This site contains student blog posts and teaching materials related to DHUM 70000: Introduction to the Digital Humanities, which was taught by Profs. Matthew K. Gold and Krystyna Michael at the CUNY Graduate Center in Fall 2022. We will leave the content of the site available as a record of our class and a resource for others who might be interested in the topics we covered. Please contact us if you have any questions about the material that appears on the site.
Python is a great programming language and one of the fastest-growing programming languages in the world due to its versatility. Python can be used for mobile app development, web development, and data analytics because of supporting a vast number of modules and packages. Although Python is known for its user-friendliness and readability, it inherits all the hardships that involves in learning any programming language. This is especially true for people from various backgrounds, such as Digital Humanities scholars. The goal of this project proposal is to change that. We propose PyNLPVIS which is a low-code library for Natural language processing and data visualization. PyNLPVIS will be a series of cohesive, reusable functions that will streamline text analysis and data visualization. The library will be hosted as a PyPi project so that, it can be easily accessible not only to humanists but also to the masses.
Methods
The project will be written in python as a module and will be shared as a PyPi project to enhance accessibility. Below is the simplest code for parts of speech tagging with NLTK barring that the textual data is already clean.
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from collections import Counter
text = "It is necessary for any Data Scientist to understand Natural Language Processing"
text = text.lower()
tokens = nltk.word_tokenize(text)
pos = nltk.pos_tag(tokens)
the_count = Counter(tag for _, tag in pos)
print(the_count)
PyNLPVis will create an abstraction by taking care of data processing from Line of Code(loc) text = text.lower() till the end in the background. To accomplish this the library will be equipped with a sample function like the following.
def pos_tagger(text):
text = text.lower()
tokens = nltk.word_tokenize(text)
pos = nltk.pos_tag(tokens)
the_count = Counter(tag for _, tag in pos)
print(the_count)
Once we set up the library as a PyPi project, the user will simply integrate the library in their python script with the following loc.
import pos_tagger from PyNLPVis
Then the user needs to simply pass the text data using the following command to get a result from POS tagging.
pos_tagger(/*User defined text*/)
The low code nature of PyNLPVis has reduced the necessity of writing several locs to just a couple of locs for this instance.
Also visualizing the output of the pos_tagger for instance as a Word Cloud, the user has to simply do the following
import word_cloud from PyNLPVis
pos = pos_tagger(/*User defined text*/)
word_cloud(pos)
If making programming more accessible is the name of the game, in that sense most python workshops do an excellent job to pull learners with beginner-friendly design.
In-detail learning, in the beginning, is extremely useful for avid learners.
Since by design most of the workshops are low stakes, learners never feel intimidated by the content.
Low-stakes nature ensures participants from diverse communities and backgrounds.
The bad:
Doesn’t address the different learning rates of the learners.
For programming workshops, motivation is often proportionate to the challenge presented. Because of the low stake nature and lack of challenge, motivation curbs down significantly after the initial session.
The Ugly:
Doesn’t teach real-world concepts like debugging and computational thinking. Who writes raw codes nowadays? More often than not, Developers go to stack overflow to seek solutions and ended up debugging thousands of lines of code suggested by the others developer communities.
Utopia or the Future of Programming?
Since the inception of artificial intelligence, it has been just a moment away when some genius computer scientist will come up with the idea of teaching an inherently dumb machine how to speak its language. Yes, I am referring to training an artificial neural network (ANN) with codes that community-like stake overflow has built over time. What an ingenious idea to make programmers obsolete! I call it the next evolution. Hey, if the machine running GitHub Copilot can generate code to generate solutions that are meant to help us rather than extinguish us. Programmers will always be involved in guiding the machines and evaluating what they have produced. However, the role will change. I assume the programmers will have to debug more codes in the future rather than write raw codes. The future is not far away when entry-level programming jobs are replaced by bots and neural networks.
This is a reflection of our reading/discussion on mapping and GeoHumanities this semester.
We discussed Monmonier, Mark. How to Lie with Maps. 2nd ed. The University of Chicago Press, 1996. (Chapter 1 and 2, 20 pages) in our class, and I did some further readings on this topic, shown as follows:
Dear, Michiael et al. Geohumanities: Art History Text at the Edge of Place. London: Routledge, 2011.
Engberg-Pedersen, Anders. “Introduction: Enstranging the Map: On Literature and Cartography.” In Literature and Cartography: Theories, Histories, Genres, 1–18. Cambridge Massachusetts: MIT Press, 2017.
Cooper, David, Christopher Donaldson, and Patricia Murrieta-Flores. “Introduction: Rethinking Literary Mapping.” In Literary Mapping in the Digital Age, edited by Cooper, David et al. 1–22. Abingdon and New York: Routledge, 2016.
I am very much interested in research projects at the intersection of geospatial technologies, digital storytelling, and literary studies, and I believe it is important for us to consider questions regarding the definitions of “space,” “place,” and “landscapes” in our own lives. For example, Cresswell gives excellent examples in his introduction, talking about location, locale, and sense of place, three concepts made by John Agnew. You will definitely make different connections when you see 40.7128° N, 74.0060° W, New York, museums/gardens/restaurants/bars you go to in New York, GC CUNY, and your home in NYC. And you are also doing place-making activities in traditional ways, like home decorations, and in new ways, like reporting an issue in Google Maps. These critical issues direct me to think more about space and place in cartographic imagination in history, literature, politics, business, etc. So I started to use concepts of map elements, projections, and symbols mentioned by Monmonier in his book to analyze and critique bad examples and so-called strange maps. Delightful experience! And I hope we can all explore the world and get lost on purpose in the future by harnessing various mapping tools.
For challenges when using mapping tools to tell stories/do digital storytelling, I will always ask myself some underlying questions, such as why do we map? What is to be mapped? Should we move beyond digital mapping tools? Can GIS be integrated with other methodologies in the humanities and geographic information science?
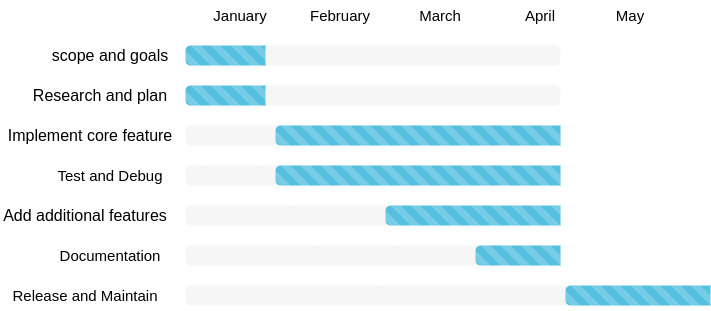
Introduction: For the final project, I propose to design custom markup schemas and tagsets for encoding research writings we make on Japanese women directors. The project is a digital experiment searching for methods to create research-based DTD (Document Type Definition) that contain critical and interpretative tags which we use to deliver bio details on birth, name, family, education, and significant life events but also marks the contextual information on women directors’ career paths, such as team, co-worker, award, organization, company, funding, social movement, dual profession, etc. I will post my abstract, examples I create to explain XML/DTD, director names I collect, and feminist markup projects I refer to for your reference. NOTE: A Document Type Definition (DTD) is a set of rules that define the structure of an XML file. A well-formed XML document does not require a DTD and can just follow common rules but creating a DTD can ensure the integrity and consistency of the XML document. Our project will define elements, attributes, relationships, and constraints to customize the DTDs to give interpretive information in greater detail.
Abstract: Asian women’s images in the film industry have long been filtered through a Western male gaze and thus have been historically objectified as exotic and fetish beauties. Asian women filmmakers’ efforts also do not receive the same attention in a male-dominated film culture of auteurism. However, within the past few years, we have seen rising Asian women directors in the industry and their films gaining recognition. A generation of Asian women directors has achieved success in domestic and international film circles, including Yoon Ga-eun, Kawase Naomi, and Chloé Zhao, to name a few. In the meantime, there is also an emerging group of scholars working on introducing, translating, and analyzing these women’s works to reshape the images of Asian women in film studies. The Japanese Women Directors Project (JWDP), a public-facing platform that creates open educational resources featuring women’s voices in the Japanese film industry, represents a step in the new direction of cinema feminist interventions. This project builds upon Phrase 2 of the JWDP, which explores ways of constructing director profile pages and producing the scholarly history of studies on Japanese women as creators in the film industry. Our project aims to use descriptive markup language (Extensible Markup Language) to encode interpretive entries as the research on Japanese women directors is being carried out. We plan to serve the needs of educators, students, and the public, who expect to efficiently find a broader range of genres and styles produced by women directors. Unlike other TEI (Text Encoding Initiative) projects that annotate and store the structural elements in preexisting textual materials, our project is experimental to the extent that we are encoding research writings that we are currently making. The result of this project contributes to Phrase 3 of the JWDP, which delivers our born-digital encoded content through a searchable database.
Examples of XML/DTD I made:
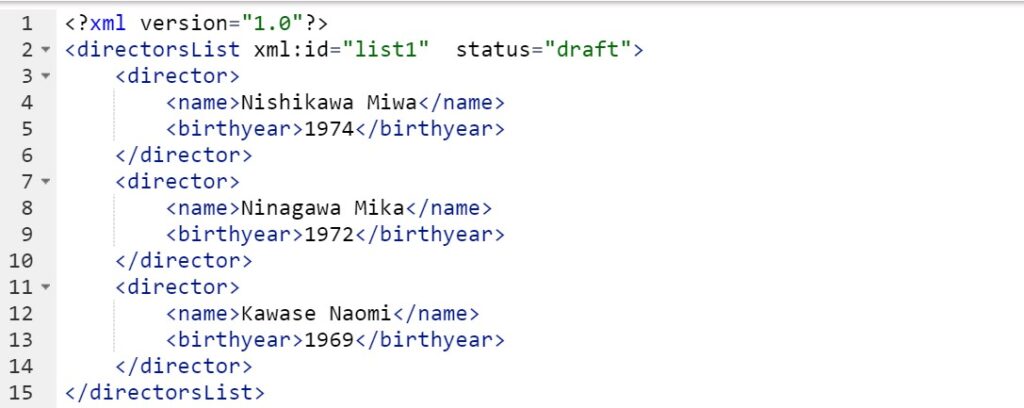
Figure 1. A minimal XML document example
The start tag (e.g., <director>) marks the point in the sequence that an element starts, and the element closes with the end tag (e.g., </director>). We can also add attributes to the document. Here attribute values are specified for the <directorsList> element through the attributes xml: id and status. Later an XML processor can recognize this <directorList> as a draft instead of the final version, and the “list1” could label its element occurrence for later cross-reference works.
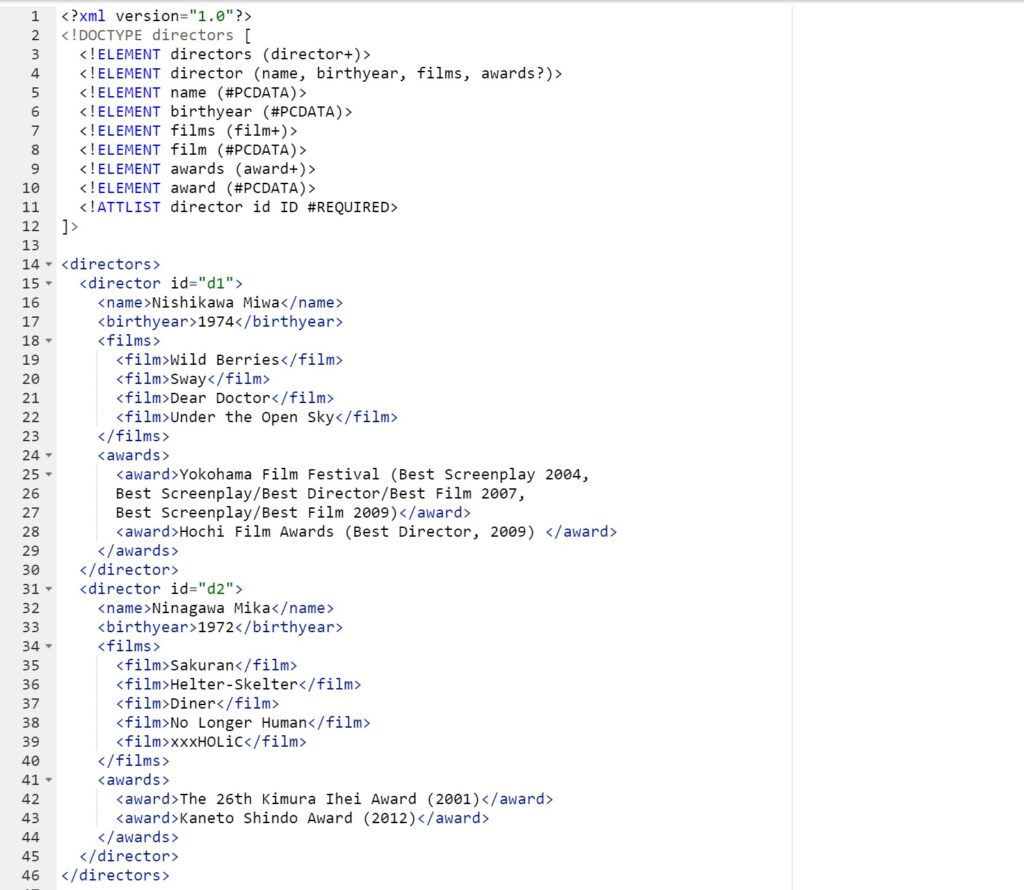
Figure 2. An example of the DTD
In this example, the DTD is defined within the DOCTYPE declaration. The DTD specifies that the document’s root element is <directors>. The root element can contain one or more <director> elements. Each <director> element must have an id attribute and can contain a <name>, a <birthyear>, a <films>, and an optional <awards> element.
The above examples are just at a very minimal level and the final step is to build a delivery system using XSLT, Java-related technologies, and Apache Tomcat that allows users to search and navigate the data we create.
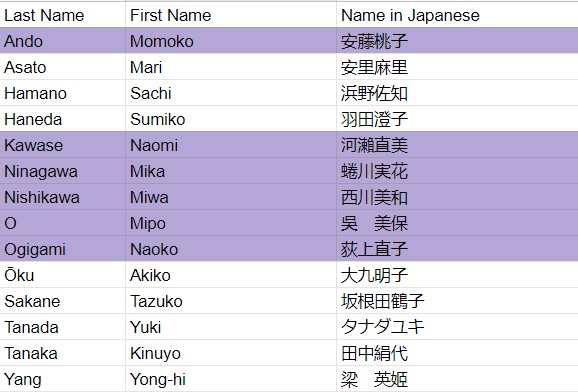
Women directors for the first trial: When we use the words “Japanese” and “women” to identify our research targets, we are referring to all directors self-identified as women, including Japanese women working outside Japan and non-Japanese women working in Japan. The first trial of this project will be very specialized, covering a range of fifteen Japanese women directors who make live-action narrative films. We hope to monitor the trial’s progress and expand the scope in a later stage to include women working on other genres, such as animation, documentaries, and experimental films. The primary objective of this project is to create a structured and organized database of Japanese women directors encoded by XML (Extensive Markup Language), making it easier to search and retrieve specific pieces of information on relevant subjects in their lives and works, such as education, employment, production, network, and social work.
Read more: Beshero-Bondar, Elisa, Raffaele Viglianti, Helena Bermúdez Sabel, and Janelle Jenstad. “Revising Sex and Gender in the TEI Guidelines.” Accessed December 22, 2022, https://doi.org/10.5281/zenodo.7091048.
Brown, Susan, Patricia Clements, and Isobel Grundy, eds. “Introduction.” Orlando: Women’s Writing in the British Isles from the Beginnings to the Present. Cambridge University Press, 2022. Accessed December 22, 2022, https://orlando.cambridge.org/about/introduction.
Cummings, James. “The Text Encoding Initiative and Study of Literature.” In A Companion to Digital Literary Studies, edited by Susan Schreibman, Ray Siemens, and John Unsworth, 451–476. Malden, MA: Blackwell Pub., 2004.
Pierazzo, Elena. “Textual Scholarship and Text Encoding.” In A New Companion to Digital Humanities, edited by Susan Schreibman, Ray Siemens, and John Unsworth, 307–321. Chichester: John Wiley & Sons, Ltd., 2016.
Before assessing the capability and dissecting the structure of CUNY commons, let me express my appreciation for CUNY common. The concept is perfect. I appreciate the thought behind it and how it makes knowledge produced in various CUNY institutions accessible to all CUNY students.
CUNY Commons is built on the concept of multisite. BuddyPress, a community-building plugin that allows having forums and groups on top of WordPress has been used. The lead developer of the project is Boone B. Gorges who is also the lead developer of the BuddyPress plugin and a former student of the Graduate Center.
Disclaimer!! All the assumptions I have made from here on are based on poking around CUNY Academic Commons on GitHub and the website’s source code. I could be mistaken, after all, I am human.
The folder of the theme for CUNY academic common(CAC) is bp-nelo. I assume this is a modified theme of the bp-default theme. The website is running on the latest BuddyPress plugin 10.6. This is great because it shows that CAC has been getting regular updates. CAC is open source and all the development is available on GitHub.
I assume CAC is using Reclaim Hosting, an educator-friendly hosting service. CAC provides users the ability to host their own site, this is a feature of the BuddyPress plugin. The users can set up their site with the shared hosting of CAC. This provides users limited access to the WP dashboard through abstraction. Users can add pages, change themes(themes that are available within Commons, the number of themes is growing!!), manage users just like hosting their own website with a hosting service. All these features are free for all CUNY students!! This makes CAC a great place to showcase coursework, and academic projects, or even make a portfolio.
Now comes the criticism! Throughout the semester, I faced problems receiving notifications from the common groups. This is most likely to do with the notification management system of the BuddyPress plugin. I assume this is a BuddyPress bug. Also, how about those distorted emails forwarded from the Commons? CAC uses wired URL masking, which does not play well within the forwarded message. Occasionally, the hyperlink embedded within the email turned out to be broken. I assume the WP Better Emails plugin has been integrated with BuddyPress for formatting HTML emails so that they can be forwarded to the users. Furthermore, I believe the issue with email formatting is not site-wide. It probably has something to do with group settings, maybe? The developer knows better! Anyway, it is high time that CAC fixes this issue.
The development progress and logs for CAC are available at
First-generation college students are the first in their families to go to college. Since they are the first in their families, they are often left to figure out the complicated higher education system in the United States of America on their own. Without proper guidance, students can feel overwhelmed by filling out complex applications such as the FASFA and scholarship application and, among other unfamiliar tasks, to enroll and stay in college. They need help understanding college 101 terminology such as prerequisites, capstone, or hybrid. A lack of understanding of Student Success strategies such as time management, Habits of Mind, or navigating several digital tools can be detrimental to their college success. Because of such complicated and unfamiliar higher education territory, students can feel alone and as if they don’t belong in an institution of higher learning. They may also be unfamiliar with the college resources available, such as the Wellness Center, Tutoring Services, Offices of Accessibility, or the Ombudsman Office. This can cause students to get stressed, have anxiety, and, unfortunately, drop out of college.
Peer Mentorship via Social Media digital project aims to provide peer mentorship through platforms where students would most effectively receive information, such as social media platforms like Instagram or Tic Tok. This content would be created and curated by a team of mentorship experts, mentors, and mentees. The goal is for First Generation students to learn and be prepared to succeed in college regardless of the hurdles they may face.
Overbaked and Underproofed: An interactive investigation of the judging language in the Great British Baking Show (GBBS), seeks to create and provide a platform that fosters a critical engagement with an aspect of language as used in a popular reality TV phenomenon.
By extracting and analyzing the vocabulary and language usage in the judging segments of a season of GBBS, the project seeks to probe the perceived paucity of evaluative language and then look at what the results might reveal about our culture’s easy relationship with quick judgment and our in/ability to translate the sense of taste for a screen-based medium.
Via a website targeted at the general audience of GBBS and interested linguists, the project features visualizations of the analyzed language, academic discourse around the problems and methods of the topic, as well as an interactive Judge-this-bake Bingo game (populated with the most frequently used judgment expressions) that can be played while re/watching episodes of GBBS. The project aims to induce a shift in popular media consumption by bringing consciousness to the use of evaluative expressions and the framework of judgment, ultimately producing a new and expanded literacy.
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: