For my first foray into Voyant, I decided to take a look at a guilty pleasure of mine: the scathing book review. I know I’m not the only one who likes reading a sharp, uncompromising take on a book. Reviews along the lines of Lauren Oyler’s excoriation of Jia Tolentino’s debut essay collection go viral semi-regularly; indeed, when Oyler herself wrote a novel, some critics were ready to add to the genre. (“It’s a book I’d expect her to flambé, had she not written it.”)
I was curious if these reviews differed from less passionate (and less negative) reviews in any way that would show up in text mining.
Initial Process
To investigate, I assembled two corpora: a small set of scathing reviews, and a small set of mildly positive ones. The parameters:
Each corpus included 5 reviews.
I drew the reviews from Literary Hub’s Bookmarks site, which aggregates book reviews from notable publications. Bookmarks categorizes reviews as “pan,” “mixed,” “positive,” and “rave.” I drew the “scathing” corpus from reviews tagged as pans, and the control set from positive reviews.
I used the same 5 reviewers for both sets. (This was tricky, since some of the reviewers I initially chose tended to only review books that they either truly hated or — more rarely — unequivocally loved. Call this “the hater factor.”)
I only selected books I haven’t read yet — unintentional at first, but I decided to keep with it once I noticed the pattern.
I tried to select only reviews of books that fell under the umbrella of “literary fiction,” (though what that means, if anything, is a debate in itself) though American Dirt is arguably not a great fit there (but was reviewed so scathingly in so many places, I couldn’t bear to leave it out — maybe call this “the hater’s compromise”).
I specifically stayed away from memoir/essays/nonfiction, since those are so often critiqued on political, moral, or fact-based grounds, which I didn’t want to mix with literary reviews (but if this post has made you hungry for some takedowns along these lines, the Bookmarks Most Scathing Book Reviews of 2020 list contains memoirs by Michael Cohen, John Bolton, and Woody Allen — you’re welcome).
Voyant was pretty easy to get started with — but I quickly realized how much more I’ll need to know in order to really get something out of it.
I created my corpora by pasting the review URLs into two Voyant tabs. My first observation: an out-of-the-box word cloud or word frequency list, perhaps especially for a small corpus of short texts like mine, is going to contain a lot of words that tell you nothing about the content or sentiment.
I read Voyant’s guide to stopwords, then attempted to eliminate the most obvious unhelpful words, including:
Author names (Yanagihara, Franzen) and parts of book or review titles (Paradise, Detransition) – these would have been way less significant if I’d started with a large corpus
Words scraped from the host websites, rather than review text (email, share, review, account)
Words with no sentiment attached to them (it’s, book, read)
If I were doing this as part of a bigger project, I’d look for lists of stopwords, or do more investigation into tools (within or beyond Voyant) related to sentiment analysis, which would fit better with what I was hoping to learn.
Even with my stopword lists, I didn’t see much difference between the two corpora. However, when I compared the two corpora by adding the Comparison column to my Terms grid on one of them, I did start to see some small but interesting differences — more on that below.
What I learned
Frankly, not much about these reviews — I’ll get to that in a second — but a little more about Voyant and the amount of effort it takes to learn something significant from text mining.
Some things I would do differently again next time:
Add much more data to each corpus. I knew five article-length items wasn’t much text, but I hadn’t fully realized how little I’d be able to get from corpora this small.
Set aside more time to research Voyant’s options or tools, both before and after uploading my corpora.
Create stopword lists and save them separately. Who would have guessed that my stopwords would vanish on later visits to my corpus? Not me, until now.
Use what I’ve learned to refine my goals/questions, and pose questions within each corpus (rather than just comparing them). Even with this brief foray into Voyant, I was able to come up with more specific questions, like: Are scathing reviews more alike or unlike each other than other types of reviews? (i.e., could Tolstoy’s aphorism about happy and unhappy families be applied to positive and negative reviews?) I think having a better understanding the scathing corpus on its own would help me come up with more thoughtful ways to compare it against other reviews.
Very minor takeaways about scathing book reviews
As I mentioned, I did gain some insight into the book reviews I chose to analyze. However, I want to point out that none of what I noticed is particularly novel. It was helpful to have read Maria Sachiko Cecire’s essay in the Data Sitters Club project, “The Truth About Digital Humanities Collaborations (and Textual Variants).” When Cecire’s colleagues are excited to “discover” an aspect of kid lit publishing that all scholars (and most observers) of the field already know, she points out that their discovery isn’t a discovery at all, and notes:
“To me, presenting these differences as a major finding seemed like we’d be recreating exactly the kind of blind spot that people have criticized digital humanities projects for: claiming something that’s already known in the field as exciting new knowledge just because it’s been found digitally.”
So here’s my caveat: nothing that I found was revelatory. Even as a non-expert in popular literary criticism, the insights I gained seemed like something I could have gotten from a close read just as easily as from a distant one.
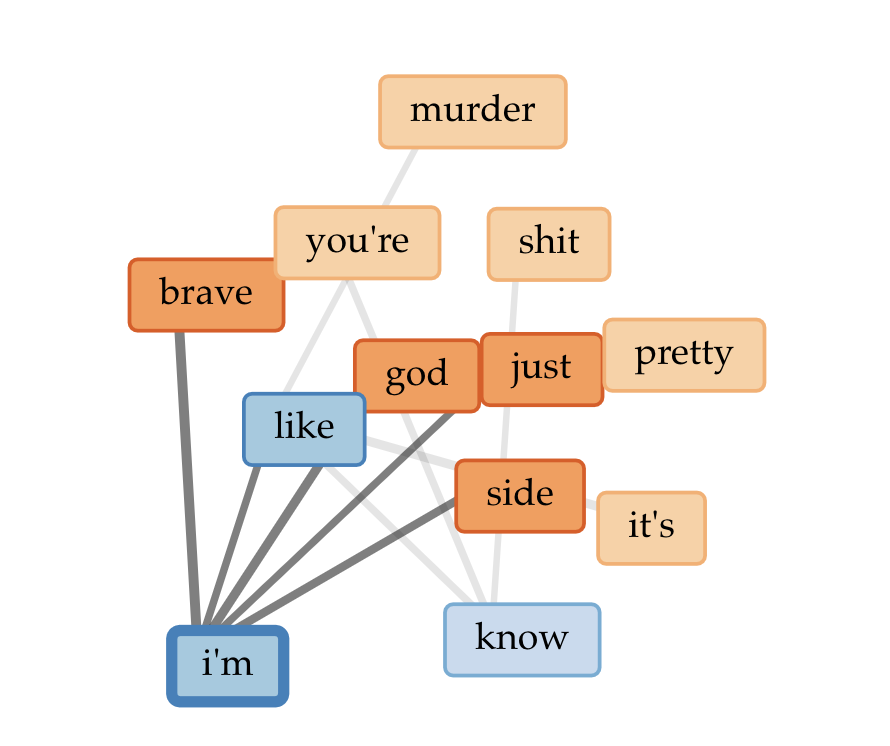
The main thing I really found interesting — and potentially a thread to tug on — came from comparing word frequency in the two corpora. There weren’t any huge differences, but a few caught my eye.
The word “bad” appeared with a comparative frequency of +0.0060 in the “scathing” corpus, compared to the “positive” corpus. When I used the contexts tool to see how they occurred, I saw that all but one of the “scathing” uses of bad came from Christian Lorentzen and Lauren Oyler’s reviews. Neither reviewer used the word to refer to the quality of the text they’re reviewing (e.g., “bad writing”). Instead, “bad” was used as a way to paraphrase the authors’ moral framing of their characters’ actions. For Lorentzen, Salley Rooney’s Beautiful World, Where Are You includes “…a relentless keeping score… not only of who is a ‘normal’ person, but of who is a ‘good’ or ‘bad’ or ‘nice’ or ‘evil’ person.” Oyler uses the word to discuss Kristen Roupenian’s focus on stories that feature “bad sex” and “bad” endings. That literary reviewers pan something for being didactic, or moralistic, or too obvious is nothing surprising, but it’s interesting to see it lightly quantified. I’d be interested to see if this trend would carry out with a larger corpus, as well as how it would change over time with literary trends toward or against “morals” in literature.
I found something similar, but weaker, with “power” — both Oyler and Ryan Ruby (panning a Jonathan Franzen novel) characterize their authors’ attempts to capture power dynamics as a bit of shallow didacticism, but the word doesn’t show up at all in the positive corpus.
Words like “personality” and “motivation” only show up in the negative critiques. It’s also unsurprising that a pan might focus more on how well or poorly an author deals with the mechanics of storytelling and character than a positive review, where it’s a given that the author knows how to handle those things.
Even “character” shows up more often in the scathing corpus, which surprised me a bit, since it’s a presumably neutral and useful way to discuss the principals in a novel. To add further (weak!) evidence to the idea that mechanics are less important in a positive review, even when “character” does turn up in an otherwise positive review, it was more likely to be mentioned in a critical context. For example, in Oyler’s overall positive review of Torrey Peters’ Detransition, Baby, she notes that “the situation Peters has constructed depends on the characters having a lot of tedious conversations, carefully explaining their perspectives to one another.” As with everything else, I would want to see if this still held in a larger corpus before making much of it. It’s very possible that the reviewers I chose are most concerned with what they find dull. From my other reading of her work, that certainly seems true of Oyler.
To test these observations further, I’d need to build a bigger corpus, and maybe even a more diverse set of copora. For example, if I were to scrape scathing reviews from Goodreads — which is much more democratic than, say, the London Review of Books — what would I find? My initial suspicion is that Goodreads reviewers have somewhat different concerns than professional reviewers. A glance at the one-star reviews of Beautiful World, Where Are You seems to bear this out, though it’s interesting to note that discussion of character and other mechanics shows up here, too:
This would be a fun project to explore further, and I could see doing it with professional vs. popular reviews on other subjects, like restaurant reviews. Fellow review lovers (or maybe “review-loving haters”?), let me know if you’re interested in poking into this a bit more.
For this praxis assignment, I struggled at first with deciding what texts I wanted to explore. I wanted to explore which corpora were publicly available, in hopes of using an existing corpus instead of building my own. However, I ended up making my own corpora in realizing that I couldn’t force myself to be interested in the existing free-to-the-public corpora I had seen. Though I’m sure there must be something out there that speaks to my interests, I had a tough time effectively searching for resources on my own as a novice to text mining. Despite the fact that building my own corpus would require more work, it was a fun exercise that made the experience more rewarding.
I use Voyant in hopes of gaining some insights regarding themes within Frank Ocean’s Blond/e and Channel Orange albums. These albums are personally some of my favorites of all time. I was interested in seeing what insights Voyant could provide for the “bigger picture” between (and among) the lyrics on each album, especially in comparison to my subjective experience of listening to these albums.
My first instinct was to try and figure out how I would be retrieving the lyrics for Frank Ocean’s songs. I figured I could use an API to pull song lyric information. I was planning to use Genius, but their API focuses more on the annotations, and not necessarily the lyrics themselves. So, I manually copied and pasted the lyrics to all his songs on both albums into .txt files within separate folders representing the albums instead. Initially, I was planning to just pass each album in separately to Voyant. I wanted to explore how Frank Ocean’s lyrics changed from Channel Orange (2012) to Blond/e (2016), especially with regards to his queerness (which I’ve personally felt has been greater explored in his later music in Blond/e, but is definitely subtly present within Channel Orange). But after reflecting more on the insights I was hoping to gain, I decided to pass all the songs from both albums combined, in order to see what themes may have overlapped in the context of one another. Additionally, I passed two separate parts of the Blond/e album split in half. The album Blond/e is actually split into two separate parts – the album is exactly one hour, with the transition in “Nights” occurring at the 30 minute mark, directly splitting it in half.. Hence, there are two spellings of the album; the album cover art says “blond” while the album title is listed as Blonde. Duality is a major theme explored in Blond/e, with regards to the album branding, the song lyrics, and the musical composition. I think the duality themes present could be interpreted in reference to Frank Ocean’s bisexuality!
After passing 5 different corpora into Voyant, the resulting cirrus and link visualizations follow.
Channel Orange
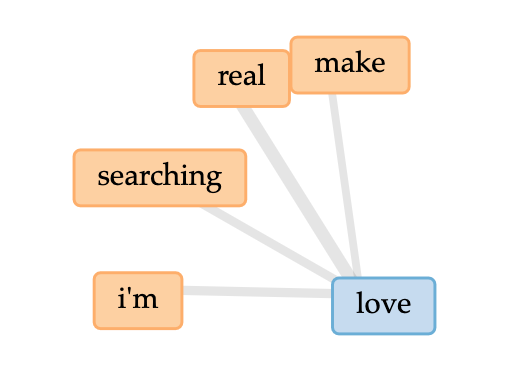
cirrusoverall word linkslink to word “love”
Some notes:
With regards to love, it seems as though Frank Ocean is looking to make something real happen
In the cirrus, I come to understand Channel Orange to be about thinking and looking for real love, and being lost in the process.
Blond/e
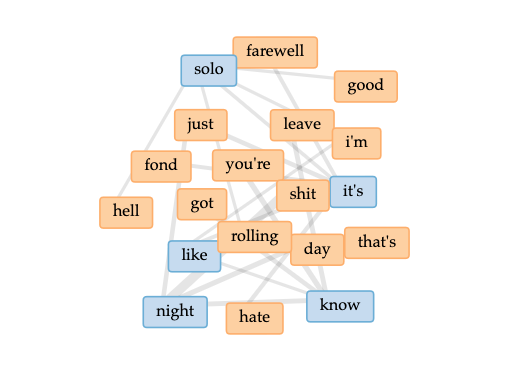
overall word linkslinks to words “solo” and “night”cirrus
Some notes:
Blond/e appears to be on his own, and learning to navigate that
In the cirrus, I come to understand Channel Orange to be about thinking and looking for real love, and being lost in the process.
As a whole, Blond/e could be interpreted as a farewell to a past fond lover, and trying to make it through the days (and nights)
Blond/e Part I
cirrusoverall word links
A note:
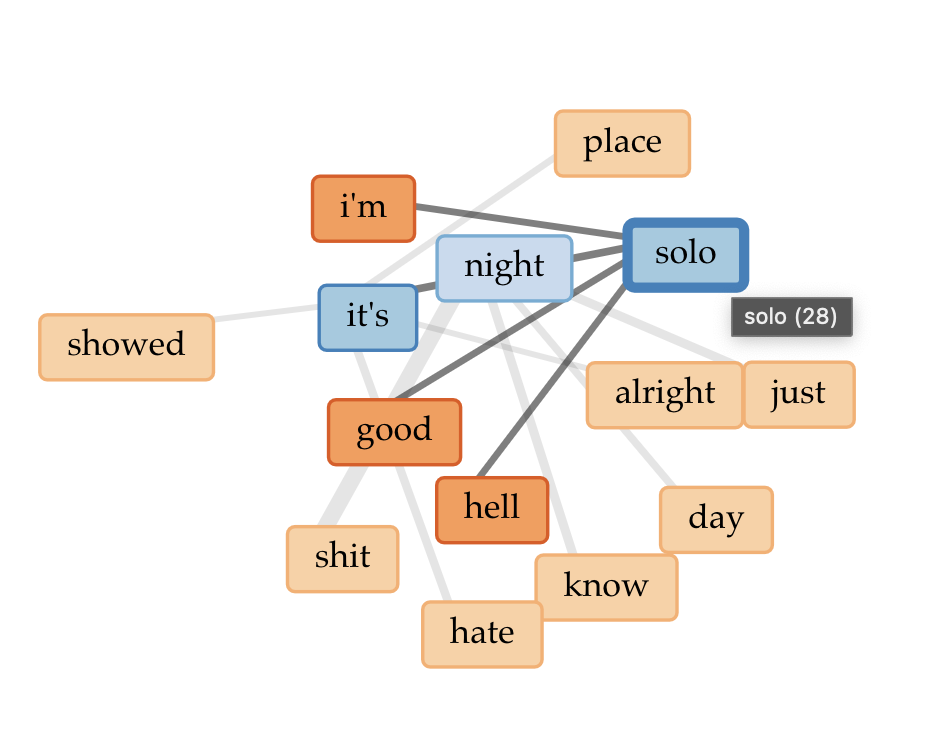
In the first part of Blond/e, there tends to be more words regarding struggle, such as solo, night, hell, leave, etc., as well as reference to marijuana to likely cope with heartbreak.
Blond/e Part II
cirrusoverall word links
Some notes:
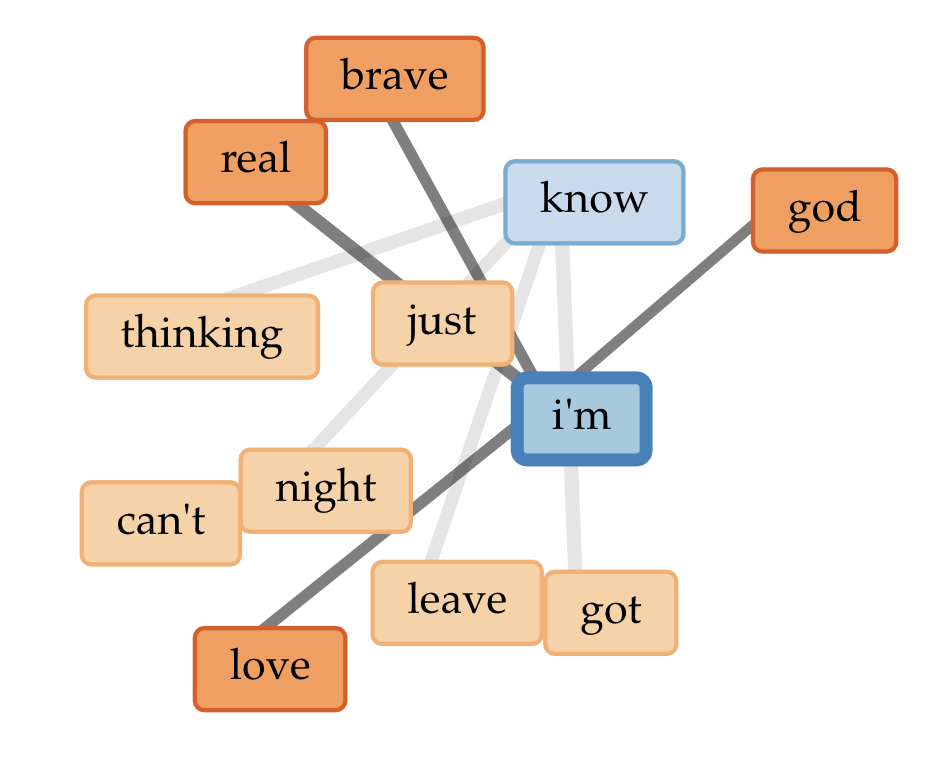
In the second part of Blond/e, there is more references to day (which ties back in to my original statement about the two album parts representing duality)
In the overall word links, there are also links to Frank being “brave” and thinking about “god” – knowing the album myself, I interpret references to god to deal with learning to let go (hence his song “Godspeed”)
Channel Orange + Blond/e
cirrusword links
Some notes:
Overall when combining the two albums, there seems to be prevalent references to love, god, and night/day.
Overall, playing around with Voyant was a fun experience. I hope to explore more, especially with regards to music analysis. I’m wondering if there’s similar analysis tools that can incorporate mining both text AND audio on bigger scales (though I know with audio files, it’s more difficult due to data constraints potentially). I wish I had more time to analyze the visualizations, and to dig deeper into formulating some insights that align (or contradict!) with my own personal close listening.
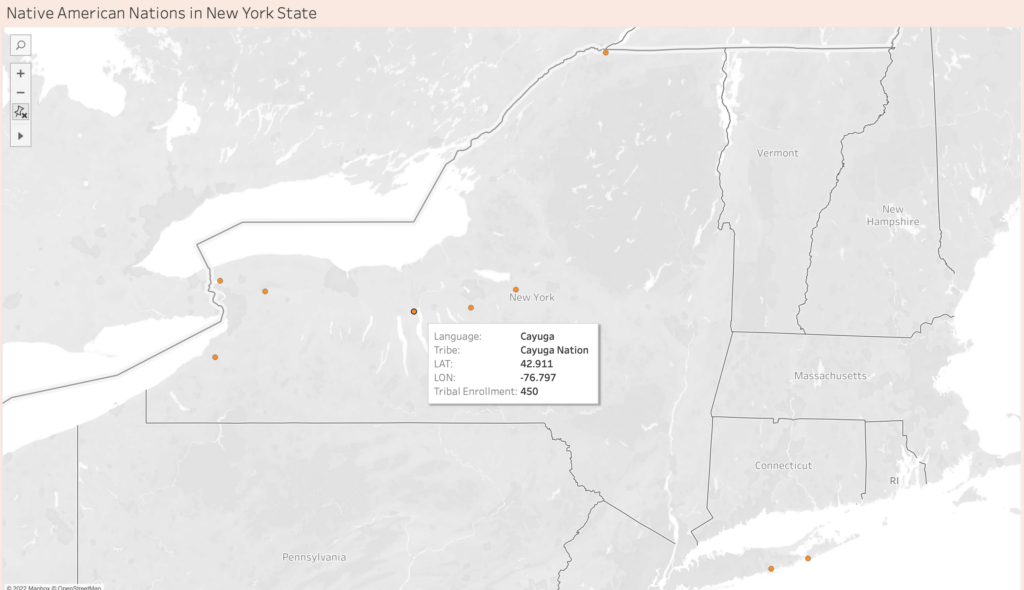
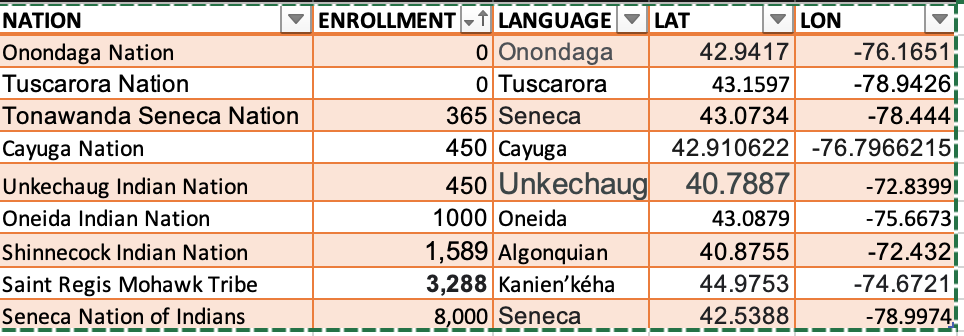
State and Federally Recognized Native American Nations in NYS
About this Map:
This map represents the nine state and federally recognized Native American Nations in New York State. On this map, I also include the language they speak and the total enrollment number for each tribe. The Tribal Enrollment Number was based on the tribe’s websites.
In recent years, I’ve been interested in learning about my roots and ancestor. When I received my DNA results from Ancestry DNA, I was excited to learn where my bloodline came from. I always knew I had indigenous DNA since I was born in Nezahualcoyotl, Mexico. However, when I read that I had 68% Native American DNA from Central Mexico and 1% Indigenous Americas—Panama & Costa Rica, I felt a new sense of pride and identity. In my family, we never spoke about being indigenous or Native American. However, we embraced our culture and heritage. In the same sense, I felt I had the duty and curiosity to learn more about the Native Americans living in New York State and the Americas.
I could not get the total enrollment for Onondaga Nation and Tuscarora Nations since it was not on their website.
I did not know how to read the My Tribal Area website (United States Census Bureau), since the population included people not enrolled in the tribe. Based on the articles above, I don’t know if I can trust this website to represent tribal information.
Lack of time to learn Tableau
Data
Data table
My Questions
Who decides that a Native American Nation is recognized (state and federally)?
Why is there limited information on Tribal Enrollment?
Why are some Nations hesitant to partake in the Census?
What other Nations are in NYS that are not state or federally recognized?
I created a map (demo) based on a travelogue written by a Japanese courtier and poet Asukai Masaaki (1611–1679), about his journey to Yoshino, Nara, Japan, in the spring of 1654. The data of the map is taken from the text transcribed by me from a beautifully brushed and decorated manuscript, A Record of Yoshino (Yoshino ki, mid-17th c.). This manuscript is about twenty-two pages long, and thirty-seven poems are recorded in the version I use. I only chose two or three of them to do a demo for this assignment and hope that I can build a template/layout design for future use. I created a public account in ArcGIS Online for this assignment, so there are not many customizing capabilities available.
I chose ArcGIS Online and ArcGIS StoryMaps to create this demo.
As Olivia Ildefonso explains in “Finding the Right Tools for Mapping,” ArcGIS creates high-resolution maps but is very expensive if you want to buy the full version. I had experiences, though very limited, of using the student account (the full version ArcGIS) in the past and thus did some comparisons this time.
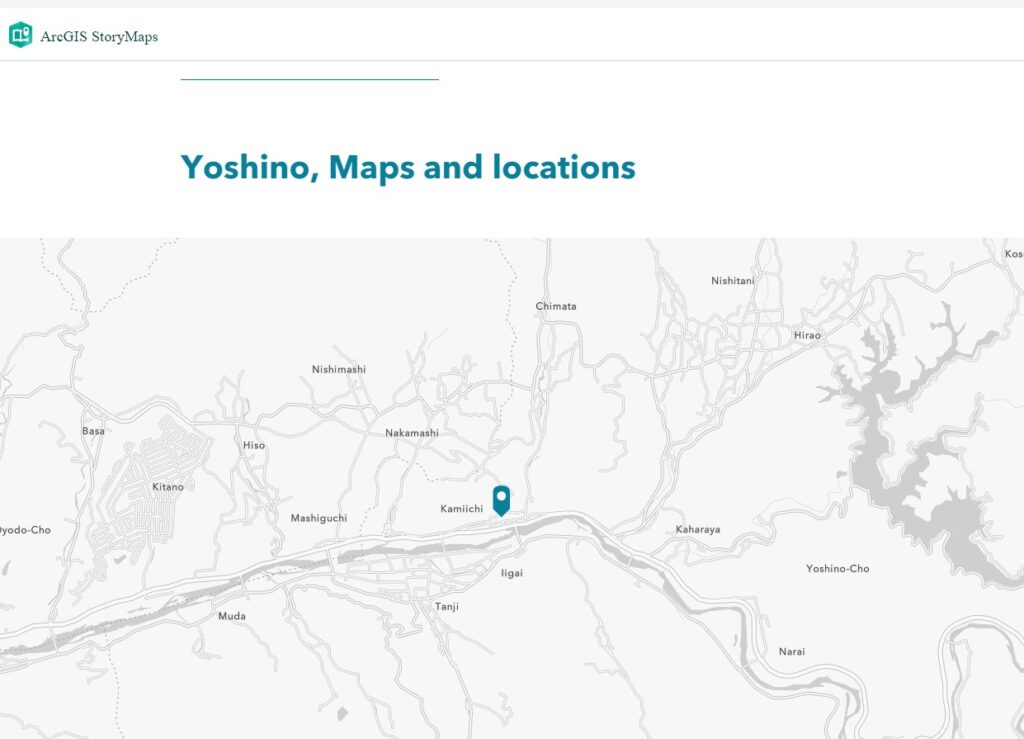
The locations in this travelogue are all local spots that are very difficult to search and identity using the searching function in ArcGIS Online. Then I tried the “Express map” feature in the StoryMap, but I could only find “Yoshino, Nara,” as shown in the image below (Figure 1).
Figure 1
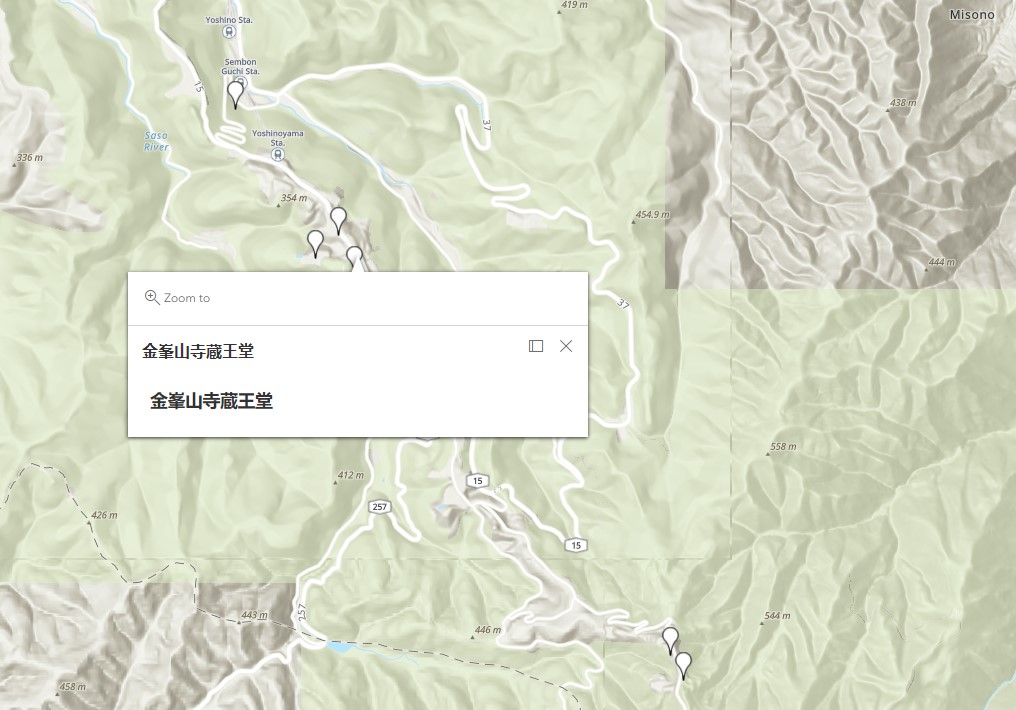
I was instead looking for another way to create a customized map that could show details of local sites. I made a map in Google Maps (location names in Japanese are available), downloaded its KML, and uploaded the KML file as content to my ArcGIS account. It works perfectly, as shown below (Figure 2).
Figure 2
I didn’t notice the limitations of adding non-Western spots in ArcGIS maps before trying it. As Sen writes in “Dividing Lines,” “for those of us whose corners of the world are considered ‘remote’ or ‘uncharted’ from an essentialist white, Western perspective, the interface is far from seamless.”
We do not know whether the 37 poems in the manuscript are in chronological order. It is possible that the poet wrote poems one by one during his journey, but it is also possible that he took notes and went back home to finish the work. So, I did not mark a direction on the map but only provided spots he visited. In the StoryMaps where I can add more interactive features (e.g. Map tour), I thought it would be easier for viewers to navigate if I have an order, so I just did a demo following the poem order. But it would be an excellent question to consider the sense of time and geographical distance presented by textual materials in premodern times when we design an interactive digital map in which modern readers could explore the locations via a historical figure’s mind (or maybe also via the designer’s mind). This question is an idea that I can relate to Monmonier’s book How to Lie with Maps. Besides scales and symbols, directions and order of locations could also lie to us. Or if we use new orders as an interpretation of the original text, would it be an issue?
I played with features like “Express maps,” “Slide,” and “Sidecar” in StoryMaps and thought these are great tools to create past-present comparisons and literary maps (content + geographical info). “Slide” is very interesting in that it allows two images to be overlaid and one can swipe back and forth. (Figure 3)
Figure 3
However, since the account I used this time is public, many features are unavailable. For example, sometimes, I could not change the font/size of the text. Also, it was impossible to build a bilingual StoryMap in the past, but I successfully inserted Japanese text into my StoryMap this time. However, if I wanted to try further, I still couldn’t do the vertical direction for the Japanese poems. (Figure 4)
Figure 4
Last, both the map and StoryMap could be shared by URLs. But the group function (members in the group could collaboratively work on one project) in StoryMap is not very user friendly. If I use a school account, it seems easy to find partners in my school and share a work-in-progress privately. But I see obstacles in sharing your project with members outside your school. On YouTube, you could upload a video as “unlist (more sharable than private),” but I haven’t found a level between “private” and “public” in StoryMaps, which makes teaching using StoryMaps in the classroom a bit challenging due to copyright concerns.
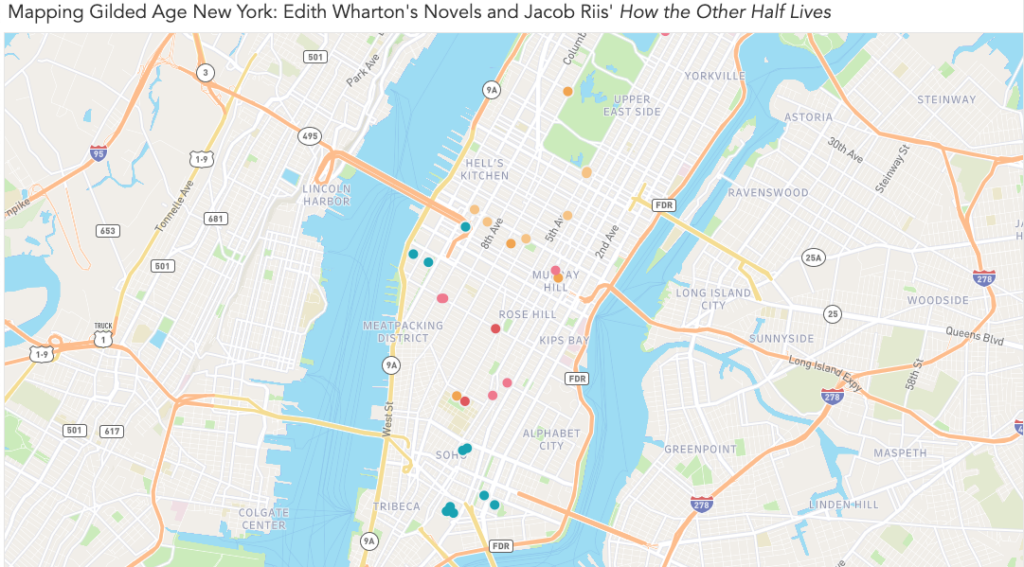
This week, I attempted to map the works of two chroniclers of Gilded Age New York: Edith Wharton and Jacob Riis. Both offered clear-eyed critiques of the city and its people, and together they represent the duality inherent to the idea of a Gilded Age. Wharton’s novels describe the thin ornamental gilding that conceals the truth about a society; Riis’ journalism and photography deal with with what’s rotten underneath. Wharton’s critique is cultural and relatively narrow: the shallowness of the rich and the rigidity and provincialism of their customs and mores. By contrast, Riis’ critique is material, and his focus on the indigent is an indictment of the wider social and economic structures of late 19th century New York.
To create my map, I chose to use Tableau. You can see a draft of it here, on Tableau Public, as well as in the screenshots below.
View of the entire map. Locations from Riis’ How the Other Half Lives are in teal, while Wharton’s novels are represented by various warm shades.Each marker expands into a note that contains information about the author, source, and location, as well as an excerpt from the relevant text and interpretive notes. In the notes, I attempted to give context about the source material and explain my methodology for determining the location.
Goals and Inspiration
I chose to map Wharton and Riis after a visit to the Tenement Museum last month. I’ve read three novels by Wharton in the past year, and while I’ve always been moved by the photography of Jacob Riis, I hadn’t consciously connected their work until paging through a copy of How the Other Half Lives while waiting for my tour.
The title alone is pointed, and I couldn’t help but think of Riis directing it toward New Yorkers who resemble Wharton’s characters. They possess such precise, detailed knowledge about the rules of their own limited world, yet show so little curiosity about what exists just out of sight. By mapping sites from Wharton’s novels and Riis’ journalism, I hoped to see just how closely these worlds were situated.
Mora (b. 1849). Mr. and Mrs. Cornelius Vanderbilt II (neé Alice Claypoole Gwynne). 1883. Museum of the City of New York. F2012.58.1341. https://www.mcny.org/story/vanderbilt-ball
I was particularly interested in spatially distinguishing the “genteel” poverty experienced by some of Wharton’s characters from the desperate circumstances Riis documented. For example, Wharton’s The House of Mirth tells the story of Lily Bart’s gradual fall from “high society” to poverty and obscurity. When Lily, finally broke, moves to a boarding house and works in a small workshop making hats, just how far is she — economically, socially, and literally — from the immigrant garment makers in the tenements of the Lower East Side?
My initial plan was to overlay locations from Riis and Wharton with demographic information from the time, such as population density, income, family size, etc. I set out to see what had been already done — and quickly realized how ambitious my original goal was. A number of researchers have done great work with data from this era, including researchers at the time. (You can see my rough research notes, including links to sources, here.)
Through Village Preservation’s blog, I learned about the demographic maps created by the Tenement-House Committee in 1894. I’m including a small image below, but I encourage you to click through to the Library of Congress listing to see a full-sized image — these maps are incredible.
Pierce, F. E. The Tenement-House Committee maps. S.l.: Harper & Brothers, 1894 Map. https://www.loc.gov/item/2006629793/.
What strikes me is that these map-makers were doing something we were challenged to do this week — map something that isn’t normally considered mappable. While demographics maps are common today, the crazy-quilt appearance of the lower map (showing various immigrant populations in New York) shows how ambitious a task this was at the time. The map is difficult to read at first glance, at least to my eye — our mapping conventions have evolved over time, to the point where I have built-in expectations about how a map like this “should” look. The idiom of the upper map is more familiar to me; even before studying the key, I was able to make assumptions about what it shows.
A more recent — and equally visionary — look at the same data is Columbia University’s “digital atlas,” Mapping Historical New York. The team behind this project used census records to map out demographic data at the individual and building level. So far, their data set includes records from 1850, 1880, and 1910. For each of these, you can view information related to nationality, gender, race, occupation, and age, as well as basic population density information. You can zoom out to view larger patterns, but since the map points represent individual records, you can zoom in on a block and see what types of jobs the people living there had, where they were born, and more.
Gergely Baics, Wright Kennedy, Rebecca Kobrin, Laura Kurgan, Leah Meisterlin, Dan Miller, Mae Ngai. Mapping Historical New York: A Digital Atlas. New York, NY: Columbia University. 2021.
The project includes case studies that use specific locations on the map to present a story — something I would eventually love to do with my data. However, given the complex work that’s already been done with demographics, I chose to limit my focus for this first draft to plotting locations from Wharton’s novels and Riis’ How the Other Half Lives.
Gathering Data: Challenges and Methodology
I started by reading everything I could find about locations in Wharton’s novels. Given her enduring popularity, as well as the prominence of real estate in her work, I thought that finding rough locations for many of her characters’ homes would take a Google search or two. I was wrong, of course. While you can book an Edith Wharton walking tour, these tours are mainly focused on the events of Wharton’s life and general Gilded Age sites, rather than locations in her novels. It was easy to find writing that touched on the significance of place in her work, from the hotel where Undine Spragg stays in an attempt to get “in” with high society, to Ellen Olenska’s idiosyncratic flat in a neighborhood her critics consider beneath them . But finding more detail about possible locations than is offered in the books themselves? Not easy. (Except in a few cases, which are noted in my map.)
This is where I felt my own limitations as a humanist. While I took a handful of courses in both, my undergraduate degree wasn’t in history or literature — they’re subjects I’ve continued to study in the decade and a half since I graduated, but not with academic rigor or backing. I didn’t find what I was looking for in academic databases, but I can’t say for certain that the information wasn’t there. With both the literary and historical aspects of this research, I couldn’t be certain I was asking the right questions, so I had to use a simple method of finding the answers I wanted: I went through each of my source books.
I worked with three of Wharton’s novels, each of which I’ve read within the past year:
I started by making a list of the specific locations I was hoping to find in each, as well as search terms within the novels that I thought might lead to other discoveries (e.g., “avenue,” “street,” “corner,” “house,” “home”). Since all three novels are in the public domain and available on Project Gutenberg, I was able to use ctrl+F to highlight the terms and scroll through the results. (This is a task I would like to explore again once I know more about text mining.) I started collecting my data in a spreadsheet, including:
A brief description of the locations I found
Textual evidence of the actual location. This ranged from:
Vague evidence, like “far west of Sixth Avenue” (Lily Bart’s boarding house in The House of Mirth), to
Highly specific details, like the ones that place Lawrence Selden’s bachelor apartment in the same book at 50th Between Fifth and Madison.
A relevant excerpt from the book
I did the same for Jacob Riis’s words and photos, using two sources:
Once I had my basic data, I started working to pinpoint precise locations for each place. This was fairly straightforward for Riis’ work, as he was a journalist by trade. For most of his photos and descriptions, I was able to use details in the text to easily estimate the location within a block or two.
Wharton presented a number of challenges. Most obviously, her work is fiction — so I didn’t expect an exact concurrence between her work and the New York City map. However, a few of her idiosyncrasies made my job harder:
Wharton only rarely used real places (the Academy of Music, the Metropolitan Museum of Art), but she often used buildings that are meant to be stand-ins for other, well-known buildings. For example, Undine Spragg’s hotel in The Custom of the Country is called the Stentorian. Since Wharton provides the cross streets, I know that it’s a stand-in for a real hotel called the Majestic — and her readers probably would have known that too, and understood that she was using that detail to further color Undine’s character. I have the strong suspicion that many of her other locations — especially the most ostentatious mansions — are nods at specific buildings, as well. Contemporary readers would be able to pick up these cues (and so might experts on the history of New York architecture), but it wasn’t something I could figure out in the ten hours or so I spent collecting this data.
While each of these novels is set in New York City, Wharton mainly wrote them while living in Lenox, Massachusetts. Even when she provides an exact address, it’s not clear that one should really expect that address to be accurate. For example, in The House of Mirth, Wharton provides us the exact cross streets for Lawrence Selden’s apartment building, “The Benedick.” (Another fictional but very likely-sounding location!) When Lily Bart visits, she notices every detail about her potential beau’s block — except for the fact that it contains St. Patrick’s Cathedral, if it is where Wharton says it is.
Wharton’s impressionistic mapping extended to relative locations, as well. For a while, I thought I could be clever and map the posh Fifth Avenue homes in The House of Mirth based on the movements of the characters who visit these homes. For example, characters are often described walking north or south from one house to another. I began to plot these home on a straight line — but eventually figured out Wharton had not done the same. My plan was foiled when I realized that a particular house was listed as both north and south of its neighbor.
When I reached the limits of what the text could offer, my next step was to consult other sources. The one I used the most was Mapping Historical New York. When Wharton’s text offered me a general area, I used the demographics maps, as well as other historical sources, to come up with a likely location.
For example, one of the places I was most interested in locating was Lily Bart’s boarding housein The House of Mirth. This is a significant location because of what it represents: Lily’s fall into poverty after she accrues an overwhelming amount of debt and makes “bad” social choices. The boarding house is where Lily goes to live when she decides to stop accepting acquaintances’ charity; it’s also where she dies from an ambiguous overdose. When the other characters see Lily’s living situation, they are shocked and even disgusted. Here’s one reaction:
As she led the way westward past a long line of areas which, through the distortion of their paintless rails, revealed with increasing candour the disjecta membra of bygone dinners, Lily felt that Rosedale was taking contemptuous note of the neighbourhood; and before the doorstep at which she finally paused he looked up with an air of incredulous disgust.
“This isn’t the place? Some one told me you were living with Miss Farish.”
“No: I am boarding here. I have lived too long on my friends.” He continued to scan the blistered brown stone front, the windows draped with discoloured lace, and the Pompeian decoration of the muddy vestibule; then he looked back at her face and said with a visible effort: “You’ll let me come and see you some day?””
The House of Mirth, Chapter 10
Given the intensity of Rosedale’s reaction, I was extremely curious about where Lily might have lived — and how it would have compared to the living conditions of immigrants in the tenements. Fortunately, this same section of the novel offered key clues to the location. To put everything together, I consulted Mapping Historical New York, as well as information about the elevated rail line that existed at the time. I describe the process in a note on my map:
I was able to make an educated guess about the location of Lily’s apartment (as well as her chemist — see other note) based on the face that she walks there with Rosedale after meeting him as he descends from the 6th Avenue train. Based on other context, the only el stops that fit are 23rd St., 33rd St., 42nd St., or 50th St. (Others opened after the novel was written.)
Knowing that Wharton was born on 23rd and chooses to make far West 23rd the home of Madame Olenska’s artistic neighborhood in “The Age of Innocence,” I believe we can eliminate the possibility of Lily living on or near 23rd.
Demographics maps show that 50th was less densely populated further to the west, which makes it an unlikely location for a shabby boarding house. 42nd and 33rd were both dense — but given the landmarks near 42nd, and the fact that it’s closer to Bryant Park, which has been mentioned before as a place where Lily stops at this point in her life, I believe that 42nd is the most likely spot for her to run into Rosedale.
According to “Mapping Historical New York,” this block [W. 42nd between 9th and 10th] is the first one on 42nd west of 6th that has a significant number of garment workers living there in 1880; it and the blocks directly south are very densely populated, compared to the blocks to the east. 42nd St. has a large population of immigrants at that time, but from various backgrounds, whereas the streets to the south are predominantly German — something I think would have been noted if Wharton had intended it to be the case about Lily’s street.
(Interestingly, this location for Lily’s boarding house puts her only a few blocks north of one of the Jacob Riis locations in Hell’s Kitchen — but based on demographics at the time, that was a meaningful distance. The location suggests that while Lily was poor, she was still in not nearly as dire straits as the New Yorkers who lived in the tenements to the south.)
My process wasn’t quite as intense in each case, but I did try to reach this level of certainty for all my data. For this draft of the map, I eliminated locations that I couldn’t pin down within a few blocks. Once I had identified the locations that would make the final cut, I revisited the whole list on Google Maps to determine the latitude and longitude for each. You can view a copy of my dataset (as of 9/20/22) here.
Building the Map
Once I had my data, I chose to build my map in Tableau. As others have stated in their posts, it’s free for students and offers a robust toolset. I found it easy to learn, but I hit a few stumbling blocks that kept me from the vision I would ultimately like to execute.
Custom Map Image
I had originally planned to plot my coordinates on this 1879 map of New York, which I used to narrow down a few of my locations:
However, from a practical point of view, this map has a few problems. First, the perspective is skewed. The map doesn’t show a true bird’s-eye view, like we would expect from a modern map. When I attempted to overlay this image with Google Maps, I could get the contours of the Battery to match up, but Central Park wasn’t even close.
My second issue was that I didn’t trust the accuracy of the map beyond Manhattan, which would have been essential for providing the bounding latitude and longitude to map on Tableau.
I think both these issues can be resolved — but not in a couple of evenings.
Tooltip Images
I’d originally planned to include Riis’ images as part of the tooltips for my labels; each of the points I mapped has an image associated with it.
“Children’s Playground in Poverty Gap.” 1892. Located on W. 28th between 11th and 12th.
Tableau doesn’t currently offer a built-in way to do this. Many users employ an elaborate workaround — which I will attempt in my next draft — but this seems like a real gap, as well as a barrier for Digital Humanists, students, and others, especially if the workaround solution is not scalable or easy to keep updated with new data sources.
Reflections and Next Steps
My first attempt at this project was somewhat successful — I can see the limits of my own skills, both in the humanities and in the tools I used, but I also was able to answer some of the questions I started with.
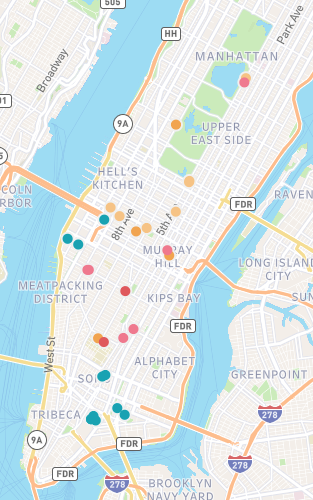
My map, with nearly all points visible. The warm colors represent locations drawn from Wharton’s novels and life, while the teal markers represent locations documented by Riis. The locations in Wharton’s work that come closest to intersecting with “the other half” are Lily Bart’s shabby boarding house (westernmost yellow marker in Hell’s Kitchen) and Ellen Olenska’s apartment in a neighborhood that we could now refer to as “gentrifying.” (One of two pink markers nestled closely together north of the Meatpacking District.) Also note how spread out the world of Wharton’s characters is compared to the densely packed New York of Riis’ tenement dwellers.
Plotting out the locations in Wharton’s and Riis’ work did give me a better sense about how the worlds they described coexisted, with Riis’ workers providing so much of the labor that Wharton’s characters would choose not to see. I was especially interested in seeing the clear lines drawn between Wharton’s “genteel poor” and the real-life tenement dwellers; even when they approach each other on the map, they don’t quite overlap.
However, the most valuable aspect of the project was the chance it gave me to reflect on larger questions, including ones we’ve touched on in class.
Namely:
How might DH tools like mapping unintentionally obfuscate the uncertainty within some works of scholarship? I know that I’ll probably end up revising some of my locations as I learn more about Gilded Age New York, and I did my best to “show my work” and be honest about how tenuous some of my conclusions are. But if this lives publicly on the web, will my caveats get lost as other people find and use my work? For example, how many walking tours would have to include my educated guess about Lily Bart’s boarding house for the location to become an established fact? Our readings this week addressed the idea of maps seeming to create truth — when Digital Humanities projects use these tools, do we run the risk of being more convincing than we intend to?
Who and what am I leaving out by focusing on Riis and Wharton, and how does this reinforce existing narratives and gaps? The whiteness of the people (fictional and real) I highlighted in this project doesn’t reflect New York today — it doesn’t even reflect Gilded Age New York. I became especially conscious of how limited my data set is when I asked my husband, who’s a historian of the Great Migration and Black urban politics, to give me a gut check on some of my methodology as I checked for information on Mapping Historical New York. Instead of answering my question, he got caught up on looking at the demographics of an area just southeast of Columbus Circle and launched into a story about how Booker T. Washington nearly got beaten up there — and how of course that made sense, given the historical context of the area. That’s a story my map wouldn’t capture, along with many others. As I expand this project, I need to add additional sources, lest I give viewers the impression that the stories I’ve chosen are representative of that era of New York as a whole.
How do our tools limit what we choose to do as humanists? When I chose to leave certain elements, like Riis’ photos, out of this draft because it was too complicated to attempt in the moment, I compromised the integrity of my original goal. I have no doubt the project would be richer with the photos included. I believe I’ll be able to include them in my next draft, but this makes me reflect on some of the debate about defining Digital Humanities and Digital Humanists — namely the perceived distance between “thinkers” and “makers.” I have more sympathy for the argument that Digital Humanists must be makers than I did before this project, though I’m not fully convinced. If those who don’t have the skills to make projects choose to rely on out-of-the-box tools that impose limits on their projects, are they just restricting their own work? Or can we aggregate all of the DH work that doesn’t get made (or executed to the fullest extent) for want of a good tool and see it as detrimental to the field as a whole?
How might these tools limit the information available to the public? If data gets left out because it’s not easily displayed, can we expect people who engage with our work to know that data exists? What assumptions might be made based on a lack of data?
I’m curious to hear others’ thoughts and critiques as I continue working on this, especially as I continue grappling with these questions.
[Updated 9/21/22 ~ 10:00 AM to add additional sources, including my dataset, and make some edits for clarity and style.]
Forensic Architecture is a research agency based out of London that combines architectural digital technologies with investigative techniques to piece together evidence and ultimately craft visual archives of state violence that otherwise would not exist. The term forensic architecture refers to the emerging academic field at Goldsmiths, University of London that “produces and presents architectural evidence within legal and political processes.” I first became aware of Forensic Architecture’s work at the Whitney Biennial in 2019, and they are ultimately the spark for my interest in digital humanities. While Forensic Architecture does not necessarily identify themselves as a digital humanities collective, I believe that the work they do constitutes digital humanities with an explicit basis in critical theory. That is to say, Forensic Architecture employs digitals tools with the purpose of documenting historical oppression that lacks other “traditional” forms of documentation (such as writing, images, news, videos, etc) in an effort to question what knowledge is by exposing the gaps in what we “know” about human rights violations, and repositioning power by focusing on and working with structurally oppressed communities to effectively document their history.
In the investigative project “Dispossession and The Memory of the Earth: Land Dispossession in Nueva Colonia” commissioned by The Commission for the Clarification of Truth, Coexistence and Non-Repetition of Colombia, Forensic Architecture collaborates with Instituto Popular de Capacitación (a Colombian government organization that carries out research, training and education, and more with communities, social and political movements, media, as well as with the State in its different territorial scales) and Forjando Futuros (a Colombian non-profit that provides legal representation for victims of land dispossession due to armed conflict) to show the dispossession of campesino farmer land in the Urabá Antioqueño region of Nueva Colonia from the 1960s to present day through a web platform consisting of cluster visualizations and mapping technologies. According to their investigation site, methodologies include “3D modeling, data mining, fieldwork, photogrammetry, remote sensing, situated testimony, ground truth, [and] software development.”
In pursuing this project, the various teams of investigators ultimately expose the different actors involved in the land dispossession of Urubá for the purposes of “commercial monocrop banana cultivation,” and calls into focus the governmental forces that were meant to protect the campesinos from the brutal violence enacted both on the people and environment of Urabá. The web platform Despojo Urubá introduces historical context and identifies 12 different groups of actors. Clusters of circles representing land are color coded to reflect each of the 12 different groups and their respective land ownership. Starting in 1950 and depicted throughout time, these circles are shown to shift and move as land is dispossessed from the campesinos, and ownership transferred between different corporate entities. The platform also introduces an alternative view through the use of a map which shows in a more geographical context which parts of Urubá are being dispossessed, transferred, and bought over time, and by which actors. Beyond the web platform, Forensic Architecture created a video as an accompaniment to the web platform that delves into historical context, providing a situated testimony of massacres inflicted against the campesinos of Urubá through architectural modeling, aerial analysis, and testimony. The investigation is a powerful project that transforms the ways that users think about knowledge, history, and memory, revealing the ways we can practice, as Presner writes, “building a bridge… between the mapped and unmapped, the global and the local… reestablish[ing] contact with the non-philosophical” [Presner, 66].
Despojo Urubá allows users to understand the conflict, scale, and timeline of land dispossession in Urubá in a way that could easily get lost in translation in “traditional” written research projects. The investigative video component delivers extraordinary insights that are more accessible than papers typically are, and rooted in testimony that can be envisioned through the use of digital technologies. The use of clusters and maps were tools specifically chosen, and they serve distinct purposes in crafting the archive of land dispossession. There are immense strengths in this project in archiving and writing a history that oftentimes goes unwritten. The interactive nature of the web platform paired with the video allow for insights to be explored by users in meaningful ways.
While Forensic Architecture engaged with Colombians from a wide array of backgrounds in their investigation and practice critical theory intentionally, my biggest critique is their lack of job pipelines to support non-European scholars who are interested in working on and developing their own projects. How does Forensic Architecture ensure that their on-the-ground collaborators are being compensated for their labor on projects that deal with violence and trauma?
Overall, I highly recommend checking out Forensic Architecture’s “Dispossession and The Memory of the Earth: Land Dispossession in Nueva Colonia”, as well as their other 84 investigations. I believe that their investigative work reinvigorates us to think critically and creatively about how digital (and architectural) technologies can be used in exposing and archiving human rights violations.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information:












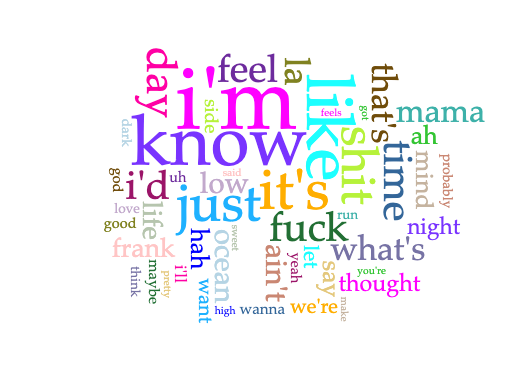
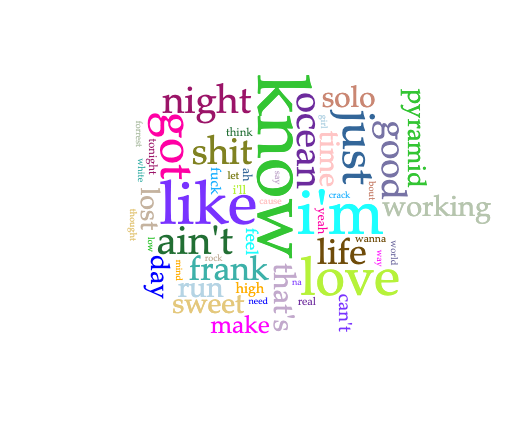











{kind=link}