
For my text mining praxis assignment, I decided to use Python’s Natural Language Processing (NLP) package, also called Natural Language Toolkit (NLTK). Further to last month’s text analysis workshop, I thought it would be a good idea to put into practice what learnt.
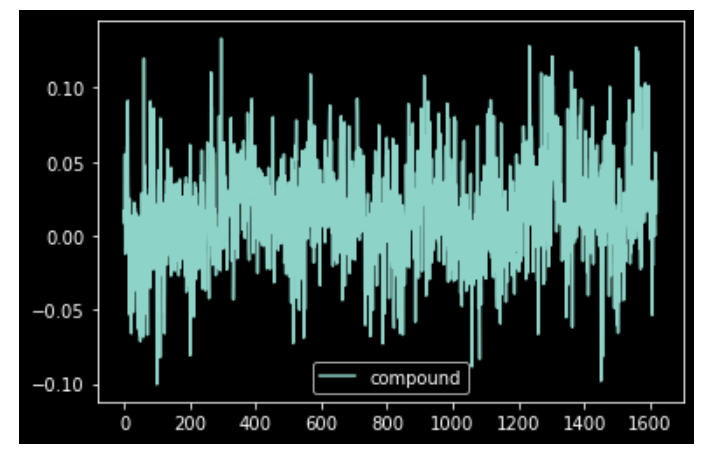
I picked Jane Eyre, a book I read few times in both the original language and a couple of translations, to ensure I could review the results with a critical eye. The idea was to utilise NLP tools to get an understanding of the sentiment of the book and a summary of its contents.
In an attempt to practice as much as possible, I opted for an exploratory approach to trial as different features and libraries. At the bottom of this post, you will find my Jupyter notebook (uploaded on Google Colab) – please note that some of the outputs exceed the output space limit, hence you might need to open them in your editor. In terms of steps undertaken, I was able to create a way to “assess” words (positive, negative, neutral) and run a cumulative analysis on big part of texts to gather a sense on how the story develops. Separately, I wrote a function to summarise the book, which drove the length of it from 351 pages to 217 (preface, credits, and references included), however I am not sure about the quality of the result!! Here in PDF this “magic” summary!
Clearly the title of my blog post is meant to be provocative, but I can see how these algorithms could be used as shortcuts!
Before diving into the notebook though, I would like to share a few of thoughts on my takeaways on text analysis. On the one hand, it is impressive to witness the extent to which the latest technologies can take unstructured data, interpret it, translate it into a machine-readable format, and then make it available to the user for further analysis or manipulation. Machines can now operate information extraction (IE) tasks by mining meaningful pieces of information from texts with the aim of identifying specific data, or targets, in contexts where the language used is natural and the starting dataset is either semi or fully unstructured. On the other hand, I personally have concerns around the fact that text mining softwares perform semantic analyses that often can only leverage a subsection of the broader spectrum of knowledge. This is to say that the results produced by these technologies can certainly be valid, however, could be limited by the inputs and related pre-coded semantics, hence potentially translating into ambiguous outputs.
There is a chance that the below HTML will not render the notebook, if so, you can download it directly from myGitHubGist.

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.