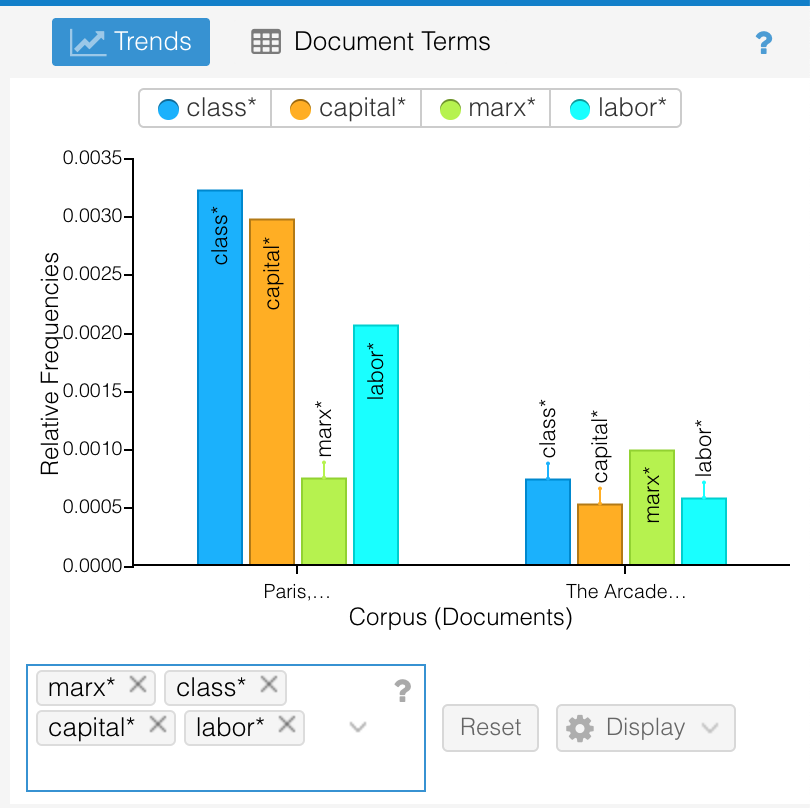
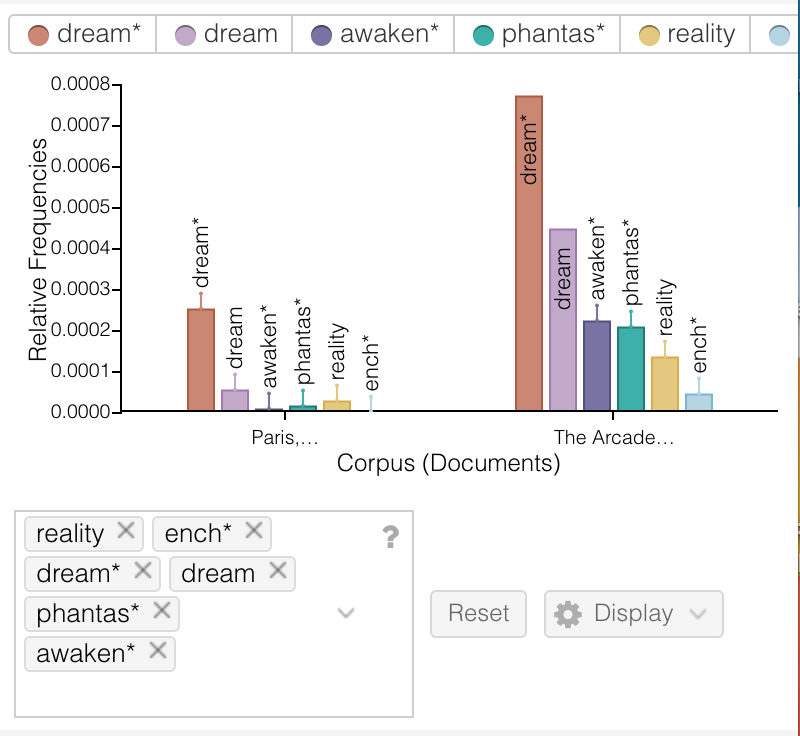
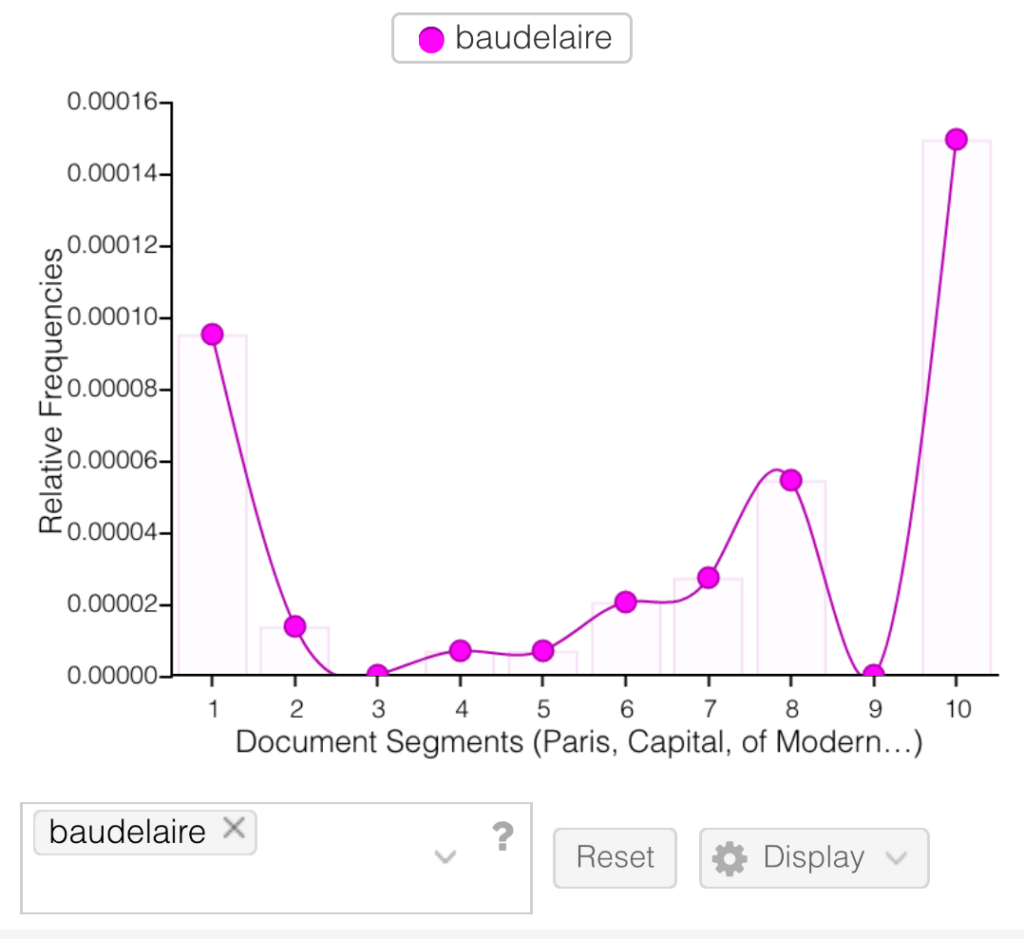
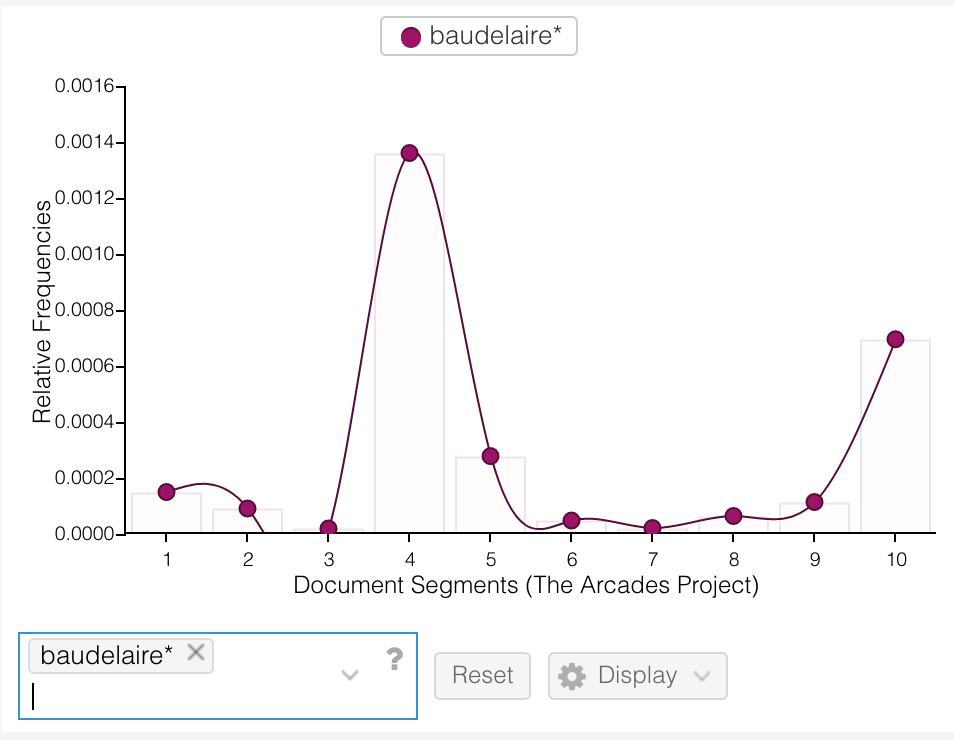
Below is a deep dive (possibly complemented with periods of floundering) into Deuze, Blank, and Speers’ A Life Lived in Media. My initial aim was to investigate/interrogate their use of David Harvey’s The Condition of Postmodernity but this led to a jumble of elsewheres. I recall the issue of scope being mentioned in class recently?
In A Life Lived in Media, Deuze, Blank, and Speers advance the notion that an additional ontological turn is necessary for how we understand, interact, and individuate through media. Approaching the question of the “media life perspective,” or the “realization that the whole of the world and our lived experienced” are framed by and mitigated through media, through four terms perspectives (that of invisibility, creativity, selectivity, and sociability), the authors of the piece argue on behalf of the artistic autonomy afforded to us via “media life” and the “endless alternatives and versions” of self-creation that are made possible should one learn to position oneself within media networks and the “always-available global connectivity” that they allow (2012, p. 1, 36). Aware of the possible readings of their piece as a reductive argument made unsuccessfully against the “existential contemplations” of the “panoptic fortresses of governments and corporations that seek to construct a relatively cohesive and thus controllable reality,” Deuze, Blank, and Speers seem satisfied with such a slight-misreading, ultimately concluding their piece with a vapid case of “life being art” bolstered with cherry-picked quotes from the likes of Foucault, Bauman, and Nietzsche (2012, p. 37). With that said, I did like this article.
Much of what Deuze, Blank, and Speers discuss in this piece struck me as salient, familiar, and interesting, such as Harvey’s notion of flexible accumulation and Hearn’s discussion of compulsive outer-directed self-presentation. However, I feel as if whatever conclusive argument was being attempted lacked both clarity and an applied awareness of the severity of the inevitable “loss of self” through the increasingly imperceptible “Mediapolis” (Deuze, et al., 2012, p. 3). In what follows, I will attempt to outline, critique, and expand on Deuze, Blank, and Speers’ four provided terms (invisibility, creativity, selectivity, and sociability), addressing both the arguments made in their respective sections and the appropriate or misplaced employment of thinkers therein.
Invisibility
In addressing media’s ontological possibilities, the term invisibility is used by Deuze, et al. to represent “the disappearance of media from active awareness” (2012, p.1). This disappearance of massive forms of psychological power into our societal, cultural, and political background despite their ongoing creation of the world, to paraphrase Brian Arthur, is discussed in reference to David Harvey’s work on space-time relationships (Bourdieu’s symbolic violence might have found apt application here as well) and their ongoing compression through the transition to “flexible accumulation” and the “rapid deployment of new organization forms” and new technologies of production (Harvey, 1989, p. 284). This brings about the first point of contention I had with the authors’ approach and development of their argument. In Harvey’s The Condition of Postmodernity, flexible accumulation is said to accentuate the “volatility and ephemerality of fashions, products, production techniques, labor processes, ideas and ideologies, values and establishing practices,” perhaps acting as the groundwork for Deuze, et al.’s referencing of it as something of an origin for the fragmentation of self-identity that (ultimately/supposedly) leads to the “potential power of people to shape their lives and identities” to be found in the ever-evolving forms of media available amidst such precarity (Harvey, 1989, p. 285; Deuze, et al., 2012, p. 5). This suggestion that a life lived in media, that the media life perspective, offers some political, economic, artistic, or spiritual program of agency, expression, or self-realization contra the will of the market and in opposition to the logic of production will operate as the crux of my critique throughout what follows. Harvey’s employment of flexible accumulation doesn’t operate as a function in the formation of “fragmented identities” but rather an economic condition that begets “capital flight, deindustrialization of some regions, and the industrialization of others, the destruction of traditional working-class communities as power bases in class struggle” impacting everything from “local networks of influence and power” to the “accumulation strategies of ruling elites” (1989, p. 295). As flexible accumulation found new virtual materials of accumulation in the Digital Age, the precarity found in its nascent neoliberal form has been exacerbated due to the hyper-speed at which technologies of power have advanced and continue to accelerate far beyond our capacity of understanding, leading to what Baudrillard described as a crisis of explanatory logic (1986) and what Bernard Stiegler has simply described as disruption. Perhaps I included references to these thinkers and their decontextualized concepts primarily to highlight the hazy methodology of Deuze, et al. here and the occasional ineffectual nature of academic namedropping in advancing a point. Perhaps I just did it to be cool. Moreover, in a statement intended to align their scholarly approach with Harvey’s, suggesting that along with him, “we do not see people as hapless victims of this seemingly disjointed worldview,” I fail to see or understand how Harvey’s The Condition of Postmodernity distinctly participates in this notion. In fact, Harvey laments this disjointed worldview via the “fragmentation which a mobile capitalism and flexible accumulation can feed upon,” suggesting that it is difficult to “maintain any sense of historical continuity in the face of all the flux and ephemerality of flexible accumulation… [resulting in] the search for roots [ending] up at worst being produced and marketed as an image, as a simulacrum or pastiche…” (1989, p. 303).
While I know these authors are attempting to draw optimistic attention to the potentialities of individuation still existent through digital networks, their borrowing of Hjarvard’s notion of mediatization, suggesting that “media may no longer be conceived of as being separate from cultural and other social institutions” points to what I perceive to be the complete opposite outcome. The production of the self (and each other), as advocated by Deuze et al. in a compressed space in which the interweaving of simulacra into the quotidian forges a cohesive world of life and commodity such that it “conceals almost perfectly any trace of origin, of the labor processes that produced them, or of the social relations implicated in their production” renders any individuation of the self solely mobilized by invisible market forces (Harvey, 1989, p. 300). As I will touch on shortly, this degree of immersion in mediatization does not allow for resistance to anything but the outward protocol of these mediated structures of power, rather than addressing the way in which such protocol clandestinely sculpts life itself (Galloway & Thacker, 2007, p. 78).
Creativity
Deuze, Blank, and Speers, as they do throughout the majority of this piece, fluctuate between being on the mark and offering a hodgepodge of tech-optimism-somehow-effectuated-via-quotes-from-tech-pessimists. For example, the authors state, “When the organizing categories and principles of life are in constant motion, uncertainty reigns” (2012, p. 10). Though I would trace this uncertainty as leading that which was mentioned briefly above (i.e., the “perfected completion of nihilism” posited by Stiegler as being the effective accomplishment of computational capitalism or the hyperreality of Baudrillard – cool, huh?), the authors here, despite their acknowledgment (or celebration?) of the dissolving distinctions between man and machine, posit that a “life lived in media inspires a “creative” outlook to one’s world (2012, p. 13). Deuze et al. briefly root this force of creation in James Carey’s emphasis on “the ritualistic nature of the way people use media and technology to make sense of the world,” drawing the emphasis on this potential for creation away from the “categories of media production and consumption within the parameters of the capitalist project” and shifting focus to how such technology impacts the creative potentials of those interacting with that which is produced-from-above. However, if we are to understand rituals are symbolic acts that stabilize and structure time, then Deuze et al.’s subsequent advocacy for increased production via widespread multimedia literacy directly opposes this notion of the ritual. The “relentless consumption” of rapidly produced and disseminated media, such that we exist within it and are unable to notice, surrounds us with “disappearance, thus destabilizing life,” to borrow the words of Byung-Chul Han (2019, p. 4). Han goes on to note that “rituals produce a distance from the self, a self-transcendence,” rather than a production-of-the-self via “a life lived in media” as advanced by Deuze et al. (2019, p. 7). The authors’ arguments on behalf of data and information networks positioned through this piece that work to advance the necessity of engagement with media platforms in order to continue “existence in a networked digital age” not only negate the symbolic incapacity of such platforms to meaningfully bind people together (Stiegler’s symbolic misery, anyone?) and restore a solid structure to time, but also seemingly fails to recognize their political program is doing little more than advocating the melding of oneself into the digital under the “threat” (hyperbolic, sure) of nonexistence.
Perhaps the oddest element of this section is Deuze and friends’ awareness and inclusion of quotes from Alison Hearn, who suggests that “social media are forms of self-branding mandated by a flexible corporate capitalist project that ‘has subsumed all areas of human life…’”, and Zygmunt Bauman, who states that people “recast themselves as commodities: that is, products capable of catching the attention and attracting demand and customers,” and fail to do anything substantial with these provided frameworks of thought (2012, p. 18). Rather, the authors advance a “pull yourself up by your bootstraps” program to “take advantage” of the potential of creativity provided by the media and the golden possibility of sustained existence should one find success in doing so. To semi-conclusively return to Harvey, he states presciently in The Condition of Postmodernity, “Images have… themselves become commodities. This phenomenon has led Baudrillard to argue that Marx’s analysis of commodity production is outdated because capitalism is now predominantly concerned with the production of signs, images, and sign systems rather than with commodities themselves” (1989, p. 287). As Deuze et al. advance the mastery of creative production in opposition to the forces they seem so frustratingly aware of, one must recognize that that which is created through the “life lived in media” is little more than a baby gazelle being born under the gaze of a pack of lions. To paraphrase Gramsci, when incurable structural contradictions have revealed themselves (thanks Netflix’s The Social Dilemma!), and through their incessant and persistent efforts to maintain power despite the growing acknowledgment of their toxicity, a new “terrain of the conjunctural” will form, and “it is upon this terrain the forces of opposition organize” (Gramsci, 1971, p. 178). The terrain of resistance to the exploitative nature of digital capitalism can not be formed on the virtual terrain that such institutions have created and continue to maintain.
Selectivity & Sociability
For the sake of whoever has made it this far, I’ll condense these two critiques together and attempt to keep it brief. In their analysis of the ways in which social systems or institutions are depicted via the media, Deuze et al. note, “All institutions are dependent on societal representation… This means that an institution’s success in the media becomes necessary for the exertion of influence in other areas of society. Therefore, all functional areas within society have learned to look at themselves through media glasses” (2012, p. 20). Through a process of exaptation, institutions and organizations, regardless of their ethos, have adopted a methodological amalgamation of market strategies, public relations campaigns, and propagandistic approaches, prioritizing (by necessity) their status and position amidst digital networks to the same degree (or, perhaps even greater) that they must in the “real world.” Regarding the subsumption of societal institutions into the wider networks of media, the article does a great job detailing stances on the “non-neutrality” of such networks and their deindividuating effects, primarily through Bauman’s suggestion that “benevolent readings of networked potential of contemporary media life” can quickly lead one to engage in fallacious “internet fetishism (2012, p. 22) and Žižek’s (optimistically framed by the authors) “being together alone” (ibid, p. 23). Seeing as I have neither the blog-space nor the comprehensive understanding of networks as such to tackle each of the authors’ rattled-off references individually, I’ll briefly detail what I found in reference to networks in my readings of outside texts I came across in trying to grapple with the arguments presented here.
In Robert Hassan’s The Condition of Digitality: A Post-Modern Marxism for the Practice of Digital Life, the author resembles Harvey in his assertion that “there is no meaningful past or future in the network, only the digital present,” suggesting that such a resultant time-space compression (à la The Condition of Postmodernity), amplified by the hyper-industrial nature of capitalism and the culture industry, has destroyed the capacity of cultural signs and symbols to linger, producing what Han has described as serial perception, or “a constant registering of the new incapable of producing the experience of duration… instead rushing from one piece of information to the next” (Hassan, 2020, p. 174; Han, 2019, p. 7). Through this process, the marketization and distribution of commodified symbols are accelerated, creating a logic in which the aforementioned institutions and their associated cultural forms are “marked by an inherent lack of originality… where culture ‘eats its tail…”, creating an assimilated sameness that operates fluidly in an “Otherless” market – Han discusses this in The Expulsion of the Other (Hassan, 2020, p. 163). Considering this (and many more salient points made in this work that I won’t include here), networked systems of computational capitalism work to facilitate the flexible accumulation that Harvey described,” rather than to act as an element in the evolution of “media as a playground for the search of meaning and belonging,” as advanced by Deuze et al (2012, p. 5). Sure, networks might allow for novel forms of individuation and transindividuation across networked digital communities but there is no possibility of this occurring without such connections producing raw material for programs of virtual accumulation that allow for the individuation of the network as an entity itself.
So, what’s to be done?
As per usual; I dunno.
However, I did find and partially read a wildly interesting and topical book called The Exploit: A Theory of Networks that provided some unconventional approaches to addressing the issues at hand. To keep things short, I’ll provide a quote from the work rather than trying to slyly incorporate it into a greater discussion:
“When existence becomes a measurable science of control, then nonexistence must become a tactic for any thing wishing to avoid control. ‘A being radically devoid of any representational identity,” Agamben wrote, “would be absolutely irrelevant to the State.’ Thus we should become devoid of any representable identity. Anything measurable might be fatal. These strategies could consist of nonexistent action (bonding); unmeasurable or not-yet-measurable human traits; or the promotion of measurable data of negligible importance. Allowing to be measured now and again for false behaviors, thereby attracting incongruent and ineffective control responses can’t hurt. A driven exodus or a pointless desertion are equally virtuous in the quest for nonexistence. The band, the negligible the featureless are its only evident traits. The nonexistent is that which cannot be cast into any available data types. The nonexistent is that which cannot be parsed by any available algorithms. This is not nihilism; it is the purest form of love” (Galloway & Thacker, 2007, p. 136).
I found this bizarre, Schopenhauerian “denial-of-the-digital-will” approach to becoming-through-a-digital-unbecoming to be totally fascinating. As Thacker and Galloway later note, John Arquilla and David Ronfeldt, the prescient authors of Networks and Netwars, once noted that where programs of resistance once focused on “bringing down the system,” many current network-based political movements have shifted their focus to developing and maintaining connections, to hyper-communication via “a life lived in media” rather than on addressing material mechanisms of control. Much in the same way Deuze et al. advocate for individuation through media forms, Thacker and Galloway note that networks are similarly continuously expressing their “own modes of individuation, multiplicity, movements, and levels of connectivity,” developing with a rapidity that the human is increasingly surpassed by, creating a sense of malaise, impotency, and disempowerment. As Nietzsche notes (since the authors also enjoyed employing his thought in their finale), mankind has always “mercilessly employ[ed] every individual for heating its great machines,” degrading him to a mere “instrument of general utility (Nietzsche, 1986, p. 585; 593). Perhaps continuing to operate these networked machines, despite the different attitudes, protocols, and programs applied from-within in an attempt to simultaneously resist and exploit the digital tools afforded to us via media, does not offer the effective, fulfilling means of self-creation that the authors suggest? Perhaps the tech-pessimists and network-skeptics Deuze, Blank, and Speers reference throughout this piece have more to offer than whatever point it is that they are really trying to get at? I’m not sure. However, to “round out” a quote from Thacker and Galloway used above (as a Deleuzian motion to “look for new weapons“);
“The set of procedures for monitoring, regulating, and modulating networks as living networks is geared, at the most fundamental level, toward the production of life, in its biological, social, and political capacities. So the target is not simply protocol; to be more precise, the target of resistance is the way in which protocol inflects and sculpts life itself” (2009, p. 78).
References
Baudrillard, J. (1986). America. Verso.
Deuze, M., Blank, P., & Speers, L. (2012). A Life Lived in Media. Digital Humanities Quarterly, 6(1).
Galloway, A. R., & Thacker, E. (2009). The Exploit: A Theory of Networks. University of Minnesota Press Minneapolis.
Gramsci, A. (1971). Selections from the Prison Notebooks. International Publishers New York.
Han, B.-C. (2019). The Disappearance of Rituals: A Topology of the Present. Polity.
Harvey, D. (1989). The Condition of Postmodernity: An Enquiry into the Origins of Cultural Change. Wiley-Blackwell.
Hassan, R. (2020). The Condition of Digitality: A Post-Modern Marxism for the Practice of Digital Life. University of Westminster Press.
Nietzsche, F. (1986). Human, All Too Human: A Book for Free Spirits. Cambridge University Press.