The first time I came across the topic of public humanities was by reading the book Doing Public Humanities edited by Susan Smulyan. I learn that public humanities happens in collaboration and engages diverse public audiences. But as put by Robyn Schroeder in “The Rise of the Public Humanists,” digital technologies could be seen as disruptions that “have undermined the traditional source of authority for researchers and archivists.” (20) Fitzpatrick’s proposed ideas in “Working in Public” encourages me to think further how to engage openly and explore widely together to create, support, and promote projects/works toward the public good, particularly in a digital age.
The most complex challenge in doing generous thinking I learned from her writing is understanding and balancing the interests of diverse and sometimes even competing stakeholders within and outside of your fields/organizations and facilitating good conversations. Coping with uncertainty and unfamiliarity in conversations and collaborations is undoubtedly not easy. In the session on public access, she mentions the advantages of OA journals (which I read further explanation in Suber’s piece “What Is Open Access?”). She uses OA journals in science as good examples that help sciences progress. And systematically speaking, publishing costs are also said to be included in grants in the sciences, which aims to promote knowledge transmission and public engagement. However, I also see difficulties in balancing interests in the OA publishing in science. There is an article titled “Why I think ending article-processing charges will save open access,” published last week in Nature written by Juan Pablo Alperin.
Alperin explains how difficult it is for Latin American scholars to publish in well-funded top journals in Europe and North America due to increasing APC (Article processing charges) payments. I learned from scientists I follow on SNS that they currently need to pay around $4,000-5,000 for the APC per article. Scientists could pay the APC from their grants, and as Fitzpatrick writes, “those tenured, and tenure-track faculty and other fully employed members of our professions who can and should contribute to the world the products of the labor that they have already been supported in undertaking.” (157) But there is also the issue of geographical inequalities, even among tenured faculty and schools. Thereby, I am excited to find out that Fitzpatrick also addresses “the dominance of standard English” (164) in this chapter. Echoing her, I also think translation works are not valued enough as scholarly contributions. And ultimately, I ask for a critical reflection on how the world beyond the US’s boundaries is taught and learned and how we could combine the DH and regional studies to help the students/the public understand the rapidly changing world. Geographical inequalities, as well as inequalities in race, gender, and age, requires us to consider general questions like the role of public intellectuals but also look into some invisible questions regarding capabilities in utilizing technologies during the development of technologies, as addressed by Risam and Gil in “The Questions of Minimal Computing.”
And lastly, let us revisit the idea of public intellectual and public scholarship. Speaking and writing to the public is not enough to become a public intellectual. I notice some scholars do public scholarship by formulating their beliefs and arguments on fighting against what they oppose. However, some fail to discover what they inherently support and give good guidance in questions outside their disciplines but relate to global social and cultural issues. I would argue for consciousness and self-awareness in the process of producing public goods
Last month, I attended day two ofUnfinished Liveat The Shed in Hudson Yards, an event that, in its own words, “brings together leading thinkers and changemakers from a wide variety of disciplines to engage in today’s most pressing questions about the impact of technology on our civic lives.” Though it wasn’t necessarily a Digital Humanities workshop focused on the development of a particular skill, Unfinished Live offered a series of lectures, discussions, interviews, and forums dedicated to illuminating the past, present, and future of ongoing tech-centric conversations pertaining to everything from tech careers after incarceration to the potential for subversive feminist art and activism via emergent Web3 technologies. With the speakers including a variety of digital artists, tech theorists, crypto-evangelists, and venture capitalists, Unfinished Live offered a mixture of diverse insights into the state of Big Tech (for lack of a better term) and the attitudes that exist both within it and on its fringes. Though day passes were exorbitantly expensive, likely prohibiting many of the discussions from reaching the people they were seemingly intended for, I was able to attend thanks to a student discount available in a forwarded message from Unfinished Live representative Rebecca Turner via email-wizard Jason Nielsen. Through this reflection, I intend to briefly highlight the events that I attended and their relevance to the Digital Humanities, followed by a critical analysis of one panel in particular in an attempt to evaluate the motivations, ideologies, and financial incentives at work beneath its seemingly benign and egalitarian exchanges.
My experience at Unfinished Live began with a panel discussion titled “The End of Tech Feudalism: Rethinking the Internet’s Balance of Power” hosted by founder and editor-in-chief of blockchain news organization Forkast, Angie Lau. Starting with a spurious anecdote by Tomicah Tillemann, Chief Policy Officer at recently founded crypto-investment firm Haun Ventures, detailing his 17th-great-grandfather’s life during the feudal age and the ways in which it mirrors our present era of Tech Feudalism, the discussion soon blossomed into an exposition of the ways in which Web3’s decentralized structure can work to emancipate digital serfs from their tech overlords. Niki Christoff, a former Republican operative and current CEO at Washington-based boutique consultancy Christoff & Co., and Dante Disparte, Chief Strategy Officer and Head of Global Policy at peer-to-peer payments technology company Circle, joined the stage as well, each offering their vision of freedom from the confines of Web2 through political and economic programs that were coincidentally beneficial to their company’s advancement. Though this panel was initially intriguing and appeared to align with that which I had hoped to find at such a conference, the discussion quickly evolved into something else entirely, thus prompting my desire to dissect the underlying dynamic of this event as I make an attempt at doing below.
Following this provoking introduction to the conference, I attended a panel titled “The ‘Trustless” Trap: Why a Responsible Web3 Needs a Bit of Messy Humanities” that worked to counter Web3 enthusiasts’ rallying cries of “just trust the math” and advance the still-existent value of trust in programs of human-centric transparency, inclusion, and governance against the desires of accelerationists and automaton advocates. Though informative to some degree, the loosely moderated discussion quickly turned its focus onto that of NFTs, which, admittedly, I have little interest, before once against turning to the necessity for the proactive trust and safety measures necessary in the emergent technologies of Web3. Perhaps the most interesting element of this discussion was that of the decentralized community’s right in the creation of norms and who has the right to create such norms if not the community. The government? Corporations? Some other entity? The conversation that followed grew into a discussion of the role of regulatory government intervention in the growth of emergent technologies (one panel member advocating the creation of an equal floor, rather than a ceiling) which was countered by arguments regarding the government’s inability to keep regulatory pace with such developing technologies. Executive Director of Internet Without Borders, Julie Owono, concludes the discussion by asking the ever-salient question, how do we design rules that touch everyone equally and create a sense that those touched by them had a hand in their development?
Shortly after, I attended “Building the Web We Want: How to Protect Human Rights on the Internet” featuring Research Manager at The Markup, Angie Waller, and Ben Moskowitz, who acts as Vice President at Innovation Lab. Out of the three “main events” that I attended, I probably retained the least from this panel, as questions such as “How do we protect speech and privacy?”, “How can we create a more equal global society where the disadvantaged are not further marginalized?”, and “How can we ensure that those with power don’t silence the more vulnerable among us?” are much easier to ask than they are to answer. Though associated problems were rightfully and skillfully addressed, I found that some of the “answers” provided were doing little more than semi-tackling behaviorally targeted information, advertisements, and propaganda found on Facebook, something that has long been subject to discussion and is anything but innovative in such a technologically-forward-thinking space. However, I did find Moskowitz’s notion of a “consumer data union” and the collectivization of data-subjects to reposition power into the hands of those who are producing the data to be wildly interesting, and was disappointed that these two speakers exited the stage shortly thereafter with little elaboration. This was followed with a great deal of moseying, a beer drank at the downstairs bar, and a few books purchased at a kiosk displaying works written by figures featured throughout the conference, each of which still sits cozily on my shelf with unbent spines.
So, returning to “The End of Tech Feudalism: Rethinking the Internet’s Balance of Power,” I’d like to first discuss the elements of the panel discussion that left a sour taste in my mouth and why I felt compelled to dig into the lives and professional breadcrumbs of this merry band of technocrats. Since the cast of characters has already been somewhat established above, I’ll briefly give an extended overview of each as to contextualize these figures within the economic and political landscape. Venture capitalist Tomicah Tillemann stood out initially, due in part to his recounting of the night before and his namedropping everyone from Pussy Riot’s Nadya Tolokonnikova to Hilary Clinton. Tillemann’s background is impressive, previously working as the Global Head of Policy for the crypto team at Andreessen Horowitz, once serving as senior advisor to two Secretaries of State, and working in the State Department in 2009 as Hilary Clinton’s speechwriter. On the panel, Tillemann is the first to draw an equivalence between the farming implements of feudalism and the “modern digital equivalence,” gesturing to his phone and suggesting that, similar to his 17th-great-grandfather, we “go to work creating valuable digital data,” sending it up to “manor houses” in Silicon Valley to “cultivate a landscape that we do not own and we will never control.” Tillemann follows this metaphorical framework, suggesting that feudalism ended through a series of systemic, exogenous shocks, such as plague and conflict, and, given the state of the world today, we are offered an unfortunate but potentially hopeful opportunity to develop new ideas that produce novel infrastructure and new mechanisms that uproot the dynamic presently in place and allow for a “new renaissance” that mirrors that which followed the original end of feudalism. Nodding in agreement, moderator Angie Lau turns to the crowd to ask, “How many of you feel that we are digital commodities?” to a small swell of murmurs.
Responding to Tillemann, Niki Christoff states that she “doesn’t believe Silicon Valley” intended to be malicious in their development of the present economic situation in which our “information, data, attention, privacy” is exploitatively and elusively extracted, proceeding to lament to her feeling of being held hostage by her phone and suggesting that through blockchain technology, there exists the possibility of a “new internet” that “moves power from consolidated multinational companies” back into the hands of the masses. Somewhat similar to Tillemann, Christoff has had a prosperous career in Silicon Valley prior to her appearance at Unfinished Live, including a spokesperson role at Google and Head of Federal Affairs at Uber, during thelatter of which she is quoted in countless articles for her praising of Trump appointed Transportation Secretary Elaine Chao due to her alignment with labor regulations that benefit the gig economy. Marking the beginning of a pattern that will exist throughout the duration of the panel, Christoff, notably named by Fortune in 2019 as one of the 25 Most Powerful Women in Politics, is the first to introduce leftist language into the dialogue, stating, “To have a revolution, you can’t a small group of elites talking about a concept… You need to have masses that are demanding an end to the system.” Ironically, this statement is voiced by a small group of elites, offering an answer to the masses that bears both the potential to concomitantly “end digital feudalism” and line their pockets and those of their company’s shareholders. Rather convenient, no?
Dante Disparte responds in kind, suggesting “…to end feudalism, [people need to be empowered.] I believe there is no greater representation of empowerment than financial empowerment. The biggest revolt that the emergence of cryptocurrencies has caused is a revolt against some deeply entrenched interests… Cryptocurrency is a response to failures within the traditional economy.” More than anyone, Disparte’s involvement in the conversation illuminates what might be said to be its truest intention; to encourage the public to view financial investment in their crypto-programs as emancipatory, revolutionary, and politically empowering. In a similar vein, Tillemann positions this technology as an escape from the entrapment of tech as binarily existing in either an authoritarian or commercial framework while Christoff suggests that through such tools, people can “govern themselves” and subsequently “save democracy.”
As I sat in the dimly lit room, gazing on a beautifully arranged stage featuring some of the “top minds” supposedly at forefront of the next era of technological advancement, such calls for the end of tech feudalism that I would otherwise recognize as urgent and fundamentally agree with started to appear more and more as an advertisement for the ideologies and technological programs inherent in the organizations that these three individuals represent. During Tillemann’s Time at Andreessen Horowitz, the aim was always “how to win the future,” not how to benefit the masses that are being swept along with the technological blitz being orchestrated in order to achieve this “victory.” At Andreessen Horowitz, a company that is as well known for its early investments in companies such as Facebook and Twitter as they are for being uncooperative and opaque with the media and the public, Tillemann’s career started when he was brought on by crypto-investor Katie Haun, who was at the time tasked with spearheading Andreessen Horowitz’s lobbying effort in Washington. Now, Haun and Tillemann are reunited at Haun Ventures, an investment firm focused on crypto start-ups, with Tillemann simultaneously taking speaking gigs touting their power as political solutions to the malaise and exploitation of hyper-industrial society. Similarly, Disparte’s role at Circle is explicitly dedicated to eliminating friction in the flow of value globally. In other words, Disparte is advocating greasing the wheels of unregulated, unfettered capitalism, under the guise of guaranteeing “instant, permissionless” financial freedom should one invest in the future that blockchain technologies promise. And lastly, Christoff, describing herself at the tail end of the panel as “a radical and an institutionalist,” suggests that this is all aimed toward building “access to the global economy” and works to ultimately ensure that no one is left outside of such financial infrastructures. Who would not want to be touched by the loving hand of global technocapitalism?
Each of these figures, in some way, has built and benefited from the exact systems that they now describe as tech feudalism. Each of these figures, in their own way, now offers a “solution” to the exploitation that is inherent in the structures they worked to produce. Each of these figures has untold capital invested in these “solutions” and is scrambling to be at the forefront of Big Tech’s next set of elite organizations as Web3 technologies emerge and develop. Though I’ve gone on for far too long at this point, the takeaway from this analysis should be evident. And perhaps it already was and this post is wholly unnecessary. However, as Digital Humanists, the tech optimism of Silicon Valley or its defectors should always be approached with a healthy degree of skepticism and analysis. I suppose this, in some way, operated as a workshop for this critical approach, and a reminder of the ways in which the technological landscape differs from that of the Digital Humanities and what our role as Digital Humanities is within this landscape to counter and critique that evolving faces of new technologies of power.
Access to knowledge and technology was a common theme in the readings. It sparked a curiosity about Open Access and Open Educational Resources. Currently, at LaGuardia Community College, my colleagues are working on an OER project (Open Educational Resource). In a short interaction while at work, I briefly mentioned that I was learning about Open Access in my weekly readings. My colleague invited me to see a current OER project they are working on. Without really getting into details about my readings, the first thing they said was that they needed to figure out what platform they were going to use. Some factors to consider were cost, accessibility, and user experience. I immediately thought about the four heuristic questions in Introduction: The Questions of Minimal Computing. I especially thought about this question. “What do we have?”
“what do we have.” – CUNY Pressbooks.
Based on my conversation with my colleague, they used Pressbooks as the OER platform to create this project. Based on my understanding, I learned that CUNY has a subscription to this platform. I also learned that a team is behind this project, from professors to students. A grant is funding this work. Therefore, they can compensate students for their time creating content for this OER project.
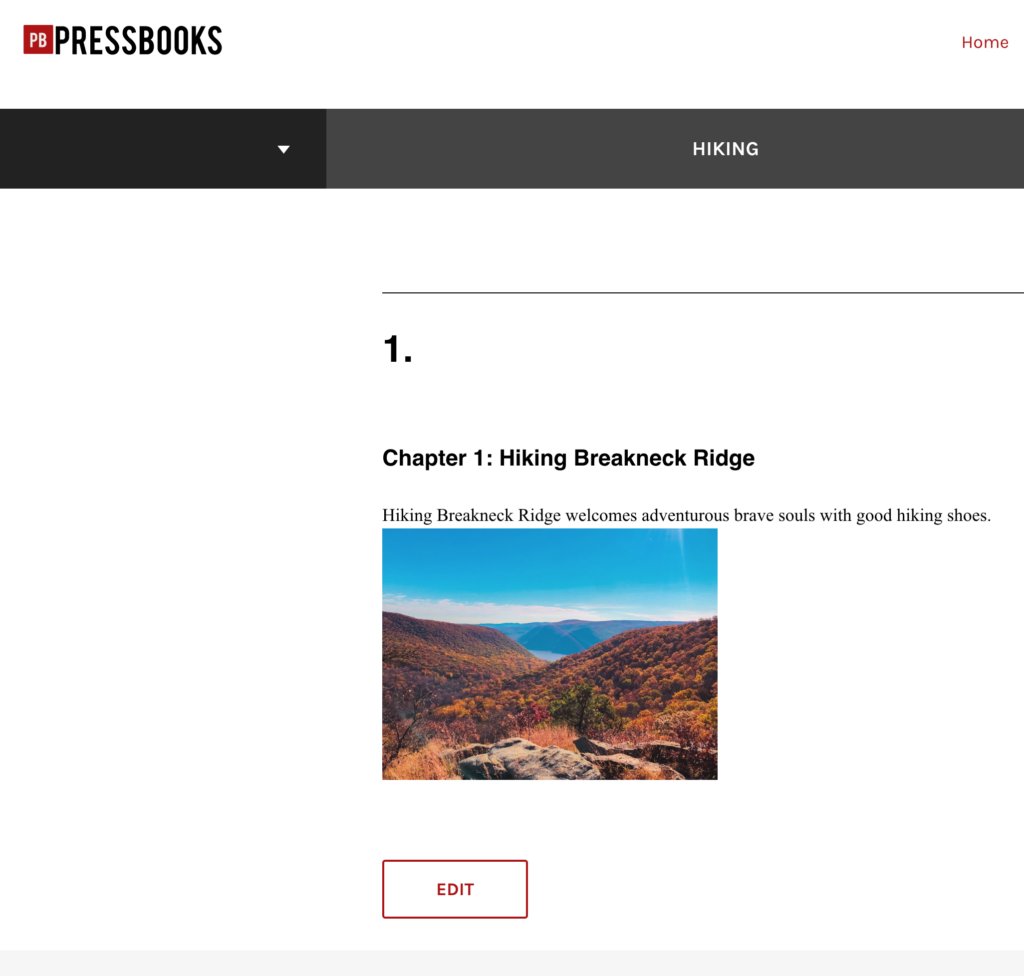
I decided to create an account on Pressbooks and play around with the platform. I decided to “create” my first book titled hiking. It’s similar to word press. It has some book themes to choose from. I needed more time to learn about the features and tools on this platform, but it seemed straightforward and user-friendly. For practice, I decided to create a book called “Hiking.” I love hiking and spending my weekends year-round (weather and time permitting) in the mountains of the Hudson Valley and surrounding areas. I created a chapter called Hiking Breakneck Ridge, one of NYS’s most challenging hikes.
Who can afford $100+ Textbooks?
While playing around with the platform, I was thinking about textbooks in the sciences that are constantly being updated. Therefore, the content in the textbook in one year can be different the following year due to new scientific discoveries.
I think it’s ridiculous that students have to pay $100+ for a textbook, especially if they are going only to use it one time. However, I think we now have a solution for that. These platforms and OER projects allow for sharing knowledge with students and the public interested in a subject/topic.
How can OER textbooks and learning material support student success?
I think that OER textbooks and learning materials can support student success by alleviating this cost burden to students. Students shouldn’t be stressed by deciding to buy a textbook or paying for rent or their living expenses. They can instead use the money for their living expenses. It’s already expensive to live in the states. If OER can alleviate that stress, I think we need to move towards an educational system that will support all students to succeed by providing the materials necessary to achieve their goals and success.
This week’s reading, more so than other weeks, has been well aligned with many of the interests that brought me to study the digital humanities. I have been a long-time proponent of open access journals — as well as open access media in general. I thought Peter Suber did a wonderful job in outlining all the benefits to open access research articles and tackled all the tough questions that often go along with it. One of the many critiques I’ve stumbled across when it comes to OA is how it removes labor from the process of publishing academic articles. That is, by eliminating the process of sales, you eliminate the job of selling the literature. By eliminating the publisher as middleman, you eliminate the copyeditor, the proofreader, the production team, etc. from being involved in the process of creating a published work. That is, OA can be deemed “anti-labor” inherently by its removal of roles from the publishing process. I learned many retorts to this line of thinking from Suber — mainly that OA works can still live in published journals. They can still be refined and sold as parts of collections. It’s just that the written piece, in isolation, can be accessed by anyone. Much like public domain works of literature (those that predate 1923) are available to be published in anthologies or critical editions of books — which produce many jobs and are certainly pro labor — OA works can be included in their own anthologies and classroom “readers” to create new labor opportunities. I found this uplifting as a lot of what we read in DH is riddled with guilt — guilt about who DH doesn’t serve, whose voices are omitted from the field, and who cannot access the digital tools that are prerequisite to making a DH project. That brings me to my thoughts on the Risam and Gil piece on minimal computing.
I titled this post “Minimal Computing and Cyclical Guilt in DH” because after reading the Risam and Gil piece, I felt like I was taken on a whirligig tour of all the ways that digital tools can exclude different populations. SaaS GUIs require an internet connection and thus are only available to users who live in well connected areas of the world. User-friendly tools often are hosted on databases, which presents security problems as these databases are often owned by capitalistic corporate entities. I felt from reading the piece that the authors were advocating for minimal computing as a solution to these problems — but even in their writing, you could sense there was more guilt underpinning the concept of minimal computing.
To truly leverage the benefits for minimal computing, they make clear that a strong grasp of coding language is required. Making a Jekyll site is often achieved through the command line. This is a large learning curve for many. I’ve been working adjacent to computer science for over a decade and anytime I want to learn a new skillset, I have to take advantage of one of several pillars of privilege. I can take a class at an institution, which costs money and often requires being accepted into a program and having an expensive undergraduate degree. Alternatively, I can attend a bootcamp, which costs even more money per hour. If I want to save money, I can watch tutorials on YouTube, yet they require all the same connectivity as using a SaaS GUI does, which defeats the supposed altruistic purpose of learning the code if I can just use a GUI. I can purchase a textbook, which is probably the cheapest route, but it’s still expensive and I will have to rely solely on my ability to self-learn. There are dozens of other ways to gain these skills, but all of them require some form of privilege — not excluding the privilege of being smarter than I am and being able to learn complex syntax very easily — as many lucky software engineers are able to do with their computationally savvy minds.
I feel like it’s impossible to learn about any aspect of DH without going down the rabbit hole of guilting ourselves about how any approach to scholarship inherently leaves out a large chunk of the population. Studying advanced mathematics leaves out people who aren’t inherently skilled at math. But I don’t think that’s much of a topic in the introduction to linear regression. To me, minimal computing is dope. It’s cool to make lo-fi digital projects using simple forms of technology. I don’t think the reason to promote this approach to scholarship requires us to go over how WordPress is a product of neocolonialism. I feel like there’s no need to justify minimal computing — it’s justified in the fact that practitioners are able to create interesting humanities projects without relying on the hand-holding GUIs available to the greater public. That in that of itself is interesting.
A very short preface: My work schedule this semester makes attending the workshops focused on digital skills impossible, so I am especially grateful to all of you for sharing your thorough workshop descriptions! Thank you. Consequently, the workshops I actually CAN attend seem a little further afield. When choosing a session to attend, I am trying to find the sweet spot in the Venn diagram of my availability, my interests, and DH usefulness.
With that in mind: I took a workshop offered by the Gradcenter’s Writing Center (I work at a writing center at another institution) on responding to CFPs (Calls For Proposals or Papers)/ writing a conference abstract.
Overall, the workshop took the mystery out of the CFP process and made me think that any one of us with an idea that aligns with a conference’s theme should dare to go for submitting a proposal (in the form of an abstract).
There are several kinds of conferences: (and you’ve probably seen some asking for proposals in the emails Jason shares with us, most recently HASTAC)
sponsored by grad schools
regional
national (and international)
The two instructors agreed that going to a grad school-sponsored conference might be a great initiating experience.
The bulk of the session was then devoted to looking at dos and don’ts of abstract writing as well as looking at a couple of example abstracts. Below, the essentials.
Your abstract is written in response to a specific conference’s theme. Showing how your idea connects to the theme is vital. The theme is certainly recognizable in the conference’s title, but you might also look for and define the “key terms” the CFP identifies (see second slide) and refer to those terms as you describe your planned contribution. Defining your contribution’s place in the often suggested sub-themes and locating the available formats should also be part of your considerations. Formats might be round tables, panels, seminars, workshops, etc. — they all suggest slightly different approaches to your idea.
Here a concise summary of what an abstract should do (the two images are screenshots of slides from the workshop):
…and all of this in an allotted word limit of 200, 300, 500 words (there is a spectrum, but short is the defining feature).
And here the dos and don’ts, which I think are a useful checklist for your abstract-in-progress:
The presenters also made a point of mentioning that even if you write a great abstract, your proposal might still not be chosen, as there are additional “uncontrollable forces” involved in the selection process. The selection committee has to consider the overall-make-up of a panel or round table, so sometimes, in order to achieve a balance of perspectives and subspecialties, some great proposals might not make it.
From my work as a writing consultant, I’ll add the following:
Sounds simple, but still: Close read and return to the CFP a few times as you are consolidating and developing your thoughts.
And: take advantage of the Writing Center and bring them your draft in progress to get an outside reader’s input.
Also: feel free to contact me with any abstract-related questions anytime.
…. and please share info about upcoming conferences.
I attended the workshop “Git It: Intro to Git and GitHub” taught by Nicole Cote. It was super helpful. Below is the process and reflection about it.
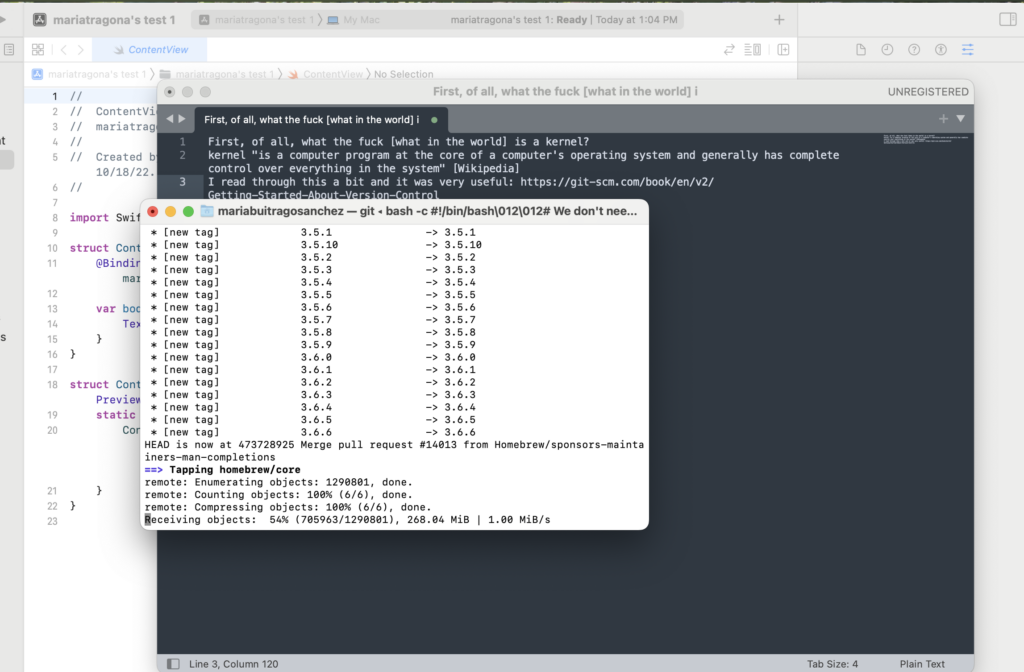
Figure 1. Screenshot of the download process of Git. “What in the world is a Kernel?“. The first thing we needed to do to complete the workshop was, of course, to download Git and create a free account on Github. I stumble upon many troubles and questions, specially regarding terminology.
The first steps with Git and Github are, of course, to download the program and create an account on Github. However, to be able to interact with the program and with the local versions of your files you previously need to have installed a coding program like Sublime, Virtual Studio Code or Xcode. Then, you need to select a way to download Git, there are several options, I tried (for reasons unknown to myself) several. In the end I did the homebrew option and ran it through my terminal. Then, the program kind of just goes on its own. It was all very confusing and intimidating at first so I had to watch several videos on how to do it. The most useful one was this one. The guy goes straight to the point (unlike so many others!) and even helps you setting up a ‘Personal Access Token’ without which I just couldn’t do anything on my Mac (again, who knows why).
Once able to download everything you’ll need to connect the local files with the repository you created online, or rather vice versa. Nicole walked us through how to do this step by step, which is sort of easy. You just create a new repository on Github and copy the URL of the ‘README’ file into your terminal. The repository has a specific or, rather, a basic structure so, at least to my understanding, there will always be a “README” file. But you paste the URL of the ‘README’ only once you’ve configured your git name and email on your terminal. Nicole also explained the most important and basic terminology that we absolutely need in order to create the communication path between local files and Github. She explained terms like ‘repository‘ which I understood as another word for where you save all the files of a project or simply a ‘folder‘; also terms like ‘Fork‘, ‘Branch‘, ‘Pull Request‘ and ‘Issue‘.
Figure 2. Screenshot of another issue that reads: “Fatal: Authentication failed for …” which was resolved creating a ‘Personal Access Token’ but I don’t know why.
After reviewing the terms, we started our own test repository and try some Git Commands. I had to repeat this several times on my own until I actually could do it with some ease. And then, I started to make changes to the file on my computer and pushing the changes to Github repeating the following commands like a mantra: “git status/ git add README.md/ git add –all/ git commit -m “new” and so forth and so on, again and again and again. However, I must say that Git tends to tell you all the time and suggest to you if you’ve done wrong something or if the command has any typo, and tells you a possible option or solution, which helps a ton. I also read some of the material available on Git to understand Git, which you can find here. And also used this guide for the basic elements of Markdown files.
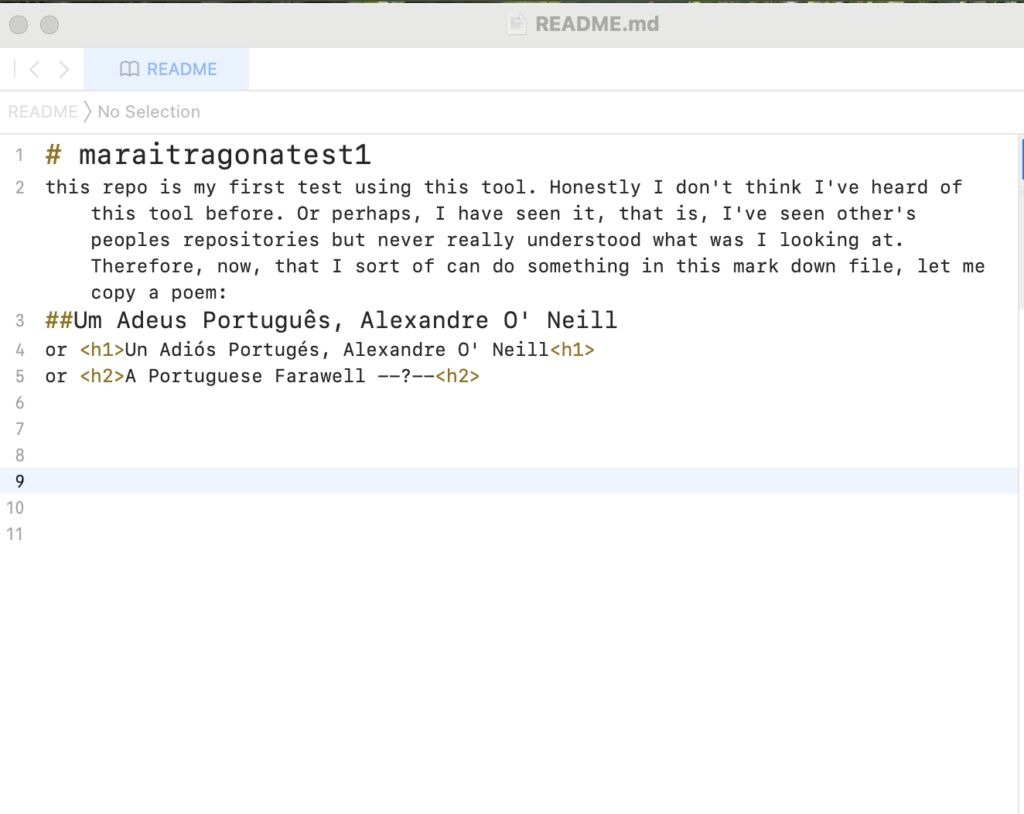
Figure 3. Screenshot of the README.md file that I continuously pushed to GitHub, but one can also just edit directly in GitHub.
I decided to copy/past/interact with a poem just because, and ended with this README.md file on the test repo. After trying GitHub I do think is a great tool to track the multiple changes one does to a file/project, and is especially helpful if many people are collaborating at the same time. One thing I found very interesting is that the way the tool is built allows for collaboration that could be more horizontally oriented, so everyone can share their edits/opinions on a given project and all, at least in theory, are deemed equally important. Another feature is that other people can interact with your repo and raise an issue about changes they would like to suggest, furthermore they can clone your repo to start a similar project on their own. Thus, seems like knowledge shared on GitHub can be spread widely to different audiences rather than if you just store your projects or files in other places/websites/digital spaces where no one can comment or alter. I absolutely learned a lot through this process, for example now I have a basic idea of what’s the difference between a ‘Centralized Control System’ vs a ‘Distributed Version Control System’ like GitHub. And, honestly, I’m not sure anymore how I stumble upon the word kernel…maybe is just my plain ignorance but I was never ever introduce to any of this vocabulary. Which is terrible. This tool made me realize (again) how far the people that graduated from the humanities, like me, are to this terms. And that is so unjust and irritating if we consider how key this vocabulary is to understand the mechanisms by which our current world functions. And to realize (again) how compartmentalized our disciplines are is kind of sad; each creates its own set of terms and sophisticated vocabulary that ends up being nothing but a condense and rigid wall through which none but the ‘experts’ can penetrate and have a say.
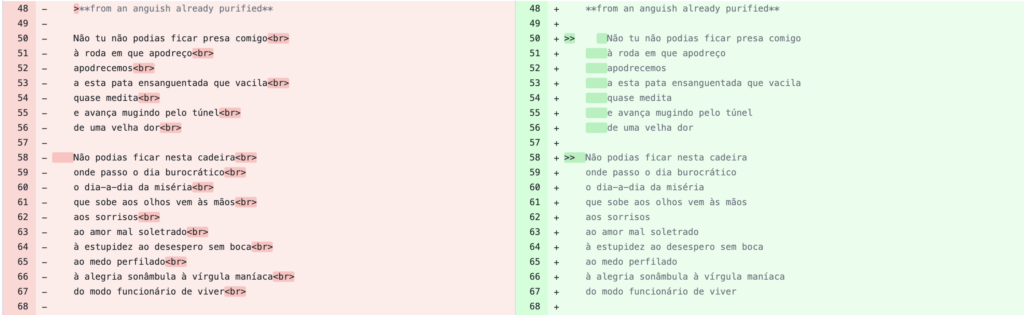
Figure 4. Screenshot of the different versions of the file in GitHub
Anyways, it was fun to see how in fact you actually can review side by side (figure 4), track, and go back to previous versions of your files. While copying the poem I realized how great it would be for translators and creators to have different version of a same literary work, to be able to branch a file to create multiple word choices and have others comment on it or if there’s a work of fiction to have different passages and compare them side by side, seems so cool, at least in theory.
There’s so much more to learn and so much that I still don’t understand. So many questions.
Today, I attended the workshop lead by Anthony Wheeler, Commons Community Facilitator along with Prof Tom Peele, Director of FYW City College and Stefano Morello, CCNY Digital Fellow. The workshop was recorded and I believe will be shared on the Commons, I was one of only 2 attendees and have permission from Anthony to share the recording below with our class. I am still figuring out the incredible amount of information and platforms that I have been exposed to in the past 2 months and this workshop was super helpful in understanding a bit about the Academic Commons and what it offers in regards to student portfolios. Anthony also shared some portfolio links that I have included below.
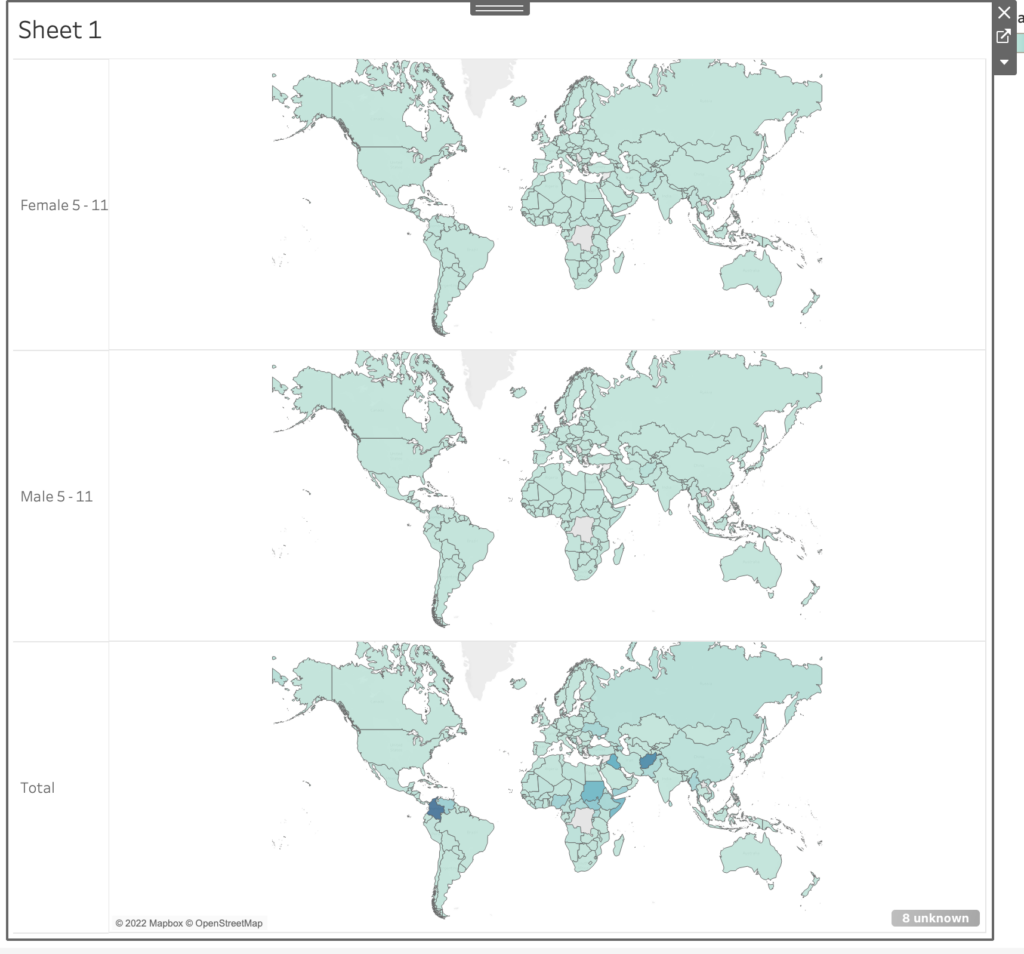
My mapping assignment has been a winding road passing many villages of programs to get to the goal of a map. When I first thought about the assignment, my first idea was to think of mapping the immigrant community in NYC by zip code with layers of supermarkets in each zip code with layers of farmers markets and community gardens in each area as well. The idea was to show the preponderance of food deserts. I started my journey by going to QGIS which I understood to be the standard. After an hour with the program, I realized that the learning curve was too steep for me. I went over to Google Maps, which was unappealing. I finally settled on Tableau. After watching about 6 YouTube videos on learning the basics, I felt I had an idea on how to proceed. I started looking for datasets to input or connect to Tableau. I ran into some issues as to finding the datasets I was looking for. Finding the data was challenging as there wasn’t one place for me to gather what I was looking for, so I decided to go to the UN as it was one location that was organized. I changed my topic to the number of refugees worldwide and downloaded datasets about that. The dataset was overwhelming as it spanned years and had a very large subset of categories. I tried to work with what I had but ran into many issues. I even stripped the data to only include one year but still got stuck on how to proceed. This is when I reached out to Filipa who was extremely helpful and patient. She said she would learn Tableau to help me out! Something I said would not be really necessary as I can ask for another tutor, but she did it anyway. Not only that, but she went to the UN site and retrieved a dataset that was much more different than mine. What she showed me was that my original dataset was incomplete in some ways and too much in other ways. She also showed me how to be extremely selective in choosing the dataset for mapping. From there, she helped me to fine tune the map I started with. This became the present map that I share with the class. It is a map, actually 3, of refugees in the world in 2021: 1 is the total number in each country; one is the number of females 5-11 years old; one is the total number of males 5-11 years old; and the last one is the total number of all refugees. It was exciting to finally get a finished project. Although it may be finished for the assignment, I’m intrigued to see how I can add one or 2 more layers to the map. Perhaps the number of organizations helping in each country or the number of asylum seekers that are accepted in each country from the refugee pool or the average number of years that each has been a refugee. This is a strong skill to have acquired. I easily can see so many possibilities for it.
This weeks readings centered around Open Access Publishing/ Minimal Computing / Digital Scholarship lead me down a path (or rabbit hole:-) where I ended up focusing and thinking about open access and minimal computing as we head towards a decentralized version of the internet.
When we speak of knowledge production, we no longer speak simply of the production of documents. We include the production of data, data sets, and documents as data, all of which can be used for algorithmic analysis or manipulation. The issue of control over data sets, especially those that can inform the pasts of whole demographics of people in the world, will certainly come to a head in the 21st century. One example of danger is control over Black data. At the moment of writing, the vast majority of the data and documents that help us understand the history of Black people during the period of Atlantic chattel slavery are controlled by predominantly white scholarly teams and library administrators or white-owned vendors.[15] This demonstrates how access to infrastructure has direct consequences on our study and reconstruction of the past and, by extension, what we understand that past to be. While data reparations must be made, our interest here is in the role that minimal computing can play in the development of present and future data sets, documents as data, and methods that promote collaboration and interoperability among colleagues around the world by not only taking into account uneven distribution of resources and the constraints with which the majority are contending but also by ensuring that control over the production of knowledge is in their hands.
In the article minimal computing the authors touch on previous discussions and articles we have read in class about the creation, curation and control over datasets by those the data and histories are about.
We’d have less knowledge, less academic freedom, and less OA if researchers worked for royalties and made their research articles into commodities rather than gifts. It should be no surprise, then, that more and more funding agencies and universities are adopting strong OA policies. Their mission to advance research leads them directly to logic of OA: With a few exceptions, such as classified research, research that is worth funding or facilitating is worth sharing with everyone who can make use of it.
Open access and freely sharing research and information to help us understand ourselves, others and the world is a foundational aspect of DH. I started thinking and reading more about this topic in a broader sense and how open access has and will shape our experiences. I wondered about what open access with the onset of web3 looks like and found some sites that are interesting and read an article about what web3 could mean for education.
https://okfn.org Our mission: an open world, where all non-personal information is open, free for everyone to use, build on and share; and creators and innovators are fairly recognised and rewarded.
https://www.fwb.help Our Vision: We believe that Web3 has the potential to empower creators, connect individuals with global communities, and distribute knowledge and shared resources. Through our collective efforts, we hope to shape a future in which technology acts as a communal connective tissue. The tools to make this world a reality are finally here, and we’re excited to use them to create more fluidity, transparency, and resiliency in how we think and work together.
https://www.k20educators.com Vision :k20 was created to connect educators from around the world in order to realize our collective brilliance. When educators collaborate, we’re able to transcend local obstacles to produce global solutions. And if educators are expected to change the world, we should have access to the world’s best professional learning to optimize our impact.k20 aims to be the largest networking, learning, and career hub for educators, with the most comprehensive directory of professional learning. We are enabling knowledge sharing to dismantle global silos in education.
https://www.merlot.org/merlot/ The MERLOT system provides access to curated online learning and support materials and content creation tools, led by an international community of educators, learners and researchers.
On Friday I attended the GCDI Digital Fellow’s workshop Text Analysis with Natural Language Toolkit (NLTK), the function of which the program instructor described as “turning qualitative texts into quantitative objects.” As a complete neophyte to both the Python programming language that NLTK runs on as well as to text analysis, I was eager to assess how easily a newcomer like myself could learn to use such a suite of tools, as well as to continue thinking about how the fruits of such textual quantification might contribute to the meaningful study of texts.
The workshop, which required download of the Anaconda Navigator interface to launch Jupyter notebook, was very useful in introducing and putting into practice core concepts for cleaning and analyzing textual data as expressed in different commands. The “cleaning” concepts included text normalization (the process of taking a list of words and transforming it into a more uniform sequence), the elimination of stopwords (terms like articles that appear frequently in a language, often adding grammatical structure but contributing little semantic content), and stemming and lemmatization (processes that try to consolidate words based on their root and grouping inflected forms of a principal word respectively).
The introductory file library that we analyzed in the workshop included nine texts, among them Herman Mellvile’s Moby Dick, Jane Austen’s Sense and Sensibility, and the King James Version/Authorized Version text of the biblical Book of Genesis. As one would expect, the command text.concordance“(word)”collates all instances of a term’s occurrence within one text. The command text.similar“(word)”seems especially useful: this command ranks words that occur in the same context as the primary term being investigated. Such quantitative ranking of contextually-related terms seems to get closer to the heart of the humanities’ first and last endeavor: the qualitative interpretation of meaning.
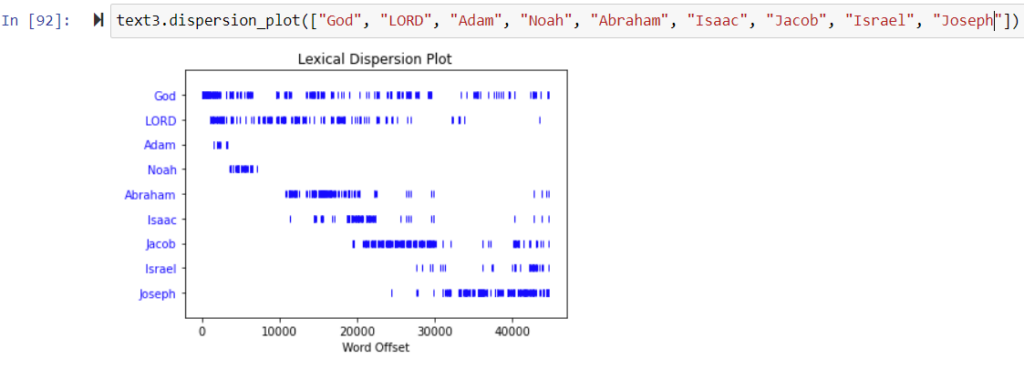
When we were reviewing the different visualizations NLTK could generate, I suggested the following command for Genesis (modified, since the workshop, to include the word ‘LORD’, since the KJV translation of Genesis typically uses ‘LORD’ to render the tetragrammaton ‘YHWH,’ whereas ‘God,’ is employed to render ‘Elohim’; I also added ‘Adam’, ‘Noah’, and Jacob’s alias, ‘Israel’, for good measure) :
As one would expect, the resulting visualization conveys a sense of the narrative arc of Genesis based on the lives of the patriarchs as identified by their proper nouns. In demonstrating the narrative relationship between different personages, a visualization of this sort could possibly be useful in the same way as To see or Not to See, the Shakespeare visualization tool demonstrated by Maria Baker several weeks ago.
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: