I attended this event about “Impact Factor and Other Research Metrics: What They Mean and What They Don’t” by Jill Cirasella (Associate Librarian for Scholarly Communication). While I have not written any formal article yet, I have always been curious about citation and their “importance” ever since one of my former work colleagues who had a Ph.D. once told me his paper finally got cited 100 times (which apparently was an exciting milestone).
This workshop gave a wonderful overview of the context of key citation metrics and how problematic they might be. The metrics discussed include:
Article Metrics (aka how many times an article had been cited)
h-index (largest number h for which the author has published h articles that have each been cited h or more times.)
Journal Metrics (What is the journal’s Impact Factor?)
I also found the discussion around citation gender gaps interesting, here’s a quick summary:
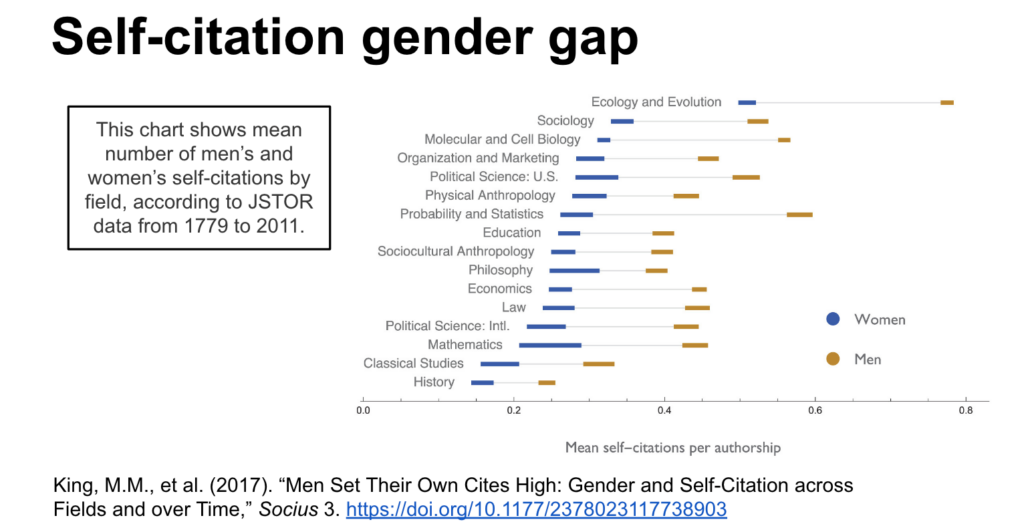
Men cite men over women.
Mixed-gender co-authored papers cite men over women.
Men self-cite more frequently than women do…even in fields with the majority of women authors.
In fields that are trending toward more women authors, no corresponding trend toward citing more women.
Interesting Visual: It was discussed in the workshop how metrics could be “gamed” by a scholar. The following shows male scholars are way less shy about self-citing their own work (which will boost their metric), which contributed to the citation gender gaps.
If you are interested in the workshop but didn’t get to attend, you can check out their:
While I have enjoyed many readings this semester, I do find a lot of them written in the “academic style”. It is refreshing to find readings that express a similar amount of information and critical analysis but in a way more reader-friendly format. I took some time to think about what made this reading so much more digestible and engaging than other readings (in terms of format, not content-wise) and want to share my observations below:
The chapter outline gave me an overview of what I should expect, as opposed to much academic writing, I have re-read the writings a few times and “do the work” to figure them out.
2. The information hierarchy is extremely clear with the use of font size and font color
3. I find the visualization very easy to interpret and done “just right” (in terms of size, color, design, information density, etc.). All charts are clearly titled, annotated, and explained. Note: I have very familiar with these chart types, to begin with, so I already know how to “read/ interpret” them.
4. Tables are utilized to express the right amount of information, sorted logically and stylized in a way that’s easy for the eyes.
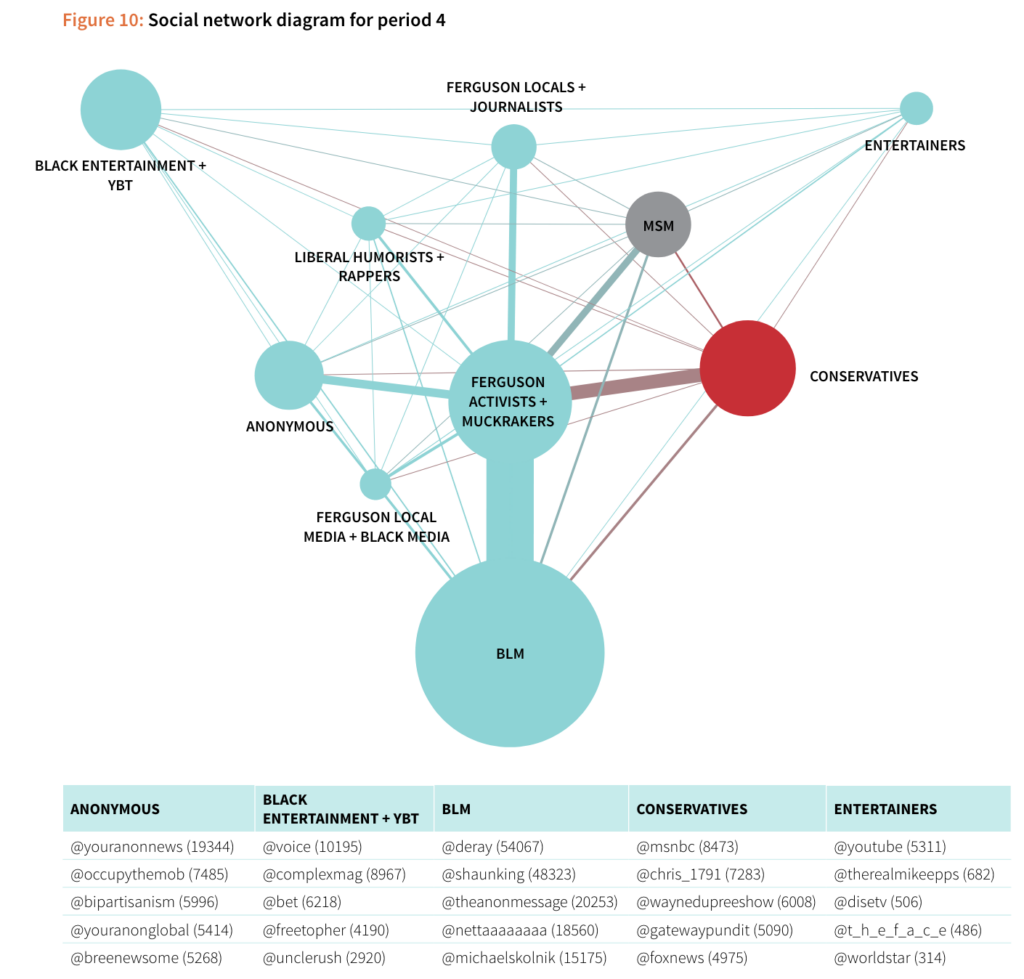
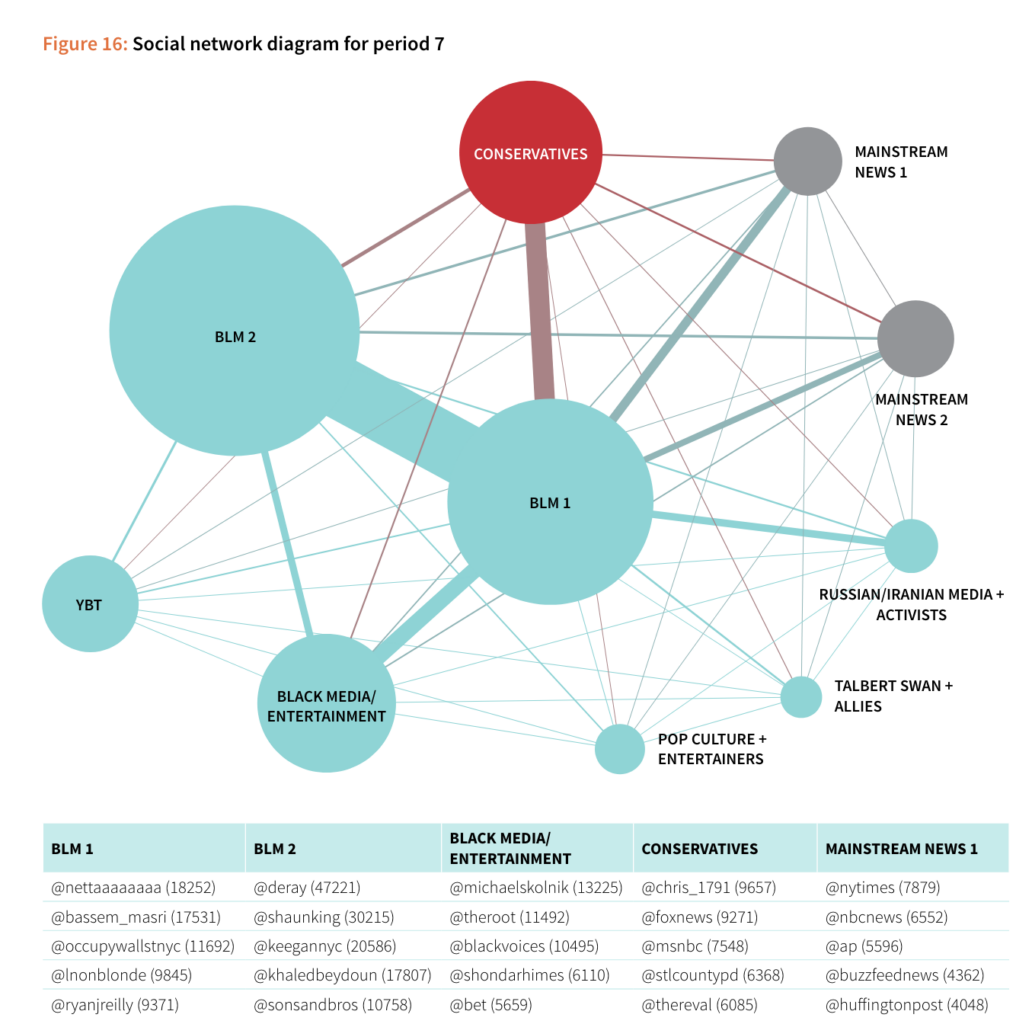
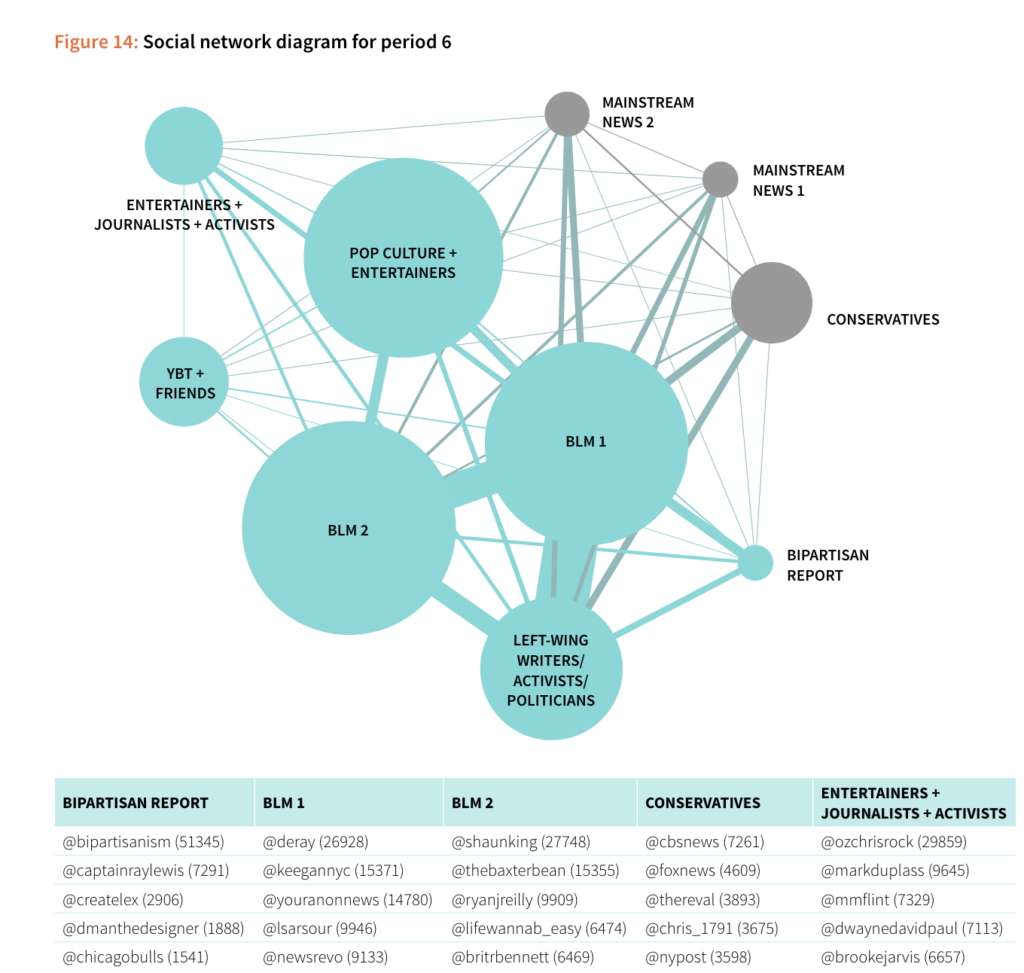
5. Chapters on Social diagrams leveraged a consistent form, making it easy to follow without doing a lot of brainwork to digest.
I found the readings and projects for this week interesting. They show a potential for making new ways for doing archival work. These approaches are inspiring and in this blogpost I will reflect upon the readings and highlight the project DocNow for providing tools for archivists, activists, researchers to gather social media data.
As described in the reading “Towards Slow Archival” by Kimberly Christen and Jane Anderson the history of collection is the history of colonialism. They reading raises the question about “how do we recognize and rebuild archival practices, structures, procedures, and workflows that allow for relational, reciprocal , respectful , and restorative connections to knowledge, kin, and community within their frame?” Their specific method is slow archiving and by doing collaborative archiving. I find the work of Michel-Rolph Trouillot relevant to this call for a new decolonizing praxis. Trouillot was a Haitian American Professor of Anthropology and Social Sciences at the University of Chicago and he contributed with many books to the field of anthropology. He is best known for exploring themes of origins and application of social science in academia and its consequences in the world. He discusses the study of the “other” in anthropology and how this has led to theories of inherent distinctions between Westerners and non-westerners. He argues we need to look upon the categories and concepts we think with as something that shapes our experience but that very experience also shapes in turn the categories and concepts. It gives space for reflection and for questioning some of our fundamental assumptions when doing research, and I see this as another way to try to decolonize knowledge production. For example, Trouillot uses this approach to work with these ideas to reimagine the Caribbean peasants as agents of their own history instead of as victims. In a similar way Christen and Anderson call to move archival works away from preservation and towards “processes of opposing imperial and ongoing forms of collecting and classifying which isolate the relational, deeply embodied, practiced, and dynamic processes between people, belongings, land, and communities that make, remake, and unmake cultural heritage, knowledge, and traditions.” (page 100) How does digital humanities create new ways of archival work towards as an act of care and resistance?
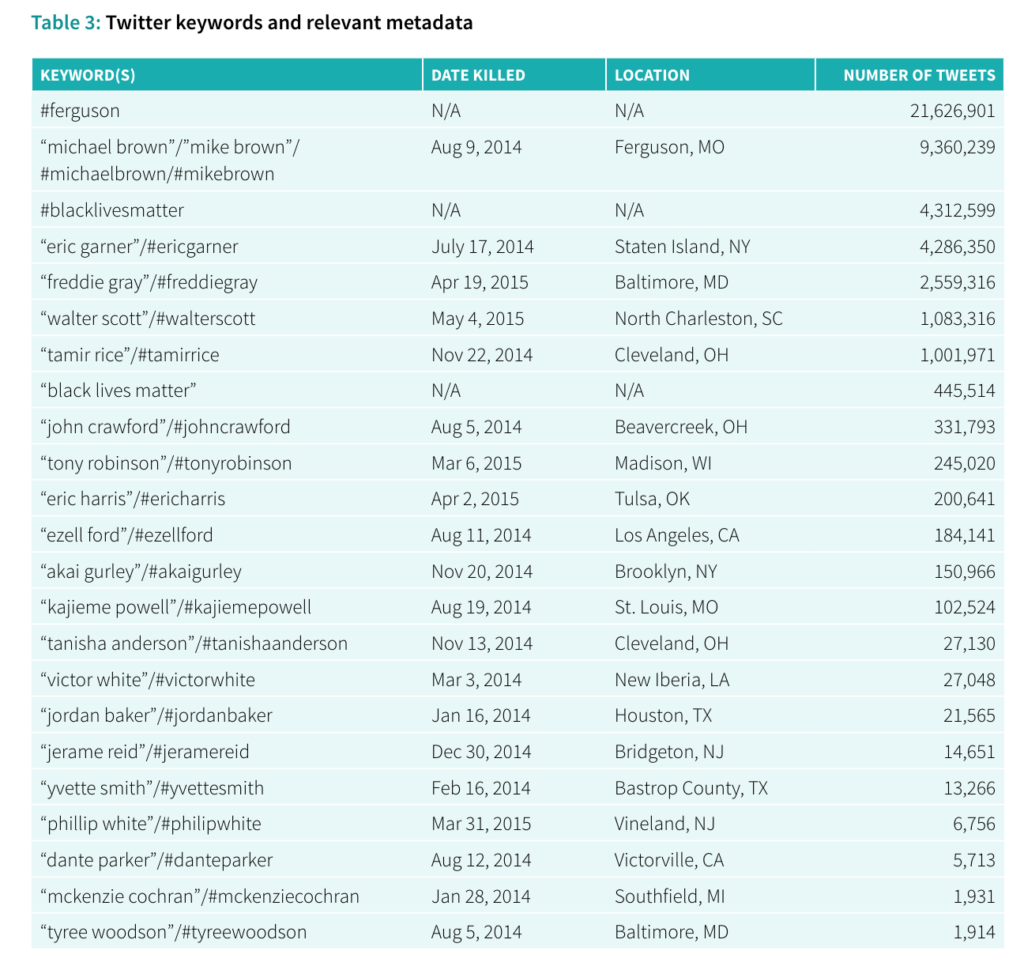
One of the selected projects for this week DocNow, tries to deal with this struggle. The Documenting the Now (DocNow) project’s primary aim is to help preserve and chronicalize historically significant events and other digitally relevant content found on social media sites. It focuses on providing a variety of digital tools, as well as acts as an appraisal of content, to help analyze social media content. A strong focus on ethical collection and preservation of social media data adheres to Twitter’s notion of honoring the user intent as well as preserving the rights of content creators. In many ways the site offers a large range of tools and additional resources to create a way for archivists, activists, researchers to gather social media data. The website consists of six different tools created by the DocNow project which are all accessible via GitHub, a software development platform. Utilizing GitHub allows the organization to create a more open and accessible participatory environment, which agrees with their community-based approach. I see the project as trying to be a way for not only collaboration between cultural institutions and people, but trying to give the tools to the people to conduct their own research. As the report “Beyond the hashtags: #Ferguson, #Blacklivesmatter, and the online struggle for offline justice” partly concludes the primary goals of social media use among their interviewees were education, amplification of marginalized voices, and structural police reform. The report shows how movements can learn valuable knowledge from analyzing their “own” data. I believe it highlights the relevans of making the tools of archival work more accessible. This example might be a less traditional approach to archival praxis, but I think it manages to go beyond the idea of preservation and instead deals with the concepts of ownership of history and data. I’m curious if we are gonna see more similar research in the future and how it might affect the power relationships and knowledge production within archival works.
I currently work as a documentation and UX writer for a team of data analysts and software engineers. In this job, the word “Tableau” is something I either read about, write about, or edit something about on a near-daily clip. However, until starting this assignment, I had never actually opened the GUI of the software and had only written about what Tableau spits out: usually beautiful and straightforward visualizations for which I need to provide captions. As it turns out, I’m lucky (so far) my role hasn’t involved interfacing with the platform since it seems that I’m quite terrible with the software. It took me several hours of tweaking to try and make something that looks remotely cool (beautiful is already out the window). But, I think that’s the purpose of these assignments — I’m happy that I now have the basics down to eventually make something closer to beautiful after further practice (and maybe an ad-hoc sesh with Felipa).
During one of our early weeks of class, I mentioned how I had worked on a translation project for New York City a few years ago, which entailed managing the translations of digital assessment material into the “nine official” non-English languages of the New York City Department of Education (NYCDOE). For certain assessments in NYC, students are allowed to request translated materials into their “home” language. The assessments that allow this are normally measuring subject-matter constructs like math, science, history, and health. I’ve found it impossible to name these languages off the top of my head whenever I’m asked, so here they are after Googling: Arabic, Bengali, Chinese (modern), French, Haitian Creole (also referred to as French Creole), Korean, Russian, Spanish, and Urdu. Since this topic usually gathers interest when I bring it up, I figured it was a good data topic to explore with my visualizations.
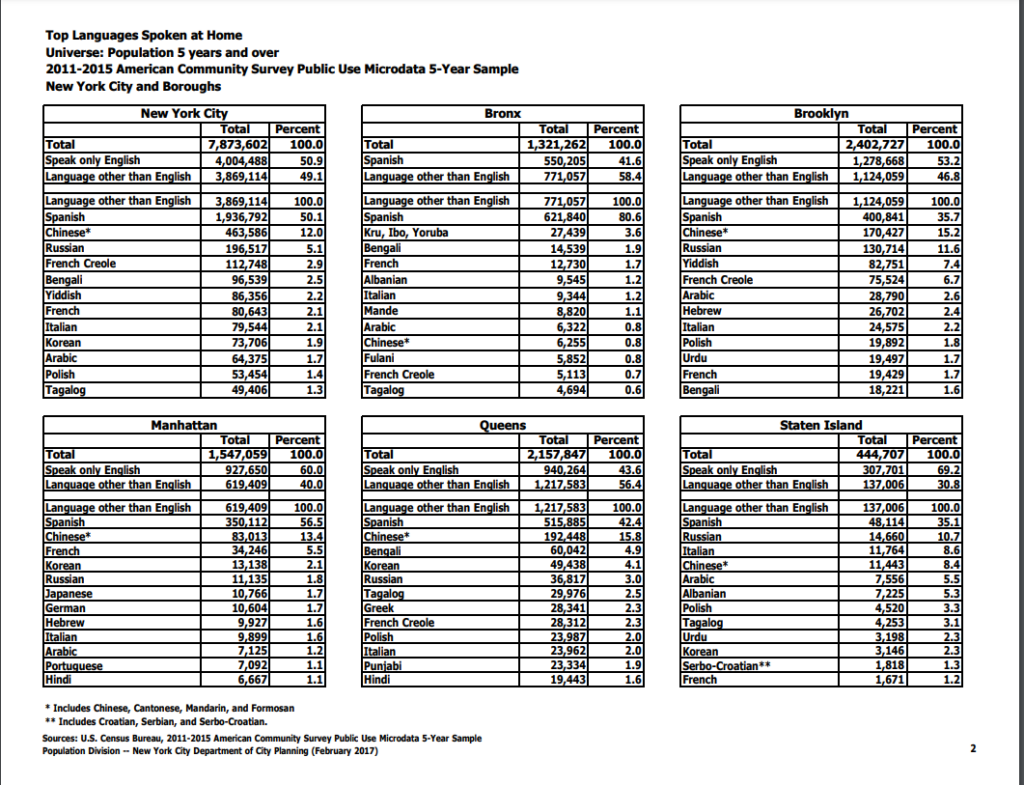
The first thing I tried to do was find some numbers for how many student learners spoke each of the nine respective languages. This proved difficult and I wasn’t able to find very valuable data. I did stumble onto a NYC.gov page that breaks down the most commonly spoken languages at home in the city, which interestingly did not wholly align with the nine languages the DOE uses. You can view the pdf breakdown here: https://www1.nyc.gov/assets/planning/download/pdf/data-maps/nyc-population/acs/top_lang_2015pums5yr_nyc.pdf. I’ve also pasted a screengrab of the data below.
The 12 most spoken home languages in the city and by borough
I decided to migrate these data into a spreadsheet, which was fairly time consuming in that of itself. As you may notice from the data (or from my caption), the languages are broken down by the top 12 languages in the city as a whole and then by each borough. It didn’t resonate with me at the time, but this presents some fairly confounding sorting obstacles for creating visually appealing data visualizations. As we learned from Manovich, the first principle of data viz is reduction. I’m sad to say that my first attempt at a visualization of these data points actually adds more noise than the (very dense) table I pasted above.
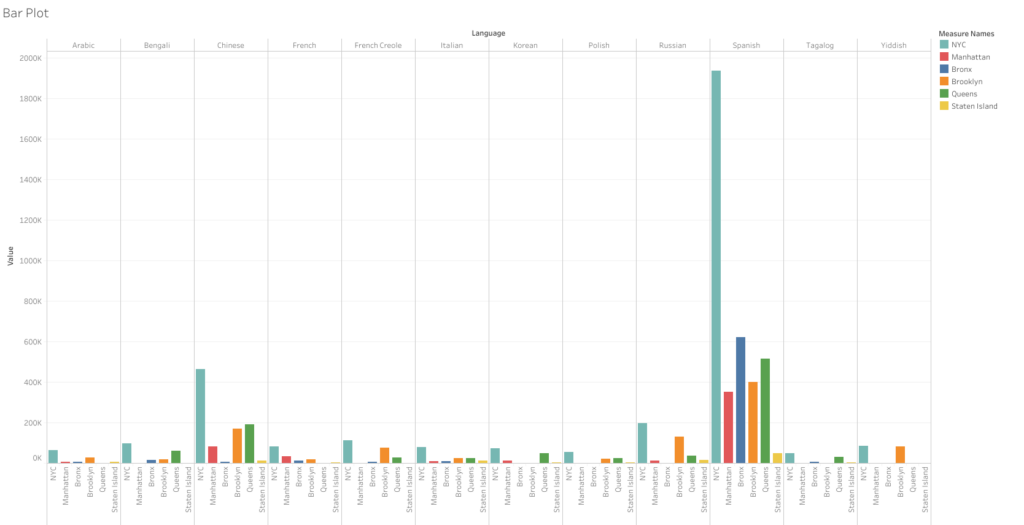
First noisy attempt at visualizing the languages (click link above for larger view)
This bar graph takes all the languages and runs them along the top axis and then stacks the amount of speakers by all of NYC and then each borough. However, since each borough has a different set of top-12 speakers, they don’t align with the city’s overall numbers. Thus, even though Yiddish is one of the top 12 languages spoken in the city — it received null values within Manhattan, Bronx, Queens, and Staten Island as it falls out of the top 12 in those particular areas. This was the case with nearly a dozen other languages that are more prominent to certain boroughs. These null values ended up causing me a huge headache as I couldn’t figure out how to remove them from a single borough without removing them from the data sets where they are relevant. I think the only valuable thing one can take away from this first attempt is that Spanish is spoken at a significantly higher rate than any other language in the city. Chinese is the only other language that stands out, and it’s not even close to the sky-scraper bars shown for Spanish. But overall, as I said, this visualization certainly fails the reduction test. I can grasp the data better looking at the text tables.
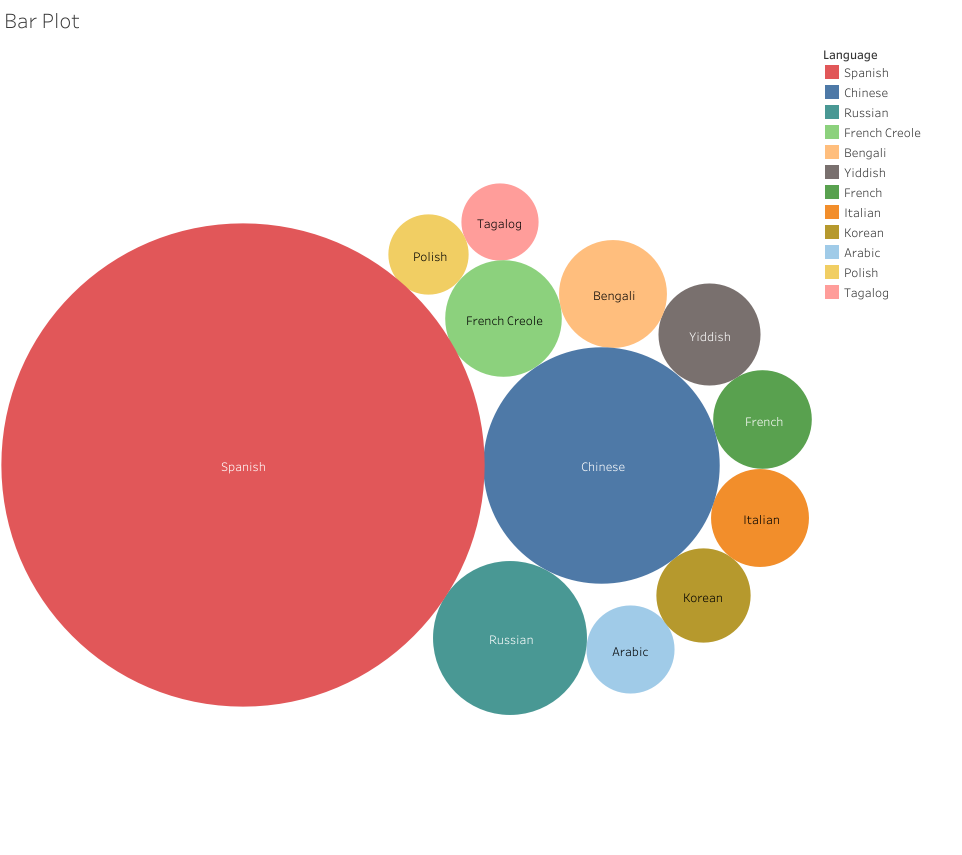
For my next attempt, I decided forget the other boroughs and focus on the All NYC data to try and make something a little more simplified and helpful to a viewer trying to take away a snapshot of these data. I again ran into some issues with Tableau — as whenever I tried to use some of the nicer looking viz options, I was told I needed to add at least one “dimension” to use this or that visualization option. I couldn’t figure out what that meant as I seemed to have several data points labeled as “dimensions,” but many of the visualization options remained greyed out. I went with one of the more classic visualizations: the packed bubbles, which expand based on the volume contained in each data point.
Packed Bubbles Visualization of Home Languages Across the City
Now, this visualization I think properly reduces the noise from the text tables. It’s only regarding a single set of data: the top 12 non-English languages spoken at home in NYC. The user can clearly see which languages scale well above the others and can quickly make sense of the top 12 by looking at the order provided in the legend — and then can compare the numbers by hovering over the bubbles. I’m not sure if this is a cool visualization, but it’s at least somewhat effective.
In the context of my blog post, this visualization does pose an immediate question: why do the nine languages of the NYCDOE include Urdu when it isn’t in the top 12 across the city? I don’t know the answer, but we can see that Tagalog, Polish, Yiddish, and Italian all have more speakers yet aren’t provided as options for translation. This could be due to the amount of learners in the public schools representing each language. Yiddish speaking students my be more likely to attend Jewish religious schools, which could dwindle their numbers in the public school system. Likewise, Tagalog (Filipino), Polish, and Italian speakers may be more likely to attend Catholic schools. Whatever the reasons, I like how the reduction attempt made it easier to find some data points to discuss. Whereas my first attempt just created a vomit of bars that provided no discernable information to glean any insights from.
This week’s readings cement a concept that is not as obvious as it might sound: facts are a matter of perspective. Similarly, history is a matter of perspective.
An event, any event, can be subjected to a myriad of different narrations, which could be considered veritable if accounting for the storyteller’s background and their angle. Acknowledging this without attempting to arrogate the right of divulging a universal truth is no easy task though. In this sense, the 911 Digital Archive project plays a key role in preserving history as collected from its sources. And with a great sense of acceptance in doing so, which translates into the ability of understanding, and consequently embracing, how everyone lived the same tragic day in different ways.
In this sense, Brier and Brown, in their publication The September 11 Digital Archive, stress the speed at which a system aimed at gathering as many testimonies as possible, both in digital and analog formats, had to be brought to life within days from the attack.
The authors try to go beyond what mainstream media institutions present and ask themselves the question of what consequences the 9/11 attacks generated in everyone’s life including, if not especially, the one of “ordinary” people who were either at work or going to work, those who were floating around the area of the impact, maybe spending the day somewhere in New York City or perhaps somewhere else farther, and others, who were not necessarily on site, but happened to receive a message from someone somehow directly involved.
9/11 Memorial, photo taken from personal phone, September 2022
Their idea of collecting materials, in any form or shape, and from everyone, directly and indirectly, is remarkable, and, in a sense, avant-garde. The concept revolves around the action of gathering testimonies and evidence when facts happen as opposed to wait for them to be brought together by the media or through ‘post-mortem’ research. In this light, the introduction of the role of the archivist-historian is revolutionary, and orbits around the notion of perspective and the creation of a 360-degree viewpoint, or collective history, where everybody has the right, and the channels, to actively contribute.
A similar project is carried out by the curators of Our Marathon, an online accessible archive of photos, stories, and videos of the 15th of April 2013 Boston attack. Once again, the ‘game changer’ is the authors’ modus operandi whose goal is to ensure that the contributions to the platform are crowdsourced and free from potential media manipulation.
Using this approach, new tools to accurately build a collective and democratic history have become progressively available. Platforms like Omeka, CUNY Digital History Archive, and Home – Mukurtu CMS allow everyone to share their experience and perspective. The value of this relatively new way of operating when building archives is immense and, undoubtedly, grows over time. Personally, I feely lucky to live in an era where I am given the opportunity, and the means, to contribute to history with my own experiences and angle. Unlike my grandparents, who were both sent abroad to fight during WWII and witnessed the war’s atrocities, I know I have the luxury of crystallising (and sharing) my day-to-day life and views through the internet and its endless devices, whereas their legacy, and their days in Greece, Germany and Russia, only live in my memory and might soon get lost.
Since our last class discussion, I’ve been reflecting on what makes a visualization “work” — and whether evaluating a visualization that way is even possible. Any critique of a visualization has to include considerations like:
Who is the intended audience, and how much does that overlap with the actual audience? For example, if a humanities-related data visualization in an academic paper is clear/legible to scholars with a deep knowledge of the subject matter, but inscrutable to undergraduate students assigned to read the paper, is it successful?
How much should we expect a humanities data visualization to convey, and how authoritatively? As Krysia pointed out in our discussion, using data to “close down questions” may run counter to the aims of the humanities. Trying to seek definitive answers from a visualization also ignores Drucker’s distinction between capta and data.
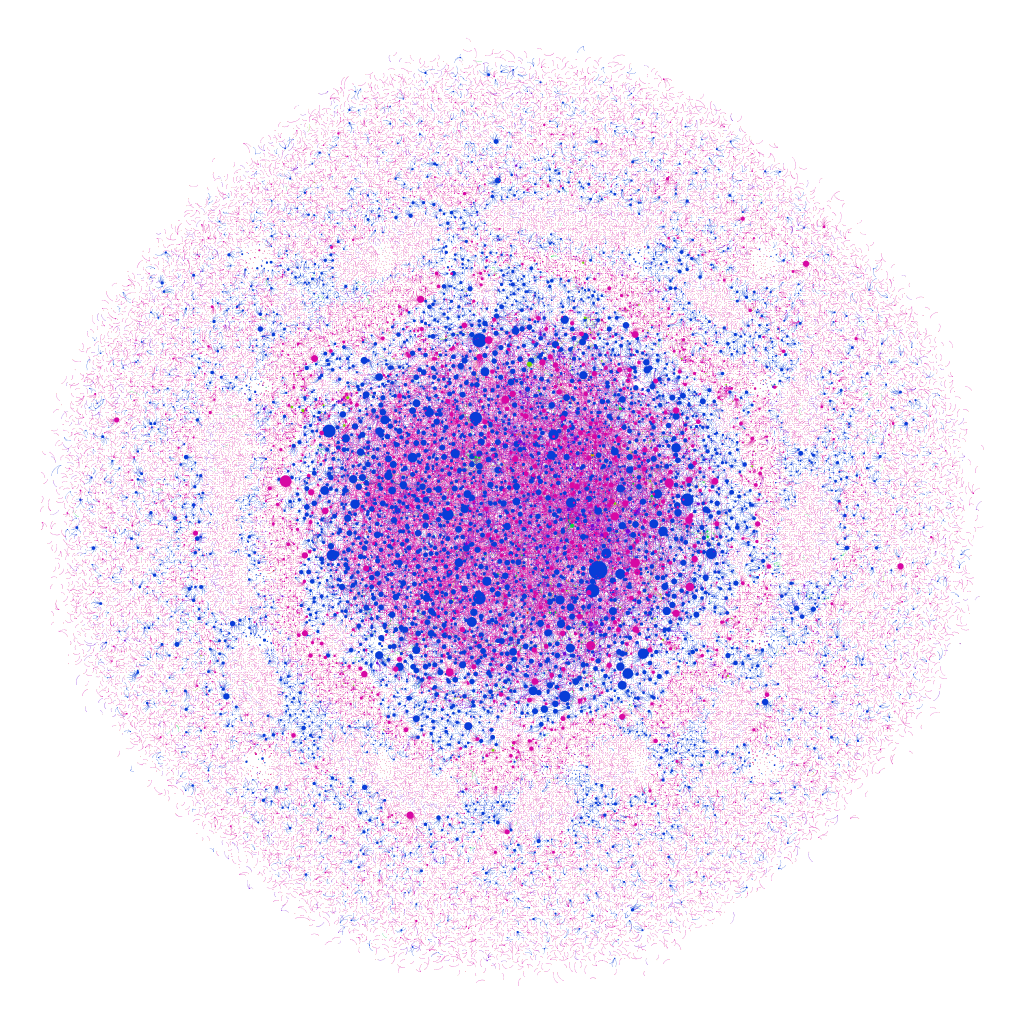
What is the affective/emotional impact of the visualization — and how much does that dimension of a visualization matter? I keep coming back to this image from Teddy’s blog post on Sefaria in Gephi, a visualization of meaningful Jewish texts. The visualization shows Biblical texts and commentaries in blue, the Gemara in pink, and other sources in red, green and orange, with the nodes appearing larger based on the number of connections to that text — the largest blue node is Genesis 1:1. The author of the visualization compares it to a “cell under a microscope,” but it reminds me of a supernova, as well — and both images feel fitting and emotionally resonant with the subject matter.
What effect might the toolkit used to create the visualization have on the scope and perceived meaning of the visualization? The features and constraints of any platform can shape the way data is presented, and even the type of data that’s collected. It’s easy to imagine how an individual’s reliance on a specific platform could limit the types of data would collect, and by extension, the types of questions they would research.
Is it possible (or valuable) to evaluate the visualization author’s skill/success as part of (but still somewhat separate from) our overall critique? With a written text, the author’s skill (or faults) as a writer can determine how effectively they convey their argument. Visualization might have the potential to obscure an author’s limitations — something glossy and visually intriguing might draw weak conclusions or be a mess “under the hood.” On the other hand, an author who is able to create their own visualization tools has a lot of power to convey their point exactly as they intend. To call back to the old DH debate about the importance of being able to “make,” is the author’s control of the visualization something we should consider to evaluate the visualization, or would any weaknesses/errors on the author’s part be evident in the final product, as might be the case in a written work? The question might be purely theoretical, anyway — if we can’t see behind the curtain of a visualization, this may be impossible to know.
Along with all of these considerations, I’ve also been thinking about complexity vs. legibility. Per Drucker, a humanist approach to visualization allows us to capture subjective experience and analysis:
The challenge is to design graphical expressions suited to the display of interpreted phenomena: information about subjective user-dependent metrics, subjective displays of information, and subjective methods of graphical expression. The term subjective is used as shorthand for interpretative construction, for the registration of point of view, position, the place from which and agenda according to which parameterization occurs. Subjectivity is not the same as individual inflection or mere idiosyncracy, but is meant to put codependent relations of observer and phenomena (in contrast to presumptions of objectivity, or observer-independent phenomena).
Joanna Drucker, “Humanities Approaches to Graphical Display,” 2011
I would argue that the challenge lies equally in designing visualizations that are “suited to the display of interpreted phenomena” and in making sure those visualizations are legible in a way that allows for subjective but at-least-somewhat consistent readings.
For example, this visualization from Drucker’s article is complex and reflects interpretive construction, but is also easily legible, in that it’s possible to quickly understand how the visualization was constructed and use it as a jumping off point for further discussion. When I interpret it, I can assume that other good-faith readers can gain similar insights to my own:
Joanna Drucker, “Humanities Approaches to Graphical Display,” 2011
However, I’m not sure if the same could be said for visualizations like the one below — though I admit that me not understanding it doesn’t necessarily mean it’s illegible:
Joanna Drucker, “Humanities Approaches to Graphical Display,” 2011
(I had a lot of questions here that might be answered with greater context, with a major one being: “What on earth does the hole mean?”)
Of course, to some extent, all visualizations necessarily depend on context to be legible and useful — as Drucker points out, even “straightforward” datasets and visualizations involve choice and decision-making from their creators. But I do wonder about the utility of a visualization that’s difficult or impossible to interpret without already understanding the data, the author’s intent, the unprecedented visual metaphor, the degree of attempted precision, etc.
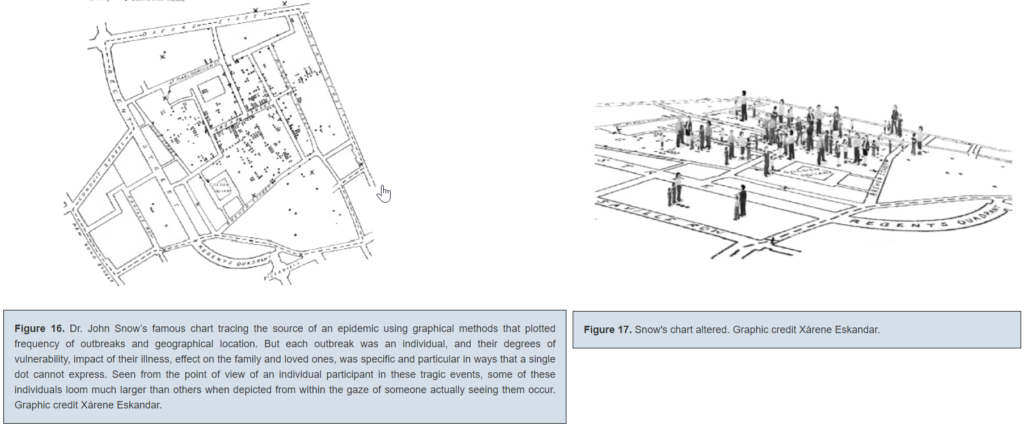
Finally — what do we make of a visualization that approaches the complexity and level of detail of the original data/capta-set it’s trying to illustrate? I’m thinking of this alternative to John Snow’s famous cholera spread chart that Drucker offered:
Joanna Drucker, “Humanities Approaches to Graphical Display,” 2011
This is such an interesting choice to me, since altered chart still tells us not much about the individuals who died of cholera — and the original is one of the most famously effective and influential visualizations in history. While supposedly more interpretive, the new one seems to be something closer to a recreation of situation — it reminds me a bit of Borges’ country-sized map of the country from “In Exactitude in Science.”
I hope we get more of a chance to discuss this as the class goes on — I’m curious as to what others think, and if maybe my approach (thinking about effectiveness/utility) means I’m not quite taking these visualizations as they’re intended to be taken.
Finally, I want to leave off with a visualization I’ve always found particularly striking, though it’s pre-Digital Humanities:
W.E.B Du Bois, presented in 1900 at the Exposition Universelle — this article from Smithsonian gives more detail about the circumstances and the team who made it.
This is a visualization created by W.E.B. Du Bois and a team of students and alumni from Atlanta University as part of an exhibition at the 1900 Paris Exposition Universelle. (You can read more about it here.) While some of his other visualizations are more abstract and, for me, edge on that zone where expressiveness outweighs easy legibility (for example, a historian I know confessed that he still “[doesn’t] really understand” this beautiful one), this one depicts data precisely while still conveying an affective impact. The choice to fill in the enslaved population as a large black block creates the image of an enormous mountain-like mass — of humanity, of suffering, of injustice. It foregrounds the scale and endurance of American slavery in a way that a simple line or bar graph couldn’t. I think even if you were to extend the chart to the present, with the mountain of slavery further in the past, it would still be a powerful reminder of just how many generations of individuals were enslaved in this country.
I’d be curious to see other examples of pre-digital visualizations that push past the conventional limits of what a visualization can do — and how they might conform to or challenge Drucker’s ideas about humanities visualizations.
This workshop was given by the Writing Center as a guide for those as the name implies. The presenter gave some strategies for engaging secondary sources and for being on the ‘right’ side of an assignment. The presenter discussed the strategies on how to approach each either geared for a Master’s assignment or for a Phd dissertation. It was a helpful and blunt advice-driven workshop geared to making assignments a bit more focused for the environment. I have a copy of the handout of the strategies they discussed during the workshop if anyone is interested. Drop a note and I will forward it.
I’ve been attending many workshops lately, and they have been very instructional. In the past week, I’ve attended workshops on Python and R, both coding languages. I am an absolute beginner and wanted to share my impressions with my class colleagues. Here it goes:
The Python workshop was geared to basic beginners which made it easy to follow along. The presenters were very helpful in assisting us in downloading the program and setting it up. Some of us had issues during the set-up process and were guided to a breakout room for individual help. Once done, we were given an introduction to the interface and some basic language prompts. Several of the prompts introduced were the comment prompt (#) to make a comment without executing an operation, print, which shows the item in question. There were several others. When I asked how this would be used for a project, I was asked to wait until the next session to get the answer.
The R workshop was pretty much similar in that it was geared for basic beginners and it was pretty easy to follow. However, the presenter started the presentation with finished projects, which gave an end point to focus on as an example. Again, we learned the interface and basic operations. However, with this workshop we downloaded data from the UN and worked on it, which helped solidify the concepts. Getting my hands wet so to speak made the learning stick more.
After attending both workshops, I’ve noted several slight differences. (Please keep in mind I’m an absolute beginner.) Python seems to be the one to go to for big data analysis. R seems to be the one to go for visualization. Python seems a bit easier. R seems to have a bit of a higher learning curve.
In regards to data, it seems that the Native American epistemologies align with that of the queer community.
I’m someone who is deeply involved with minority data. My project, Map Lemon, specifically has found itself gathering data on trans people. And immediately, we faced backlash just for gathering the data to begin with. A lot of these come out of fear from the queer community: “this could be misused”, “could this ‘out’ trans people?”, “you can’t try to box non-binary people in for data”. While, as a queer person myself, I understand these fears and they have a real basis, I must continue to gather and analyze this data simply because it exists. I didn’t start Map Lemon intending to find stylometric differences between transgender people and cis people, but the data spoke by itself simply by gathering standard gender demographics. I cannot ignore incidental findings once they’ve been discovered. And with that, the data has actually come out in favor of the current LGBT+ political climate. With that said, I also believe that queer people must collect our own data, as a form of rewriting the history of those who have attempted to erase our existence through academia. Perhaps some of the initial backlash to this data I hold was because I was assumed to not be queer?
I’m pleased the tide is changing as my data proves to support the current philosophies of the queer community, and I’m conscious of the need to respect these fears existent within this community, however what I want is this fear to produce tools or methods that can adequately represent, say, non-binary identities, rather than shying away from data collection entirely. I also understand that I’m in a position of privilege as a queer person who has made it this far into academia to gather and present this data in a helpful way, and want to create a body of work that accurately represents as many of us as I can fit in!
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: