I just wanted to ping you all a brief message on the GC New Media Lab (NML). Yesterday afternoon I attended their General Meeting and wanted to share a couple of takeaways. First, it is a fantastic place, Marco Battistella and his team are extremely competent and have a lot to share, plus they are really keen to hear students’ ideas and projects in order to support them through their expertise combined with the vast technology available at the Lab. The latter has web hosting capacity and several packages available for students, including Drupal, Final Cut Pro X, WordPress, Omeka, Abdobe’s Suite, and more.
For this meeting, the focus was on Omeka, an open-source tool enabling creators to build online digital collections and exhibits; so, if you are thinking about a library or archive for your final project, you should definitely check Omeka out. Further points were also discussed such as how the Lab can help students develop their digital projects.
To get access to the Lab resources and know-how, Master’s students are required to have a recommendation letter from the faculty (typically, this would be provided by the Programme’s advisor), after which they can submit their application and schedule their first one-to-one with the Lab staff, who will support them through project planning and project development/implementation.
My annotation to Scott’s first chapter of The Four-Dimensional Human is related to the following passage:
I turned back to see the tame, daytime guise of that narrow little passageway, so inconvenient and improvised. My mind retraced the journey back through the passage, into the office and out into the landing, where the locked door protected its secrets. I smiled at my idiocy, for it was suddenly clear that, all along, it had been me inside the forbidden room.
The desk's disarray, my papers and his papers, the computer and the rows of books, even the white sky outside, became vivid with realisation. I had been chasing myself. During those evening hours I had been simultaneously inside and outside the room. In art instant, all of my theories about its contents fell in on themselves, and the blankness was imprinted with a sudden picture, a selfie before its time.
Prompts to the students: in 1917, Pirandello, a Sicilian writer also known for being a precursor of the later existentialist Theatre of the Absurd, wrote a short novel called “La Carriola” (which translates into the wheelbarrow) where he describes the life of a professor and attorney who suddenly starts to see himself from the outside, consequently acknowledging his own misery and unhappiness. The epiphany is the product of the realisation that his job and daily activities are simply masks that prevent him for living an authentic life. His conclusion is that his real self has changed so profoundly, and possibly irreversibly, purely as a consequence of being unconsciously molded by other people’s expectations and perceptions. What’s your view on this?
Do you see a parallel between this century-old novel and Scott’s narration? If so, how can you extend it to the contemporary use of social media? Similarly, how can this awareness be a stimulus to an eyes-wide-open usage of digital tools? Would you say that Scott’s concerns around the fourth dimension somehow represent the acknowledgment of how media platforms constantly remind us of an increasing social pressure that stays with us even in the dark and solitude of our own private spaces?
For my text mining praxis assignment, I decided to use Python’s Natural Language Processing (NLP) package, also called Natural Language Toolkit (NLTK). Further to last month’s text analysis workshop, I thought it would be a good idea to put into practice what learnt.
I picked Jane Eyre, a book I read few times in both the original language and a couple of translations, to ensure I could review the results with a critical eye. The idea was to utilise NLP tools to get an understanding of the sentiment of the book and a summary of its contents.
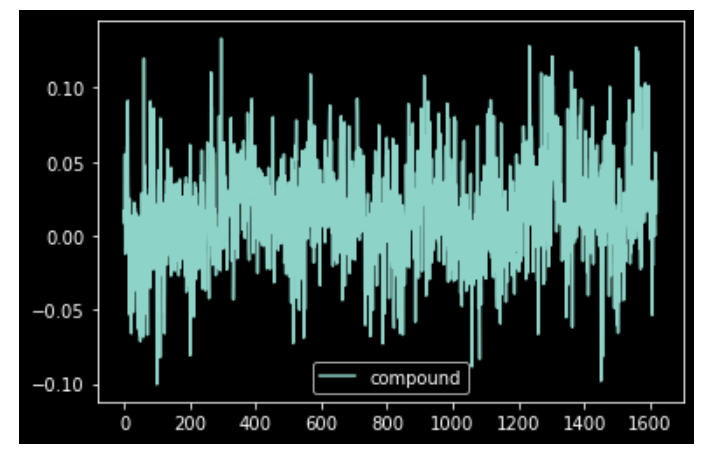
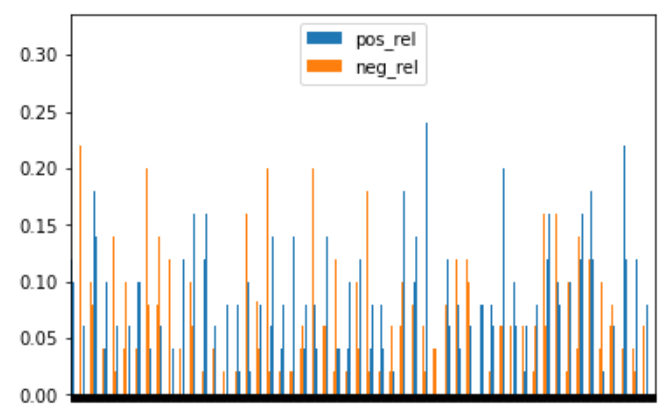
In an attempt to practice as much as possible, I opted for an exploratory approach to trial as different features and libraries. At the bottom of this post, you will find my Jupyter notebook (uploaded on Google Colab) – please note that some of the outputs exceed the output space limit, hence you might need to open them in your editor. In terms of steps undertaken, I was able to create a way to “assess” words (positive, negative, neutral) and run a cumulative analysis on big part of texts to gather a sense on how the story develops. Separately, I wrote a function to summarise the book, which drove the length of it from 351 pages to 217 (preface, credits, and references included), however I am not sure about the quality of the result!! Here in PDF this “magic” summary!
Clearly the title of my blog post is meant to be provocative, but I can see how these algorithms could be used as shortcuts!
Before diving into the notebook though, I would like to share a few of thoughts on my takeaways on text analysis. On the one hand, it is impressive to witness the extent to which the latest technologies can take unstructured data, interpret it, translate it into a machine-readable format, and then make it available to the user for further analysis or manipulation. Machines can now operate information extraction (IE) tasks by mining meaningful pieces of information from texts with the aim of identifying specific data, or targets, in contexts where the language used is natural and the starting dataset is either semi or fully unstructured. On the other hand, I personally have concerns around the fact that text mining softwares perform semantic analyses that often can only leverage a subsection of the broader spectrum of knowledge. This is to say that the results produced by these technologies can certainly be valid, however, could be limited by the inputs and related pre-coded semantics, hence potentially translating into ambiguous outputs.
There is a chance that the below HTML will not render the notebook, if so, you can download it directly from myGitHubGist.
Cumulative distribution anlysisPositive vs negative “sentiments” as the story develops
Last week we attended the workshop “How to Hook Your Audience”, an event held in person at the Graduate Center aimed at sharing helpful tools and strategies designed to better craft research narratives in both an informative and engaging way. The session was led by Dr. Machulak, the founder of a company that supports both scholars and professionals in bringing their research and ideas to either new or different contexts. Dr. Machulak is also a writer and editor.
The three of us individually decided to join this seminar, but immediately agreed on the opportunity of doing something different by deciding to co-write this post. The idea is to share our views and takeaways, while avoiding potential repetitions on describing the contents and dynamics of the seminar.
In an effort to allow the reader to compare and contrast our personal takeaways and learning experience, we came up with four questions that we decided to separately answer before finetuning the below “interview style” blog post.
Premise: the workshop revolved around 3 key points:
how to deliver the same message, or argument, to different people;
ways of studying and approaching these audiences;
suitability of communication channels based on the above.
Questions we asked ourselves:
1.The moderator described the perfect ‘hook’ as the interception among logos, ethos, and pathos or, in plain English, rationale (or argument), audience, and credibility. Do you agree? If so, in your view, what are the main challenges?
[Colin answers] I sort of agree. Incorporating rationale, audience, and credibility into your hook is great. But I also think that the main challenge could be ending up in overthinking the product: a hook is a hook! It doesn’t necessarily have to sound too clever or anything – that can come later, possibly after you’ve already grabbed an audience’s attention. Even if the hook seems an unsophisticated clickbait, most people will still take that bait – even though they would never admit it!
[Gemma answers] Similarly to Colin, I only sort of agree. Certainly, reading the audience is important, alongside with ensuring that the argument presented is solid, however, credibility could be an issue. Credibility is something that gets built over years, generating a number of difficulties for students who might have, undeniably, valid theses to present, but not that immediate confidence that would translate into authority into the eyes of the audience. Other challenges might rotate around non-native English speakers or international individuals who might find the current lingua franca an impediment to their credibility.
[Zico answers] I kind of agree. However, the challenge lies within the answer. At a glance, questions around logos, ethos, and pathos seem straightforward; nevertheless, answering these questions is rather difficult. At some point, to cater to or hook the audience, one might have to pivot and present ideas in a different way, and this might be extremely challenging.
2. How can what you have learnt at the workshop be applied to Digital Humanities?
[Gemma answers] Digital humanists, by nature, heavily rely on online platforms which, inevitably, entail a huge exposition to different types of audience. As for everything, the keys are the message and who the message is intended for. Hence, simultaneously crucial are the intention and the crafting process. It might sound obvious, but one’s message goes hand in hand with the communication style and the distribution channel/s chosen. In brief, do not assume your audience understands you; do your due diligence, spend some time to prepare, and do not be afraid of tailoring your research to meet your listeners’ or viewers’ needs.
[Colin answers] Hooking your audience with DH is a different, but exciting, challenge. And that’s why we’re here! For instance, Dr. Machulak showed us the photograph below to showcase what a good hook looks like; in this case the cougar was portrayed to visually represent what 2 meters (6ft) looks like in the context of social distancing. This sign is also a great example in terms of incorporating Aristoteles’s principles of persuasion. An image or using some form of multimedia to hook your audience, done right, could be a more powerful draw than words.
[Zico answers] The approach introduced by Dr. Machulak might be extremely helpful to push DH projects outside the academia universe. Since asking questions like who we have left behind is at the core of DH, I believe that, by following the logos-ethos-pathos structure, serving a broader audience will be achievable.
3. How could the tension between public and academia be addressed when trying to hook multiple communities outside academia with your research?
[Zico answers] In my opinion, the tension between the public and academia lies within the expectations. Publics expect results while academic research not only has to come up with them but must also address ethics and morals that surround the approach chosen to produce those results. To address the tension between the public and academia, academic research often has to rephrase the message by adopting an audience-first approach, where results will shadow critical topics like ethics and morals. I am not in favor of wall gardening the critical aspects, but highly believe that higher abstraction is a requirement of greater magnitude.
[Colin answers] Identify the specific tension your research brings between academia and the public: most of the times, the tension is just a misunderstanding between two parties, so stating the miscommunication in your hook could be a great way to bridge the gap. Nevertheless, there will be times where you won’t be able to get beyond stubbornness. In those cases, you should use the Context/Audience(Broad)/Audience(Specific) approach learned at the workshop that helps to tailor your hook based on your public and how to ensure the latter actively engages in your research and ideas.
[Gemma answers] There should be no tension in first place, however, sadly, some form of gap is there. In this sense, an academic audience might need far less details when it comes to technical explanations of terminology and contents but could require higher level of information on one’s work’s limitations and methodology. On the other hand, an audience made of non-technical individuals, might not even be aware of issues related to the methodology used, hence the hook should reflect that.
With this in mind, it was interesting for us when a CUNY neuroscientist, who was attending the workshop with us, brought to our attention how she was struggling in explaining to the general public how brain waves work. It was thought-provoking as she confessed to us how “easy” it had been to present her thesis to a purely academic audience, while now having issues in handling non-experts’ expectations and questions.
4. Overall, what’s the most important thing you’ve learnt?
[Colin answers] Overall, Dr. Machulak presented her material well, and her qualifications on the topic were evident. I particularly liked how she asked us not to disclose any personal projects any of us would choose to share with the group. The most important thing I have learned was the idea of incorporating Aristotle’s principles of persuasion into a hook. Easier said than done, but that will stick with me.
[Gemma answers] My main takeaway rotates around the importance of being able to situate any work I would like to present in the right context, which includes ensuring that my rationale (what are my core claims and evidence?), credibility (why am I the best person to make this argument?) and audience (how will I connect with my target audience?) are intersecting in a point where my hook will become effective and memorable.
[Zico answers] How to introduce academic research into a project and attract a diverse public has always been a difficult question for me to answer. In my opinion, Dr. Machulak’s idea of structuring a project by asking specific questions on the argument presented is extremely helpful. She specifically introduced the terms logos (will it support my immediate argument?), ethos (is it within my areas of expertise?), and pathos (will it resonate with my target audience?). These are all important questions to identify how to hook broader audiences.
On Friday, the GCDI Digital Fellows hosted a workshop on how to use online libraries and programming languages for text analysis purposes. The session revolved around Python and its Natural Language Tool Kit (NLTK), an inbuilt platform that specifically works with human language data. NLTK allows the conversion of texts, such as books, essays and documents, into digitally consumable data, which implies a transformation of qualitative contents into quantitative, and therefore decomposable and countable, items. The workshop did not require prior experience with NLTK and resulted in an extremely effective session.
I thought of different ways of summarising what was covered during the seminar in a way that other people would find useful and decided to write a step-by-step guide that incapsulates the main aspects discussed and some additional pieces of information that can be helpful when approaching Python and Jupyter Notebook from scratch.
Required downloads/installations
A Text Editor (aka where the user writes their code) of your choice, I opted for Visual Studio Code, alternatively Notepad would do – FYI: Google Docs & Microsoft Word will not work since they are not text editors, but word processors;
It is an interpreted language, hence it does what the user tells it to.
It is object-oriented; mostly Python has ‘classes’ of objects, and almost everything is an object.
Python is designed to be readable.
Jupyter Notebook
Jupyter Notebook is structured data that represents the user’s code, metadata, content, and outputs. When saved to disk, the notebook uses the extension .ipynb, and uses a JSON structure. Jupyter Notebook and its interface extend the notebook beyond code to visualisation, multimedia, collaboration, and more. In addition to running codes, it stores code and output, together with markdown notes, in an editable document called a notebook. When saving it, this is sent from the user’s browser to the notebook server which, in turn, saves it on disk as a JSON file with a .ipynb extension.
Remember: do save each new file/notebook with a name, otherwise it will be saved as “unnamed file”. You can type in your search bar Jupyter and see if it is already installed on your computer, otherwise you can click > Home Page – Select or create a notebook
When ready, you can try the below steps in your Jupyter Notebook and see if they produce the expected result/s. To comment in Jupyter you can use the dropdown menu selecting “markdown” instead of “code”. Alternatively, you can use either 1 or 2 # signs.
In Jupyter every line can be a code, or a comment, and each line can be run independently – also, lines can be amended and rerun.
To start type these commands in your Jupyter Notebook (commands are marked by a bullet point and comments follow in Italic):
import nltk
nltk stands for natural language tool kit
from nltk.book import *
the star means “import everything”
text1[:20]
for your reference: text1 is Moby Dick
this command prompts the first 20 items of the text
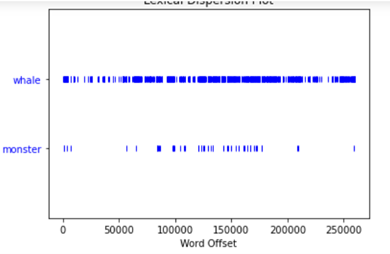
text1.concordance(‘whale’)
Concordance is a method that shows the first 25 occurrences of the word whale together with some words before and after – so the user can understand the context – this method is not case sensitive
Before proceeding, let’s briefly look at matplotlib.
What is matplotlib inline in python
IPython provides a collection of several predefined functions called magic functions, which can be used and called by command-line style syntax. There are two types of magic functions, line-oriented and cell-oriented. For the purpose of text analysis, let’s look at %matplotlib, which is a line-oriented magic function. Line-oriented magic functions (also called line magics) start with a percentage sign (%) followed by the arguments in the rest of the line without any quotes or parentheses. These functions return some results, hence can be stored by writing it on the right-hand side of an assignment statement. Some line magics: %alias, %autowait, %colors, %conda, %config, %debug, %env, %load, %macro, %matplotlib, %notebook, etc.
import matplotlib
%matplotlib inline
Remember that Jupyter notebooks can handle images, hence plots and graphs will be shown right in the notebook, after the command.
text1.dispersion_plot([‘whale’, ‘monster’])
text1.count(‘whale’)
this command counts the requested word (or string) and is case sensitive – so searching for Whale or whale DOES make a difference.
As the count command is case sensitive, it is important to find a way to lower all words first and then count them accordingly. See below a new list made of lowered words. We can call the new list text1_tokens = []
text1_tokens = []
for word in text1:
if word.isalpha():
text1_tokens.append(word.lower())
It is now possible to quickly check the new list by using the following command.
text1_tokens[:10]
The next step would be to count again; this time the result will be made of ‘whale’ + ‘Whale’ + any other combination of the word whale (i.e. ‘WhaLE’).
text1_tokens.count(‘whale’)
Further to the above, it is possible to calculate the text’s lexical density.Lexical density represents the number of unique (or distinct) words over the total number of words. How to calculate it: len(set(list)/len(list) the function ‘set’ returns a list containing only distinct words. To exemplify:
numbers = [1, 3, 2, 5, 2, 1, 4, 3, 1]
set(numbers)
The output should look like the following: {1, 2, 3, 4, 5}
Let’s use this on text 1 now. The first step requires to check the unique words in the newly created ‘lowered list’. Then, the next command asks the computer to spit out only the number of unique words, and not to show the full list. Finally, it is possible to compute the ratio of unique words over total of words.
set(text1_tokens)
len(set(text1_tokens))
len(set(text1_tokens)) / len(text1_tokens)
Let’s slice it now and create a list of the first 10,000 words. This allows to compare, for example, the ratio of text1 to the ratio of text2. Remember, it is very dangerous to draw conclusions based on such a simplified comparison exercise. The latter should be taken as a starting point to generate questions and provide an insightful base to work on more a complex text analysis instead.
t1_slice = text1_tokens[:10000]
len(t1_slice)
len(set(t1_slice))/10000
t2 = [word.lower() for word in text2 if word.isalpha()]
This week’s readings cement a concept that is not as obvious as it might sound: facts are a matter of perspective. Similarly, history is a matter of perspective.
An event, any event, can be subjected to a myriad of different narrations, which could be considered veritable if accounting for the storyteller’s background and their angle. Acknowledging this without attempting to arrogate the right of divulging a universal truth is no easy task though. In this sense, the 911 Digital Archive project plays a key role in preserving history as collected from its sources. And with a great sense of acceptance in doing so, which translates into the ability of understanding, and consequently embracing, how everyone lived the same tragic day in different ways.
In this sense, Brier and Brown, in their publication The September 11 Digital Archive, stress the speed at which a system aimed at gathering as many testimonies as possible, both in digital and analog formats, had to be brought to life within days from the attack.
The authors try to go beyond what mainstream media institutions present and ask themselves the question of what consequences the 9/11 attacks generated in everyone’s life including, if not especially, the one of “ordinary” people who were either at work or going to work, those who were floating around the area of the impact, maybe spending the day somewhere in New York City or perhaps somewhere else farther, and others, who were not necessarily on site, but happened to receive a message from someone somehow directly involved.
9/11 Memorial, photo taken from personal phone, September 2022
Their idea of collecting materials, in any form or shape, and from everyone, directly and indirectly, is remarkable, and, in a sense, avant-garde. The concept revolves around the action of gathering testimonies and evidence when facts happen as opposed to wait for them to be brought together by the media or through ‘post-mortem’ research. In this light, the introduction of the role of the archivist-historian is revolutionary, and orbits around the notion of perspective and the creation of a 360-degree viewpoint, or collective history, where everybody has the right, and the channels, to actively contribute.
A similar project is carried out by the curators of Our Marathon, an online accessible archive of photos, stories, and videos of the 15th of April 2013 Boston attack. Once again, the ‘game changer’ is the authors’ modus operandi whose goal is to ensure that the contributions to the platform are crowdsourced and free from potential media manipulation.
Using this approach, new tools to accurately build a collective and democratic history have become progressively available. Platforms like Omeka, CUNY Digital History Archive, and Home – Mukurtu CMS allow everyone to share their experience and perspective. The value of this relatively new way of operating when building archives is immense and, undoubtedly, grows over time. Personally, I feely lucky to live in an era where I am given the opportunity, and the means, to contribute to history with my own experiences and angle. Unlike my grandparents, who were both sent abroad to fight during WWII and witnessed the war’s atrocities, I know I have the luxury of crystallising (and sharing) my day-to-day life and views through the internet and its endless devices, whereas their legacy, and their days in Greece, Germany and Russia, only live in my memory and might soon get lost.
I would like to share with you something personal which I think has some relevance in respect to this week’s readings on the “datalogical” turn, the “digitization of everything” and, eventually, the digitization of us.
My partner was asked to attend an online cryptocurrency course (how original these days!) and, as part of the terms of reference, he had to consent to the use of a software that would analyse his interactions with other participants.
As his first videocall with the course group was on speaker I could hear most of the conversation (I promise I was not being nosy!), which was pretty uneventful as the class members were introducing themselves, cracking some jokes, laughing, and lightly chatting about the newly introduced workload, probably in an effort to neglect the burden of those additional tasks that would stretch everyone’s already-stretched capacity. I ended up not paying too much attention; it seemed to me like a relatively friendly dialogue among people who did not really know each other. How wrong of me!
Shortly after the call, a report was circulated with a detailed analysis of the participants’ interactions. What I read was scary. The report quantified the number of words said by each person, the “energy” and “sentiment” attached to each word (whatever that means), the reactivity to other speakers’ statements and some corrections to improve the “quality” of the conversation (i.e. add some breathing, stop more often between sentences, etc.). And, to push the use of the word outrageous to its full extent, the software would also rate participants. Thus, for example, a shy individual would get a very low mark (you need to speak up!), whilst a witty person would be assessed as “too engaging” (sorry mate, you’re trying too hard!).
What is the moral of this anecdote? Well, in a sense I found this, what I would have implored to be left confined in an experimental dimension, utterly shocking. Who defines whether a word is positive or negative? The dictionary? History? Talk-shows? An arbitrary use can drive almost any word, or sentence, in both directions. Figures of speech also have nuances and their meaning depends on how they are used; irony and sarcasm are frequently an expression of scepticism; an uncertainty in the voice can represent an only partially formed opinion..and I guess the list of examples of ambiguity could be endless.
So, this is the day of reckoning, this is it: the augmented version of text analysis, speech analysis, that everyone was waiting for and, with a great simultaneous feature (it took virtually no time for the software to produce this report)! This is AI at its core.
Why do I care? Simple, this is my very personal room 101: AI’ed conversations that would reveal one’s insecurities in speaking, unveil gesticulation as a form of protection, highlight badly translated jokes and expose those insular cortexes, like mine, that have not yet found their full identity in a language rather than another. This AI application is what I would call forced Darwinism, where the wide adoption of a certain technology, especially in everyday life, might result in a mechanism aimed at standardizing conversations, flows and, ultimately (and sadly), thoughts.
I still have hope though. I hope people will be “equipped” with the freedom of refusing the adoption of a such discriminatory use of speech analysis. And I hope people will be able use this right.
It’s been a difficult week for me as I have been recovering from the worst possible Covid wave one could catch (sigh), however, I am now doing better and managed to spend some time completing the mapping task.
Below you will find a simple website I built as part of this week’s praxis assignment; please note that instead of creating a blog post with my experience here, I have decided to incorporate the narrative part, together with some key aspects of this small project, directly in the website (all very experimental for me I will admit!). I’d love to hear your feedback, so please reach out and let me know what you think!
Despite the progress made on the discourse around the concept of “big tent” which would later produce a significant shift from its construct as originally conceived, conversations on the scope of Digital Humanities have, understandably, persevered and continued to permeate the discipline. The field’s full spectrum is yet to be reached, or even comprehended, as an increasing number of initiatives claim their right to be housed.
Nevertheless, if there was a “big tent”, it would probably be designed to resemble Reviews in Digital Humanities (a pilot of a peer-reviewed journal that facilitates scholarly evaluation of digital humanities work and its outputs).
Yet, the “structure” of Reviews in Digital Humanities has a peculiar flavor and appears to be a garden more than a pre-assembled construction, encompassing a natural openness to those projects that share the ability to harmoniously combine technology and humanities while providing a fertile territory for new initiatives. In this sense, in its latest issue, the journal examines a browser-based device which has the potential to simplify text-analysis and bring coding requirements for non-tech savvy scholars and other researchers to the bare minimum (jsLDA).
Here other interesting DH initiatives also discoverable through this publication: Pelagios and Linkedarchives
Assuming a common intent of cultivating a continuous dialogue whilst ensuring a wide understanding of technologies applications and an ongoing participation to standards development, platforms like Reviews in Digital Humanities perfectly serve the purpose, simultaneously representing a constant stream of information and a communication channel for the growing DH community.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: