempts to capture power dynamics as a bit of shallow didacticism, but the word doesn’t show up at all in the positive corpus.
- Words like “personality” and “motivation” only show up in the negative critiques. It’s also unsurprising that a pan might focus more on how well or poorly an author deals with the mechanics of storytelling and character than a positive review, where it’s a given that the author knows how to handle those things.
- Even “character” shows up more often in the scathing corpus, which surprised me a bit, since it’s a presumably neutral and useful way to discuss the principals in a novel. To add further (weak!) evidence to the idea that mechanics are less important in a positive review, even when “character” does turn up in an otherwise positive review, it was more likely to be mentioned in a critical context. For example, in Oyler’s overall positive review of Torrey Peters’ Detransition, Baby, she notes that “the situation Peters has constructed depends on the characters having a lot of tedious conversations, carefully explaining their perspectives to one another.” As with everything else, I would want to see if this still held in a larger corpus before making much of it. It’s very possible that the reviewers I chose are most concerned with what they find dull. From my other reading of her work, that certainly seems true of Oyler.
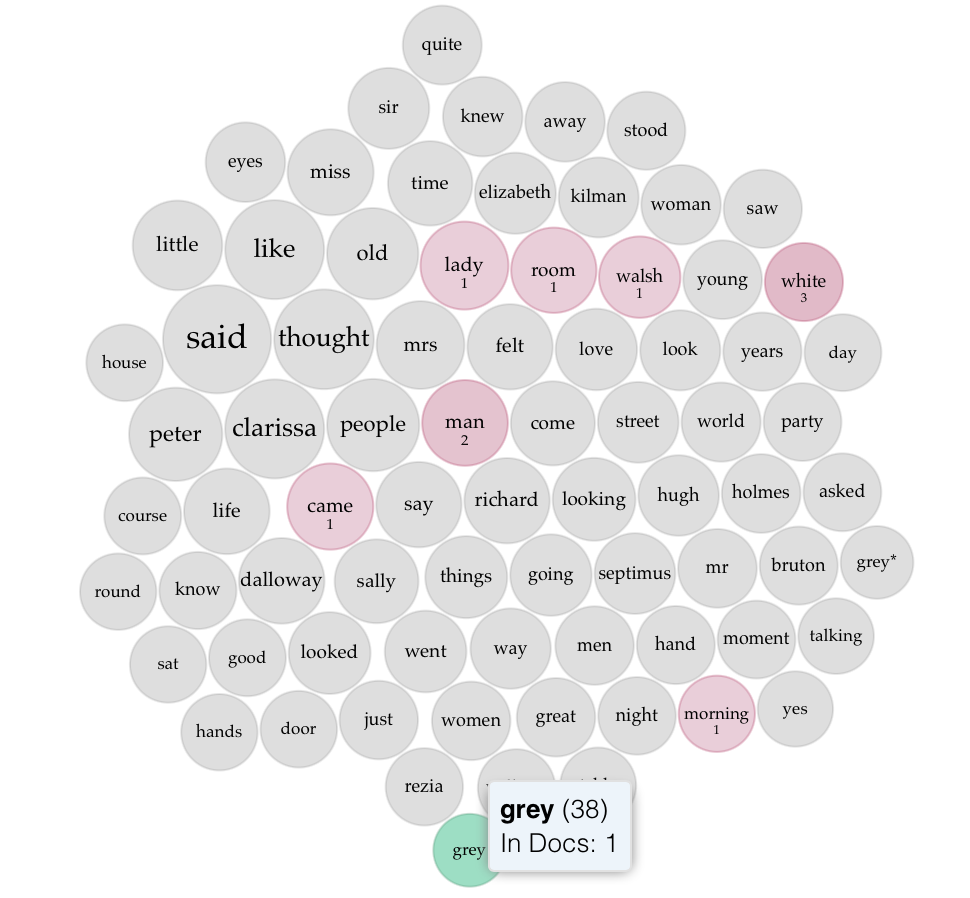
To test these observations further, I’d need to build a bigger corpus, and maybe even a more diverse set of copora. For example, if I were to scrape scathing reviews from Goodreads — which is much more democratic than, say, the London Review of Books — what would I find? My initial suspicion is that Goodreads reviewers have somewhat different concerns than professional reviewers. A glance at the one-star reviews of Beautiful World, Where Are You seems to bear this out, though it’s interesting to note that discussion of character and other mechanics shows up here, too:





This would be a fun project to explore further, and I could see doing it with professional vs. popular reviews on other subjects, like restaurant reviews. Fellow review lovers (or maybe “review-loving haters”?), let me know if you’re interested in poking into this a bit more.