I attended the workshop “Git It: Intro to Git and GitHub” taught by Nicole Cote. It was super helpful. Below is the process and reflection about it.
The first steps with Git and Github are, of course, to download the program and create an account on Github. However, to be able to interact with the program and with the local versions of your files you previously need to have installed a coding program like Sublime, Virtual Studio Code or Xcode. Then, you need to select a way to download Git, there are several options, I tried (for reasons unknown to myself) several. In the end I did the homebrew option and ran it through my terminal. Then, the program kind of just goes on its own. It was all very confusing and intimidating at first so I had to watch several videos on how to do it. The most useful one was this one. The guy goes straight to the point (unlike so many others!) and even helps you setting up a ‘Personal Access Token’ without which I just couldn’t do anything on my Mac (again, who knows why).
Once able to download everything you’ll need to connect the local files with the repository you created online, or rather vice versa. Nicole walked us through how to do this step by step, which is sort of easy. You just create a new repository on Github and copy the URL of the ‘README’ file into your terminal. The repository has a specific or, rather, a basic structure so, at least to my understanding, there will always be a “README” file. But you paste the URL of the ‘README’ only once you’ve configured your git name and email on your terminal. Nicole also explained the most important and basic terminology that we absolutely need in order to create the communication path between local files and Github. She explained terms like ‘repository‘ which I understood as another word for where you save all the files of a project or simply a ‘folder‘; also terms like ‘Fork‘, ‘Branch‘, ‘Pull Request‘ and ‘Issue‘.

After reviewing the terms, we started our own test repository and try some Git Commands. I had to repeat this several times on my own until I actually could do it with some ease. And then, I started to make changes to the file on my computer and pushing the changes to Github repeating the following commands like a mantra: “git status/ git add README.md/ git add –all/ git commit -m “new” and so forth and so on, again and again and again. However, I must say that Git tends to tell you all the time and suggest to you if you’ve done wrong something or if the command has any typo, and tells you a possible option or solution, which helps a ton. I also read some of the material available on Git to understand Git, which you can find here. And also used this guide for the basic elements of Markdown files.
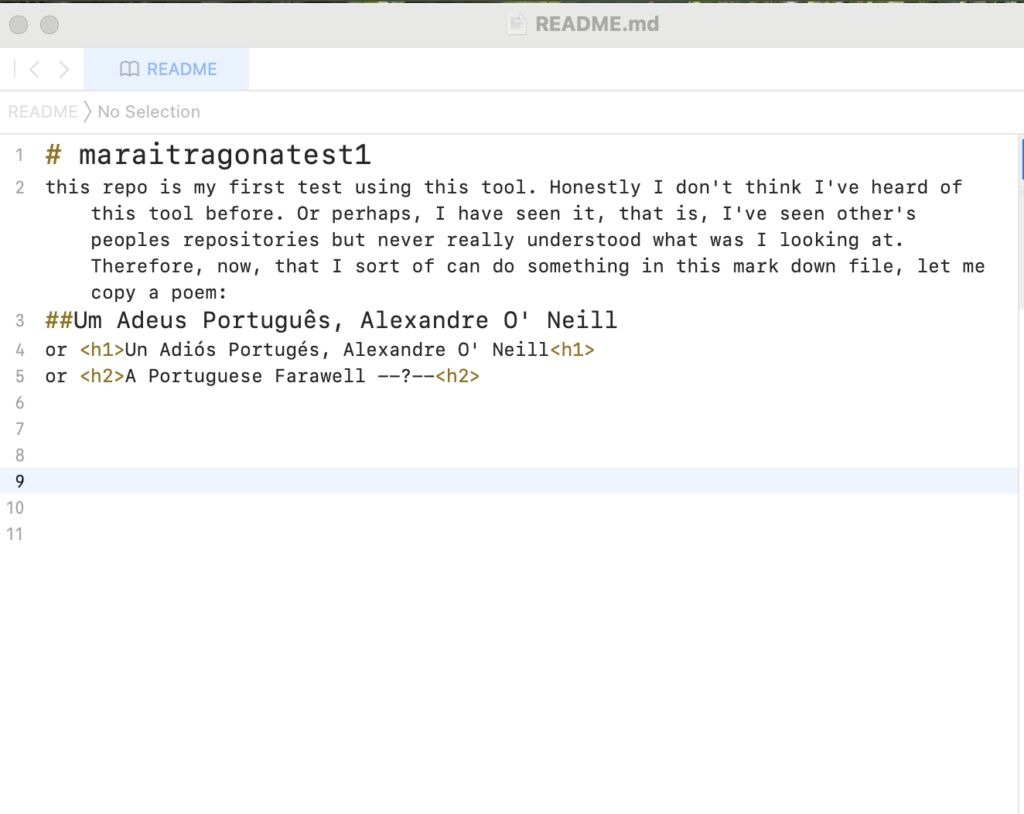
I decided to copy/past/interact with a poem just because, and ended with this README.md file on the test repo. After trying GitHub I do think is a great tool to track the multiple changes one does to a file/project, and is especially helpful if many people are collaborating at the same time. One thing I found very interesting is that the way the tool is built allows for collaboration that could be more horizontally oriented, so everyone can share their edits/opinions on a given project and all, at least in theory, are deemed equally important. Another feature is that other people can interact with your repo and raise an issue about changes they would like to suggest, furthermore they can clone your repo to start a similar project on their own. Thus, seems like knowledge shared on GitHub can be spread widely to different audiences rather than if you just store your projects or files in other places/websites/digital spaces where no one can comment or alter. I absolutely learned a lot through this process, for example now I have a basic idea of what’s the difference between a ‘Centralized Control System’ vs a ‘Distributed Version Control System’ like GitHub. And, honestly, I’m not sure anymore how I stumble upon the word kernel…maybe is just my plain ignorance but I was never ever introduce to any of this vocabulary. Which is terrible. This tool made me realize (again) how far the people that graduated from the humanities, like me, are to this terms. And that is so unjust and irritating if we consider how key this vocabulary is to understand the mechanisms by which our current world functions. And to realize (again) how compartmentalized our disciplines are is kind of sad; each creates its own set of terms and sophisticated vocabulary that ends up being nothing but a condense and rigid wall through which none but the ‘experts’ can penetrate and have a say.
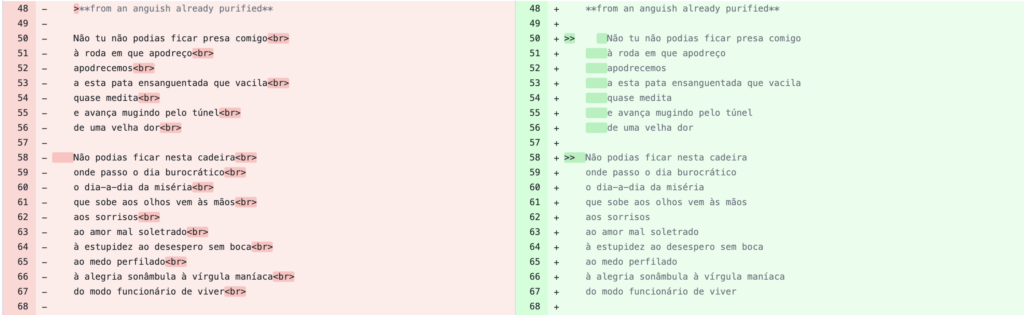
Anyways, it was fun to see how in fact you actually can review side by side (figure 4), track, and go back to previous versions of your files. While copying the poem I realized how great it would be for translators and creators to have different version of a same literary work, to be able to branch a file to create multiple word choices and have others comment on it or if there’s a work of fiction to have different passages and compare them side by side, seems so cool, at least in theory.
There’s so much more to learn and so much that I still don’t understand. So many questions.