
A/N: This post contains a lot of information about my project, Map Lemon. If you don’t want to be deeply confused about what Map Lemon is and why it is, you can head on over to my blog at https://noveldrawl.commons.gc.cuny.edu/research/, as I’m not explaining it for the sake of brevity in this post. The corpus itself is not yet publicly available, so you’ll just have to trust me on the docs I’m using for now.
I’ll start this post with a bit of introduction on my background with text mining. I’m a Linguist. I’m a Computational Linguist. And more importantly than either of those two really nebulous phrases that I’m still convinced don’t mean much, I made a corpus. I am making a corpus, rather (everything is constantly moving changing and growing). It happened by accident, out of necessity—it wasn’t my original research interest but now that I’m deep in it I love it.
My corpus, Map Lemon, is #NotLikeOtherCorpuses (I’m sorry for that joke). It’s not text mined. A LOT of linguistic corpuses are text mined these days and that gets on my nerves in a real bad way. Here’s why:
Let’s use the example that you’re text mining on Twitter to get a better idea of jargon used within a niche community, since this use-case is quite common.
- Text mining often takes phrases out of their contexts because of the way platforms like Twitter are structured.
- These aren’t phrases that, generally speaking, are used in natural speech or writing. While cataloging internet speak is important, especially to understand how it affects natural S&W, we’re not cataloging as much natural S&W as a result, and I don’t think I need to explain why that’s important.
- It’s not situational. You’re not going to find recipes for lemonade, or directions to a lemonade stand yes I’m making a joke about my own research here on Twitter.
- You’re often missing demographics that are unknown that can affect the content of the corpus.
I chose to do this praxis assignment to debunk, or at least attempt to, all of those things. I want text mining to work for me. It probably won’t for my use-case, but I should at least be versed in doing it!
Now let’s get into it.
I decided to text mine my own corpus. Yup. I’m at a stand-still with the results I’ve been getting and need material for an abstract submission. Here we go.
So, since my data has already been cleaned before, I went ahead and just plopped it into Voyant. The following ensued:
- Oh, rats I forgot I can’t just do that with all the demographics and stuff in there and confuse Voyant.
- Okay, copy the file. Take out all the not responses. Might as well separate them into their respective experiments while I’m at it.
So, the final version of what I’m analyzing is: 1) Just the directions to the lemonade stand 2) Just the recipes for lemonade. I’m not analyzing the entire corpus together since it wouldn’t yield coherent results for this specific purpose due to the difference in terminology used for these two tasks and lack of context for that terminology.
The results from the directions were really neat in that you can follow the correlations and word counts as directions given, basically. Here’s the map from Experiment I so you can follow along:
Here are the most common phrases in the directions given, according to analysis with Voyant:
- “before the water fountain”; count: 4
- “take the first left”; count: 4
- “a carousel on your left”; count: 3
- Some other phrases that are all count 3 and not as interesting until…
- “at the water fountain”; count: 3
- “between the carousel and the pond”; count: 3
Now, okay, these numbers aren’t impressive at first glance. Map Lemon only has 185 responses at present, so numbers like this maybe aren’t all that significant, but they sure are interesting. Map Lemon contains exclusively responses from North Americans, so from this we could postulate that North Americans tend to call “that thing over yonder” a water fountain or a carousel. But also from this we can see the directions Chad gets most commonly: people often send him down the first left on the street; of the group that does not, and has him cut through the park, they let him know that he should pass the carousel on the left; and the lemonade stand is just before the water fountain. All these directions are reiterated in two different ways, so it seems. That sure is neat! Not particularly helpful, but neat.
So let’s look at those cool correlations I mentioned.
- ‘gym’ and ‘jungle’ – correlation: 1 (strongest)
- ‘clearing’ and ‘paved’ – correlation: 1
- This one I’m unsure what is really meant by it, if that makes sense, but it was ‘enter’ and ‘fork’ corr. 1
- ‘home’ and ‘passed’ – correlation: 1
These look like directions alright! Okay, of course there’s the phrase ‘jungle gym’, but we do see, okay, there’s a paved clearing. I’m sure at some point Chad has to enter a fork, although I’m a bit confused by that result, and yes, many people did have Chad pass the house. Neat!
I’m a bit skeptical of some of these correlations as well, because it’s correlating words strongly that only appear once, and that’s just not a helpful strong correlation. But that’s just how the tool works.
Looking at contexts wasn’t particularly helpful for the directions, as lot of the contexts were for the words ‘right’ and ‘left’.
Now, here’s what was really freakin’ cool: the links. Voyant made this cool lil graphic where I can see all the most common words and their links. And it actually shows… directions! The 2/3 most common paths, all right there, distilled down. Try giving Chad directions for yourself and see what I mean, ‘cause it’ll probably look something like this:
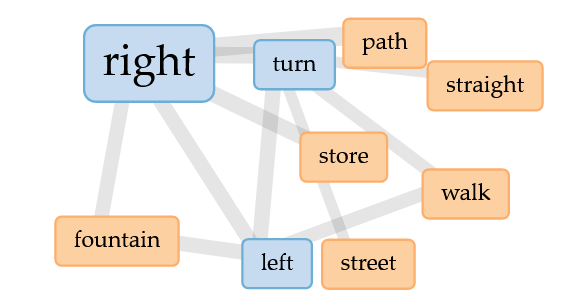
Voyant’s link map for Map Lemon Experiment I
Okay, so the directions didn’t show anything revolutionary, but it was pretty darn cool. Let’s move onto the recipe analysis.
NOW THIS IS FREAKIN’ COOL!!! According to the phrase count tool, everybody makes lemonade about the same! Including using a lot of the same amounts of ingredients and even the same filler phrases!
Ingredients:
- 1 cup sugar; count: 3 (the semantics of this compared to the other two is really interesting!)
- 3 cups of water; count: 3
- 4 lemons; count: 3
Filler phrases:
- “a lot of”; count: 5
- “make sure you have”; count: 5
- “kind of”; count: 4 (context for this one is tricky)
Perhaps that’s a recipe I could try!
Now, okay. If we’re skinning cats, there’s not a lot of ways to skin this one, actually. We specifically chose lemonade for this experiment because it’s ubiquitous in North America and really easy. And the correlations feature wasn’t really helpful this time around for that exact reason (lack of distinguishing words). But look at this cool link map thingy!!
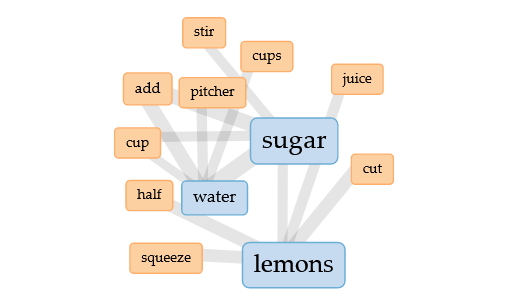
Voyant’s link map for Experiment II
Very helpful! You either squeeze, cut, juice, or halve your lemons—not all four (and two of those are only different out of semantics). Add several cups of water to a pitcher, and stir in (or add—again, semantics) at least a cup of sugar. Boom! There’s our lemonade recipe. This was so cool to synthesize!
At the end of this little project, I am still as annoyed with the inability to use demographics with text mining as I was before. This means that demographics for text mining for my purposes would have to be very carefully limited to control for individual linguistic variants. However, I also see the benefit in this tech; although, I definitely think it’d be better for either larger datasets or datasets that have a very controlled demographic (so that small numbers like 3 and 4 are actually statistically significant). Mostly, for now, it seems that the results just make me say “cool!”. I love the visual links a lot; it’s a really good example of graphics that are both informative and useful. I think it would be a fun side project to try and synthesize a true “All-American Man” using text mining like this. (Side note, that exact sentence reminds me that in my Computational Linguistics class in undergrad, for our final project about half the class teamed up and scraped our professor’s Twitter account and made a bot that wrote Tweets like he did. It actually wasn’t all that bad!)
I think this could potentially be valuable in future applications of my research, but again, I think I need to really narrow down the demographics and amount of data I feed Voyant. I’m going to keep working with this, and maybe also try Google Ngram Viewer.

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.