
I attended the Introduction to NLTK (Text Analysis) with Python workshop this last Friday. The workshop was overall very useful, and helps you get started with the right suite of tools to start conducting some basic exploratory analysis on text data.
The workshop asked users to download Jupyter Notebook. I already had this installed as part of Anaconda Navigator, and had used it in a previous class. I find Jupiter notebook to be a great user-friendly tool to work and learn Python with!
We imported the NLTK Library and the matplotlib for data visualization in the notebook. Using the capabilities of these libraries and magic functions, the instructor showed us how to do some basic plotting and text analyses, such as calculating lexical density, frequency distributions of certain words, and dispersion plots.
Some of these commands are case sensitive, so the instructor taught us how to make all words lowercase to allow for proper counts. We went through the process of cleaning the data, with lemmitization and stemming, as well as removing stop words.
The steps we used are described in the code below. For this blog post, I decided to re-do the workshop assignment with looking at the The Book of Genesis instead of Moby Dick, which we used in the workshop.
import nltk
In [2]:
#for dispersion plot, #to tell Jupyter notebook to display the graph in the notebook import matplotlib %matplotlib inline
In [3]:
nltk.download()
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
Out[3]:
True
In [4]:
from nltk.book import *
*** Introductory Examples for the NLTK Book *** Loading text1, ..., text9 and sent1, ..., sent9 Type the name of the text or sentence to view it. Type: 'texts()' or 'sents()' to list the materials. text1: Moby Dick by Herman Melville 1851 text2: Sense and Sensibility by Jane Austen 1811 text3: The Book of Genesis text4: Inaugural Address Corpus text5: Chat Corpus text6: Monty Python and the Holy Grail text7: Wall Street Journal text8: Personals Corpus text9: The Man Who Was Thursday by G . K . Chesterton 1908
In [5]:
type(text3)
Out[5]:
nltk.text.Text
In [6]:
text3.concordance("whale")
no matches
In [7]:
text3.similar("life")
house name brother cattle blood son fowls money thigh god heaven it good land fruit fowl beast lord sight knowledge
In [8]:
text3.similar("love")
went drank earth darkness morning se them give nig hath man had thus not took keep die call sle woman
In [9]:
text3.similar("queer")
No matches
In [10]:
text3.similar("death")
face place cattle image host generations sight father mother wife eyes voice presence head children hand way brother sheep flock
In [11]:
text3.dispersion_plot(["life","love","loss","death"]) #the following graph shows where the word appears based on the number of words or pages in. e.g. between 0 and 250000

In [12]:
text3.count("Love")
Out[12]:
0
In [13]:
text3.count("love")
Out[13]:
4
In [14]:
text3_lower = []
for t in text3:
if t.isalpha():
t = t.lower()
text3_lower.append(t)
In [15]:
from nltk.corpus import stopwords
In [16]:
stops = stopwords.words('english')
In [17]:
print(stops)
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
In [18]:
text3_stops = []
for t in text3_lower:
if t not in stops:
text3_stops.append(t)
In [19]:
print(text3_stops[:30])
['beginning', 'god', 'created', 'heaven', 'earth', 'earth', 'without', 'form', 'void', 'darkness', 'upon', 'face', 'deep', 'spirit', 'god', 'moved', 'upon', 'face', 'waters', 'god', 'said', 'let', 'light', 'light', 'god', 'saw', 'light', 'good', 'god', 'divided']
In [20]:
len(set(text3_stops)) #to see how many unique stopwords there are use set()
Out[20]:
2495
In [21]:
# lemmatization to take the root word from nltk.stem import WordNetLemmatizer
In [22]:
wordnet_lemmatizer = WordNetLemmatizer()
In [23]:
wordnet_lemmatizer.lemmatize("waters")
Out[23]:
'water'
In [24]:
# create clean lemmatized list of text 3
text3_clean = []
for t in text3_stops:
t_lem = wordnet_lemmatizer.lemmatize(t)
text3_clean.append(t_lem)
In [25]:
print(len(text3_clean))
18335
In [27]:
#lexical density len(set(text3_clean)) / len(text3_clean)
Out[27]:
0.12838832833378783
In [28]:
#sorting the first 30 unique 'cleaned' words of the text sorted(set(text3_clean))[:30]
Out[28]:
['abated', 'abel', 'abelmizraim', 'abidah', 'abide', 'abimael', 'abimelech', 'able', 'abode', 'abomination', 'abr', 'abrah', 'abraham', 'abram', 'abroad', 'absent', 'abundantly', 'accad', 'accept', 'accepted', 'according', 'achbor', 'acknowledged', 'activity', 'adah', 'adam', 'adbeel', 'add', 'adder', 'admah']
In [30]:
#Stemming is the process of reducing a word to its word stem that affixes to suffixes and prefixes or to the roots of words known as a lemma. from nltk.stem import PorterStemmer porter_stemmer = PorterStemmer()
In [31]:
print(porter_stemmer.stem('accept'))
print(porter_stemmer.stem('accepted'))
accept accept
In [32]:
t3_porter = []
for t in text3_clean:
t_stemmed = porter_stemmer.stem(t)
t3_porter.append(t_stemmed)
In [33]:
print(len(set(t3_porter))) print(sorted(set(t3_porter))[:30])
2113 ['abat', 'abel', 'abelmizraim', 'abid', 'abidah', 'abimael', 'abimelech', 'abl', 'abod', 'abomin', 'abr', 'abrah', 'abraham', 'abram', 'abroad', 'absent', 'abundantli', 'accad', 'accept', 'accord', 'achbor', 'acknowledg', 'activ', 'adah', 'adam', 'adbeel', 'add', 'adder', 'admah', 'adullamit']
In [34]:
my_dist = FreqDist(text3_clean)
In [35]:
type(my_dist)
Out[35]:
nltk.probability.FreqDist
In [36]:
my_dist.plot(20)
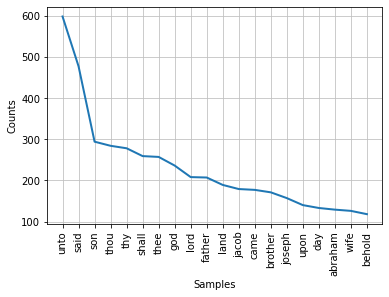
Out[36]:
<AxesSubplot:xlabel='Samples', ylabel='Counts'>
In [37]:
my_dist.most_common(20)
Out[37]:
[('unto', 598),
('said', 477),
('son', 294),
('thou', 284),
('thy', 278),
('shall', 259),
('thee', 257),
('god', 236),
('lord', 208),
('father', 207),
('land', 189),
('jacob', 179),
('came', 177),
('brother', 171),
('joseph', 157),
('upon', 140),
('day', 133),
('abraham', 129),
('wife', 126),
('behold', 118)]
In [ ]:

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.