
Since starting my academic journey in DH over two years ago, I’ve been awaiting the moment when I’ll get to learn about text mining/analysis tools. I’ve worked in the “content” space my entire career and I’ve always been interested in the myriad tools out there that allow for new ways to look at the written word. I spent nearly a decade as an editor in the publishing world, and I never leveraged an actual text analysis tool, but I jerry-rigged my own approach for scouring the web for proper usage when I found myself confused on how to best render a phrase. My go-to text analysis “hack” has always been to search google for a phrase I’m unsure of in quotes, and then to add “nytimes.com” to my search query. This is based on my trust that the copyeditors at NYT are top notch and whatever usage they use most often is likely the correct usage. For instance, if I encounter the usage of “effect change” in some copy I’m editing and I’m not sure whether it should be “affect change,” I would do two separate searches in Google.
- “affect change” nytimes.com
- “effect change” nytimes.com
The first search result comes up with 72,000 results. The second result comes up with 412,000 results. Thus, after combing through the way the term is used in some of the top results, I can confidently STET the use of effect change and move on without worrying that I’ve let an error fly in the text. I’ve used this trick for years and it’s served me well, and it’s really as far as my experiments in text mining have gone until this Praxis assignment.
Diving into this Praxis assignment, I was immediately excited to see the Google NGram Viewer. I had never heard of this tool despite working in a fairly adjacent space for years. Obviously, the most exciting aspect of this tool is its absolute ease of use. It runs on simple Boolean logic and spits out digestible data visualizations immediately. I decided to test it out by using some “new” words to see how they’ve gained in published usage over the years. I follow the OED on Twitter and recall their annual new words list announcement, which for 2022 was produced as a blog post doing its best to leverage the newest additions in its text. You can read the post here: https://public.oed.com/blog/oed-september-2022-release-notes-new-words/
The NGram has a maximum number of terms you can input, so I chose the words and phrases that jumped out at me as most interesting.
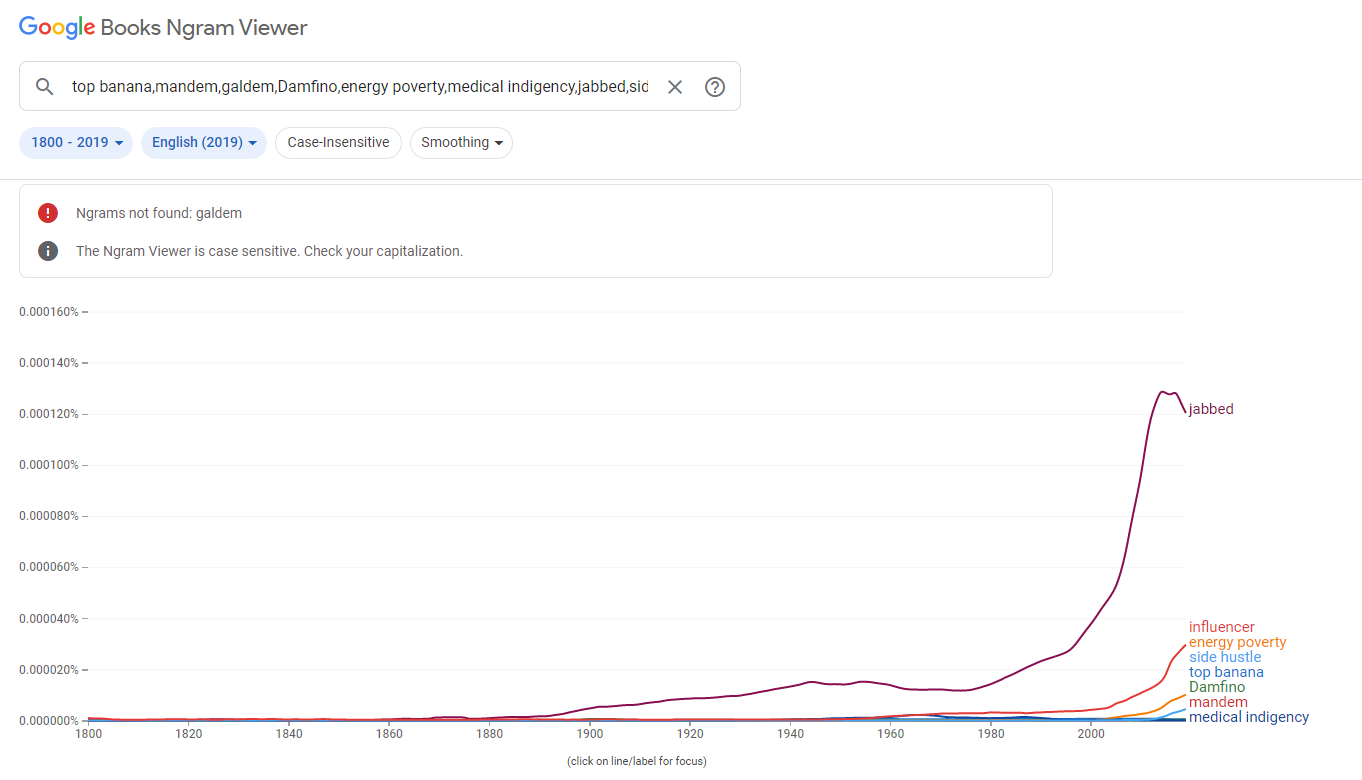
The words I chose from the post were (in order of their recent frequency as spit out by NGram): jabbed, influencer, energy poverty, side hustle, top banana, Damfino, mandem, and medical indigency. As you can see, most of these terms are all quite new to the published lexicon — all but “jabbed.” However, jabbed in the early 20th century likely had more to do with boxing literature than vaccinations.
Moving along in this vein, I then looked up the “word of the year” winners dating back the last decade. These words were: omnishambles, selfie, vape, post-truth, youthquake, toxic, climate emergency, and vax. 2020 did not have a word of the year for reasons I suspect have to do with the global pandemic. Looking at the prominence of these words in published literature over the years showed a fairly similar result as the “new” words list.
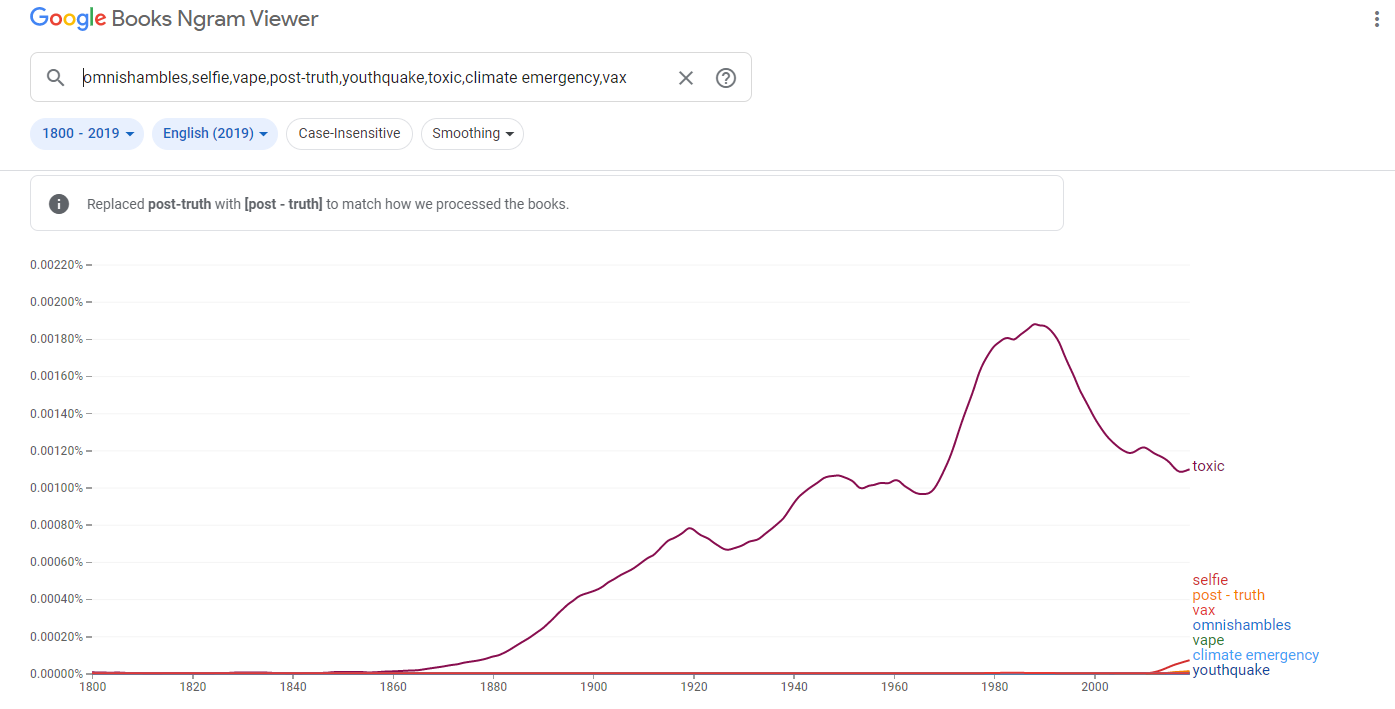
What I found surprising is that these words and phrases are actually “newer” than the ones I pulled from the new words list. There’s barely a ripple for all these words outside of “toxic,” which has held populat usage for over a century now according to NGram.
Despite to say, as a person who routinely looks up usages for professional purposes, I’m elated to discover this tool. It will not only help me in my DH studies, but will also assist me in editorial work as I look for the more popular usage of terms. Instead of having to us Google’s own search engine and discern the results myself, I can now see simple visualizations that will prove one usage’s prominence over another.
NGram is well and good, but I could tell this was a bit of a cop out when it came to learning the ins and outs of text mining. So I decided to test out Voyant Tools to see if I could get a handle on that. As was noted in the documentation, it is best to use a text I am familiar with so I can make some qualitative observations on the data this is spit out. I decided to use my recently submitted thesis in educational psychology, as there’s likely not much else I’m more familiar with. My thesis is titled, “User Experience Content Strategies for Mitigating the Digital Divide on Digitally Based Assessments.” Voyant spat out a word cloud that basically spelled out my title in via word vomit in a pretty gratifying manner.

This honestly would have been a wonderful tool to leverage for the thesis itself. As I tested 200 students on their ability to identify what certain accessibility tools offered on digital exams do, I had a ton of written data from these students and I could have created some highly interesting visualizations of all the different descriptive words the students used when trying to describe what a screen reader button does.
I’ve always known that text analysis tools existed and were somewhat at my disposal, yet I’ve never even ventured to read about them until this assignment. I’m surprised by how easy they are to get started with and am excited about leveraging more throughout my DH studies.

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.
Enjoyed this exploration— always interesting when the data surprises. I got curious about the tool and went over to Ngram and tested out YOLO only to find that it had a huge surge in the 1820s. That got me on a rabbit hole a bit. Landed here— https://www.hollywood.com/celebrities/a-yolo-history-lesson-drake-s-slogan-dates-back-to-the-1700s-46937180-60230473
not sure if it really tells the full story— still digging, but just an interesting set of questions that can emerge from data and lead us in new directions.
I like your MacGyver approach to text mining /analysis during your career! The visualization of the word cloud for your thesis made me curious to want to know more about the research you conducted for your thesis. I wonder what reflections and observations you made from creating the word cloud and thinking about the completed thesis.