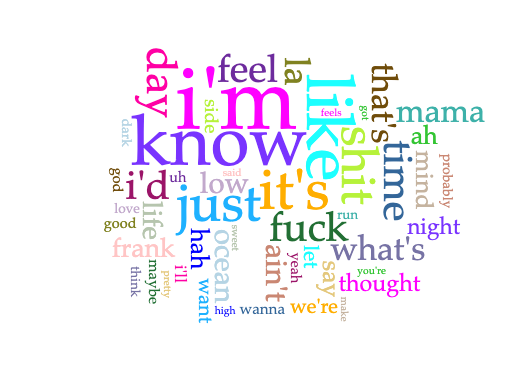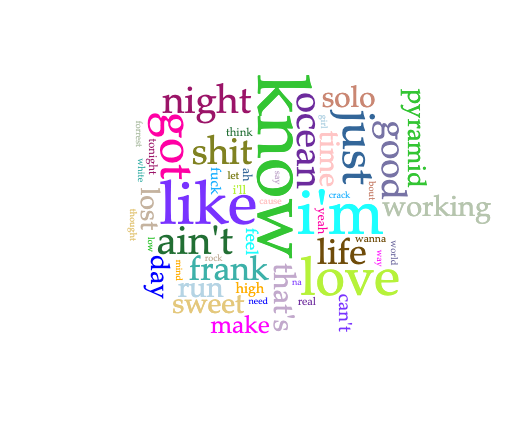I had real trouble with finding the right text to annotate and instead chose a different text to annotate and understand how this digital annotations work. I came to this with little understanding of digital humanities as a field, because I am trained in computer science field humanities part sound like a different language to me. I do come from a generation of forum nerds and I do see the usefulness of digital annotations akin to what forums did in mid 2010s before the mass advent of social media. Forums kind of died out under the weight of minute to minute updates and fast shifting social meta. I chose the text The making of the atomic bomb to annotate as it is of great interest to me and it is easy to find on CUNY manifold. All you have to do is to type it up in the search button but I could not find the text required by assignment for the life of me and spent close to an hour trying to find it. I guess that speaks of manifolds limitations in regards to efficiency of its search engine.
My annotation was:
“Pollonium- its interesting how each country gets to name each discovered element with its namesake. US got the name almost bottom half of the periodic table.”
It is a tongue in check annotation in regards to naming convention of periodic elements and how each country races to name the most. US named the most radioactive bunch on the bottom of periodic table since it was the leader in atomic research thus discovering unstable elements needed to produce an atomic bomb. Nuclear weapons are hot topic again since the end of cold war, and it is important to know their history and with history comes the context of what we are talking about. I guess that is one of missions of digital humanities to spread the gospel of humanities through digital means and to stir up conversations in the general populace, and if we do not that we are at the precipice to be relegated to the dreadful academic elite which became an insult in this day and age.
With pedagogical considerations in mind, this week’s readings highlight opportunities and strategies for undergraduate students to critically engage texts in meaningful ways using digital platforms, with special attention to student-led annotation. Strategies for fostering student engagement with learning content are discussed in both “Postcolonial Digital Pedagogy” by Roopika Risam as well as “Social Annotation and an Inclusive Praxis for Open Pedagogy in the College Classroom” by Monica Brown and Benjamin Croft. Both texts emphasize digital tools (from text analysis to textual annotation) as means to foster students’ interrogation of the political and cultural structures at work in different texts, to encourage student recognition of their own roles as producers and contributors of knowledge, and to raise consciousness of the power dynamics presumed to be at play (whether implicitly or explicitly) among students in their communal engagement with texts. There is a certain complementarity to reading these articles together, based on where the ‘diverse emphasis’ (for want of a less clumsy expression) falls in each article. Risam’s chapter hones in on diverse learning content–in this case, postcolonial literature produced in the global south in the latter half of the twentieth century–and ways to leverage digital strategies to make that content critically comprehensible to students predominantly steeped in a northern-hemispheric, usually Anglocentric, cultural and literary milieu. Brown and Croft, on the other hand, emphasize a social justice-oriented praxis centered on diverse students, or “the practice of centering the contributions of historically marginalized populations” in student annotation of publicly visible text files (p. 4). The authors pay special attention to the role of the instructor as a sometimes-necessary ‘disruptor’ of ‘power asymmetries’ in instances where such students might feel culturally isolated marking up a text—the example given being “materials that overrepresent whiteness,” which the authors contend “can create an environment” where “students of color may experience harm, lack of safety, erasure, or tokenization” (p. 5). I would have liked the authors to have provided examples to demonstrate such instances where this becomes necessary.
One of the more salient points made by Cordell in “How Not to Teach the Digital Humanities” is the persistent myth of the digital native–the assumption that new students, whose whole lives experiences are immersed in the digital, are necessarily more adept or competent users than their “digital immigrant” instructors (when in fact, as touched on by Brown and Croft, many students are denied opportunities to develop digital skills by socioeconomic disparities). When I went to Pratt Institute to study library science in 2012, the digital native / digital immigrant dichotomy was still being taught in the core curriculum, its assumptions generally taken as fact. My earliest experiences working in urban public libraries from 2015 onward proved just how fallacious this notion was: it was not uncommon for library patrons in the 20s-to-30s age range to ask help with basic functions that we tend to take for granted as common knowledge (logging into one’s email on a desktop rather than a smartphone, resetting one’s password, downloading files and uploading attachments, toggling basic printer settings, etc.).
“A view from the window, a meeting with friends, a thought, an instance of leisure or exasperation – they are all candidates, contestants even, for a dimensional upgrade.”
The author implies that there’s no choice – that we are already living in a fourth digital dimension. I want the students to question that. I want them to know that they can decide what it means to be a four-dimensional human. There’s a sense of inevitability in the quote that all aspects of our lives will be uploaded at some point. But that doesn’t have to be a bad thing. The challenge is how you do it in a way that’s good for you.
So the question I ask with the annotation is –
What does it mean to digitize a thought? Or is it even possible to digitize what’s going on in our heads?
Second annotation:
“That being an individual entails a sort of exile from others may be a story that we tell ourselves, but it is no less solid for that. Of course the irony here is that we also can’t seem to get enough of the pack. We gather our lonesome selves together in groups by day, clinging together in warm, mealy huddles by night. Yet no matter how tight the clinch, we’re still flung to different corners of the dream- scape.”
My note is – Do you have to isolate yourself from others to be an ‘individual’, or how can you be your true self in a ‘pack?’
There’s a mildly depressing vibe throughout the piece. It’s like we are all destined to be lonely in this fourth dimension. I want the students to create their own healthy digital fourth dimension where they don’t ultimately feel isolated.
This article would be a good addition to help through the concepts or ideas.
As a data scientist, I have done many NLP projects at work. I mostly work in a Jupyter Notebook python environment and leveraged common NLP libraries like NLKT and Spacy. My usual NLP project mostly consisted of cleaning and structuring data (lemmatization, stop words, n-grams, tokenization, etc.) and running clustering models on them (usually LDA – Latent Dirichlet Allocation).
I have not heard of these tools and am excited to try them out as this is very different than my regular workflow. I have explored a few tools but will share my experience with two in particular below.
Voyant
Back in 2019, I started a personal NLP (Natural Language Processing) project but never finished it. As a quick recap, I was just looking to explore a lyrics data set. I picked Lana del Rey because I had been listening to her frequently back then. I tested gathering lyrics by web scraping and API (with AZ Lyrics and MusicMatch respectively). I was able to query lyrics from MusicMatch’s API after many trials but only to find out the “Free API” version only offers 30% (or the first 30 lines?) of lyrics per song. For this praxis, I was hoping to use this old dataset that I have gathered to explore tools mentioned in the guidelines. Unfortunately, I didn’t save the text anywhere and the code I wrote is outdated so it will require plenty of effort to refactor the code.
In the end, I have decided to use Taylor Swift’s latest album, Midnight (3 am version), instead. I have been listening to this album recently and so am familiar with the lyrics. I ended up just copying and pasting the lyrics from a site manually as it is the most straightforward.
I pasted the lyrics into the web interface and explored the web took quite a bit. I don’t find the output particularly helpful. I believe it is due to both lack of processing (e.g., data cleaning) as well as the nature of this text corpora. Here’s a screenshot of what I am seeing. I was unable to draw any insights. However, I was impressed by how easy it was to just paste in text, and all these features are automatically generated.
Google Books Ngram Viewer
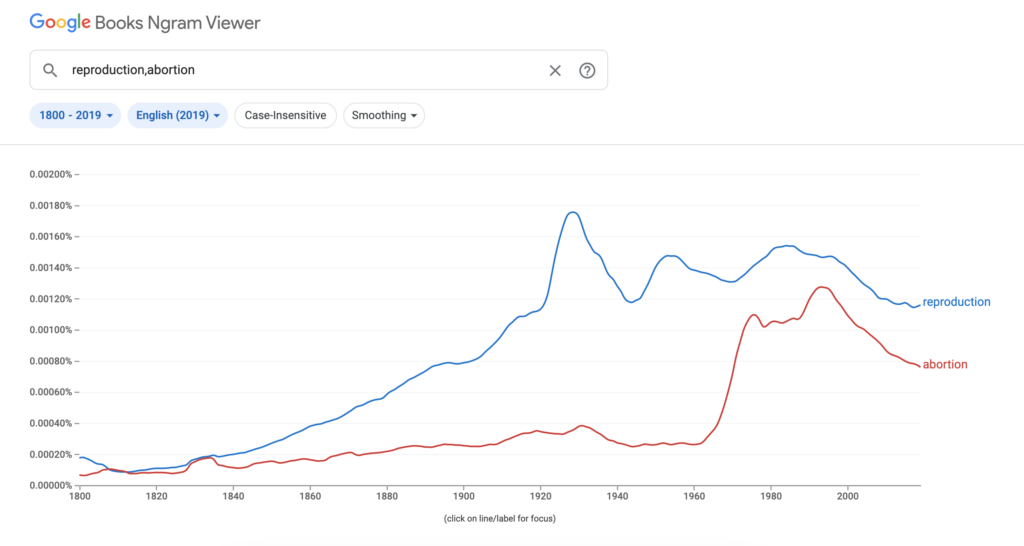
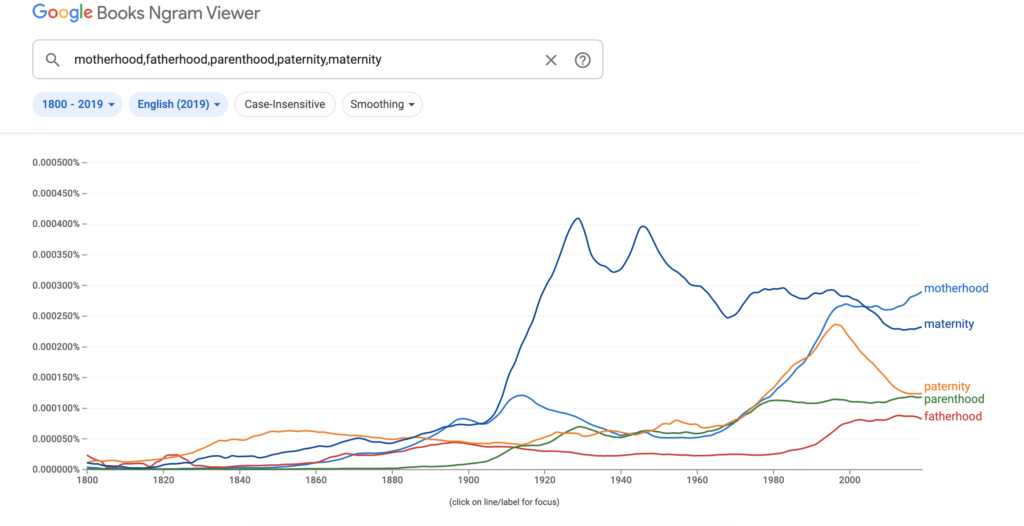
I have never heard of this tool before. From the name “n-gram”, I had the wrong assumption about what this tool does. It appears to be like a google trend product but related to google books content, which I thought is helpful. I have always been interested in gender disparity in many aspects of life, so I explored different keywords. Sharing two comparisons below:
For my first foray into Voyant, I decided to take a look at a guilty pleasure of mine: the scathing book review. I know I’m not the only one who likes reading a sharp, uncompromising take on a book. Reviews along the lines of Lauren Oyler’s excoriation of Jia Tolentino’s debut essay collection go viral semi-regularly; indeed, when Oyler herself wrote a novel, some critics were ready to add to the genre. (“It’s a book I’d expect her to flambé, had she not written it.”)
I was curious if these reviews differed from less passionate (and less negative) reviews in any way that would show up in text mining.
Initial Process
To investigate, I assembled two corpora: a small set of scathing reviews, and a small set of mildly positive ones. The parameters:
Each corpus included 5 reviews.
I drew the reviews from Literary Hub’s Bookmarks site, which aggregates book reviews from notable publications. Bookmarks categorizes reviews as “pan,” “mixed,” “positive,” and “rave.” I drew the “scathing” corpus from reviews tagged as pans, and the control set from positive reviews.
I used the same 5 reviewers for both sets. (This was tricky, since some of the reviewers I initially chose tended to only review books that they either truly hated or — more rarely — unequivocally loved. Call this “the hater factor.”)
I only selected books I haven’t read yet — unintentional at first, but I decided to keep with it once I noticed the pattern.
I tried to select only reviews of books that fell under the umbrella of “literary fiction,” (though what that means, if anything, is a debate in itself) though American Dirt is arguably not a great fit there (but was reviewed so scathingly in so many places, I couldn’t bear to leave it out — maybe call this “the hater’s compromise”).
I specifically stayed away from memoir/essays/nonfiction, since those are so often critiqued on political, moral, or fact-based grounds, which I didn’t want to mix with literary reviews (but if this post has made you hungry for some takedowns along these lines, the Bookmarks Most Scathing Book Reviews of 2020 list contains memoirs by Michael Cohen, John Bolton, and Woody Allen — you’re welcome).
Voyant was pretty easy to get started with — but I quickly realized how much more I’ll need to know in order to really get something out of it.
I created my corpora by pasting the review URLs into two Voyant tabs. My first observation: an out-of-the-box word cloud or word frequency list, perhaps especially for a small corpus of short texts like mine, is going to contain a lot of words that tell you nothing about the content or sentiment.
I read Voyant’s guide to stopwords, then attempted to eliminate the most obvious unhelpful words, including:
Author names (Yanagihara, Franzen) and parts of book or review titles (Paradise, Detransition) – these would have been way less significant if I’d started with a large corpus
Words scraped from the host websites, rather than review text (email, share, review, account)
Words with no sentiment attached to them (it’s, book, read)
If I were doing this as part of a bigger project, I’d look for lists of stopwords, or do more investigation into tools (within or beyond Voyant) related to sentiment analysis, which would fit better with what I was hoping to learn.
Even with my stopword lists, I didn’t see much difference between the two corpora. However, when I compared the two corpora by adding the Comparison column to my Terms grid on one of them, I did start to see some small but interesting differences — more on that below.
What I learned
Frankly, not much about these reviews — I’ll get to that in a second — but a little more about Voyant and the amount of effort it takes to learn something significant from text mining.
Some things I would do differently again next time:
Add much more data to each corpus. I knew five article-length items wasn’t much text, but I hadn’t fully realized how little I’d be able to get from corpora this small.
Set aside more time to research Voyant’s options or tools, both before and after uploading my corpora.
Create stopword lists and save them separately. Who would have guessed that my stopwords would vanish on later visits to my corpus? Not me, until now.
Use what I’ve learned to refine my goals/questions, and pose questions within each corpus (rather than just comparing them). Even with this brief foray into Voyant, I was able to come up with more specific questions, like: Are scathing reviews more alike or unlike each other than other types of reviews? (i.e., could Tolstoy’s aphorism about happy and unhappy families be applied to positive and negative reviews?) I think having a better understanding the scathing corpus on its own would help me come up with more thoughtful ways to compare it against other reviews.
Very minor takeaways about scathing book reviews
As I mentioned, I did gain some insight into the book reviews I chose to analyze. However, I want to point out that none of what I noticed is particularly novel. It was helpful to have read Maria Sachiko Cecire’s essay in the Data Sitters Club project, “The Truth About Digital Humanities Collaborations (and Textual Variants).” When Cecire’s colleagues are excited to “discover” an aspect of kid lit publishing that all scholars (and most observers) of the field already know, she points out that their discovery isn’t a discovery at all, and notes:
“To me, presenting these differences as a major finding seemed like we’d be recreating exactly the kind of blind spot that people have criticized digital humanities projects for: claiming something that’s already known in the field as exciting new knowledge just because it’s been found digitally.”
So here’s my caveat: nothing that I found was revelatory. Even as a non-expert in popular literary criticism, the insights I gained seemed like something I could have gotten from a close read just as easily as from a distant one.
The main thing I really found interesting — and potentially a thread to tug on — came from comparing word frequency in the two corpora. There weren’t any huge differences, but a few caught my eye.
The word “bad” appeared with a comparative frequency of +0.0060 in the “scathing” corpus, compared to the “positive” corpus. When I used the contexts tool to see how they occurred, I saw that all but one of the “scathing” uses of bad came from Christian Lorentzen and Lauren Oyler’s reviews. Neither reviewer used the word to refer to the quality of the text they’re reviewing (e.g., “bad writing”). Instead, “bad” was used as a way to paraphrase the authors’ moral framing of their characters’ actions. For Lorentzen, Salley Rooney’s Beautiful World, Where Are You includes “…a relentless keeping score… not only of who is a ‘normal’ person, but of who is a ‘good’ or ‘bad’ or ‘nice’ or ‘evil’ person.” Oyler uses the word to discuss Kristen Roupenian’s focus on stories that feature “bad sex” and “bad” endings. That literary reviewers pan something for being didactic, or moralistic, or too obvious is nothing surprising, but it’s interesting to see it lightly quantified. I’d be interested to see if this trend would carry out with a larger corpus, as well as how it would change over time with literary trends toward or against “morals” in literature.
I found something similar, but weaker, with “power” — both Oyler and Ryan Ruby (panning a Jonathan Franzen novel) characterize their authors’ attempts to capture power dynamics as a bit of shallow didacticism, but the word doesn’t show up at all in the positive corpus.
Words like “personality” and “motivation” only show up in the negative critiques. It’s also unsurprising that a pan might focus more on how well or poorly an author deals with the mechanics of storytelling and character than a positive review, where it’s a given that the author knows how to handle those things.
Even “character” shows up more often in the scathing corpus, which surprised me a bit, since it’s a presumably neutral and useful way to discuss the principals in a novel. To add further (weak!) evidence to the idea that mechanics are less important in a positive review, even when “character” does turn up in an otherwise positive review, it was more likely to be mentioned in a critical context. For example, in Oyler’s overall positive review of Torrey Peters’ Detransition, Baby, she notes that “the situation Peters has constructed depends on the characters having a lot of tedious conversations, carefully explaining their perspectives to one another.” As with everything else, I would want to see if this still held in a larger corpus before making much of it. It’s very possible that the reviewers I chose are most concerned with what they find dull. From my other reading of her work, that certainly seems true of Oyler.
To test these observations further, I’d need to build a bigger corpus, and maybe even a more diverse set of copora. For example, if I were to scrape scathing reviews from Goodreads — which is much more democratic than, say, the London Review of Books — what would I find? My initial suspicion is that Goodreads reviewers have somewhat different concerns than professional reviewers. A glance at the one-star reviews of Beautiful World, Where Are You seems to bear this out, though it’s interesting to note that discussion of character and other mechanics shows up here, too:
This would be a fun project to explore further, and I could see doing it with professional vs. popular reviews on other subjects, like restaurant reviews. Fellow review lovers (or maybe “review-loving haters”?), let me know if you’re interested in poking into this a bit more.
For this praxis assignment, I struggled at first with deciding what texts I wanted to explore. I wanted to explore which corpora were publicly available, in hopes of using an existing corpus instead of building my own. However, I ended up making my own corpora in realizing that I couldn’t force myself to be interested in the existing free-to-the-public corpora I had seen. Though I’m sure there must be something out there that speaks to my interests, I had a tough time effectively searching for resources on my own as a novice to text mining. Despite the fact that building my own corpus would require more work, it was a fun exercise that made the experience more rewarding.
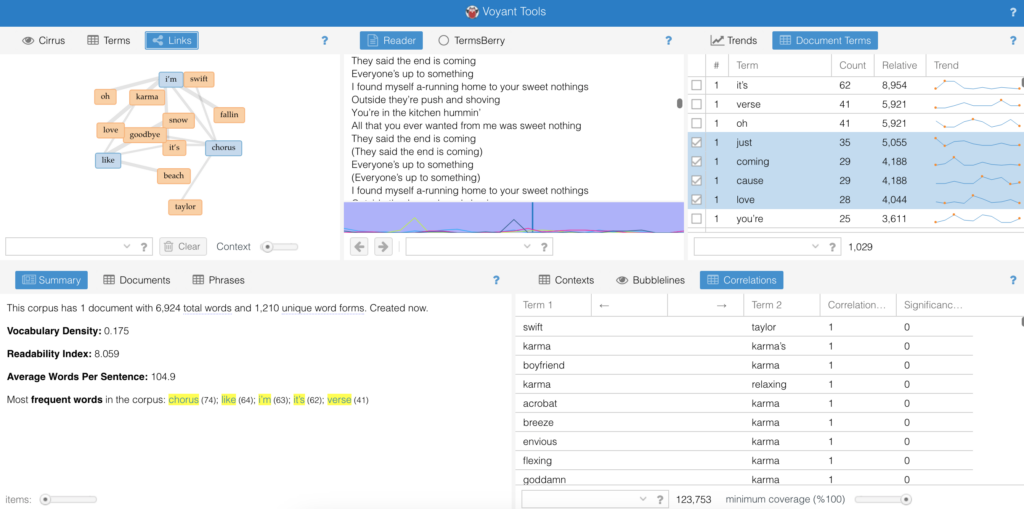
I use Voyant in hopes of gaining some insights regarding themes within Frank Ocean’s Blond/e and Channel Orange albums. These albums are personally some of my favorites of all time. I was interested in seeing what insights Voyant could provide for the “bigger picture” between (and among) the lyrics on each album, especially in comparison to my subjective experience of listening to these albums.
My first instinct was to try and figure out how I would be retrieving the lyrics for Frank Ocean’s songs. I figured I could use an API to pull song lyric information. I was planning to use Genius, but their API focuses more on the annotations, and not necessarily the lyrics themselves. So, I manually copied and pasted the lyrics to all his songs on both albums into .txt files within separate folders representing the albums instead. Initially, I was planning to just pass each album in separately to Voyant. I wanted to explore how Frank Ocean’s lyrics changed from Channel Orange (2012) to Blond/e (2016), especially with regards to his queerness (which I’ve personally felt has been greater explored in his later music in Blond/e, but is definitely subtly present within Channel Orange). But after reflecting more on the insights I was hoping to gain, I decided to pass all the songs from both albums combined, in order to see what themes may have overlapped in the context of one another. Additionally, I passed two separate parts of the Blond/e album split in half. The album Blond/e is actually split into two separate parts – the album is exactly one hour, with the transition in “Nights” occurring at the 30 minute mark, directly splitting it in half.. Hence, there are two spellings of the album; the album cover art says “blond” while the album title is listed as Blonde. Duality is a major theme explored in Blond/e, with regards to the album branding, the song lyrics, and the musical composition. I think the duality themes present could be interpreted in reference to Frank Ocean’s bisexuality!
After passing 5 different corpora into Voyant, the resulting cirrus and link visualizations follow.
Channel Orange
cirrusoverall word linkslink to word “love”
Some notes:
With regards to love, it seems as though Frank Ocean is looking to make something real happen
In the cirrus, I come to understand Channel Orange to be about thinking and looking for real love, and being lost in the process.
Blond/e
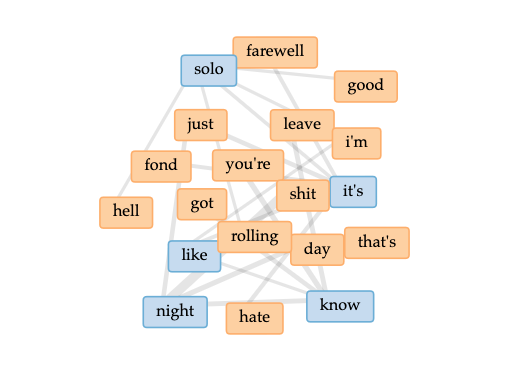
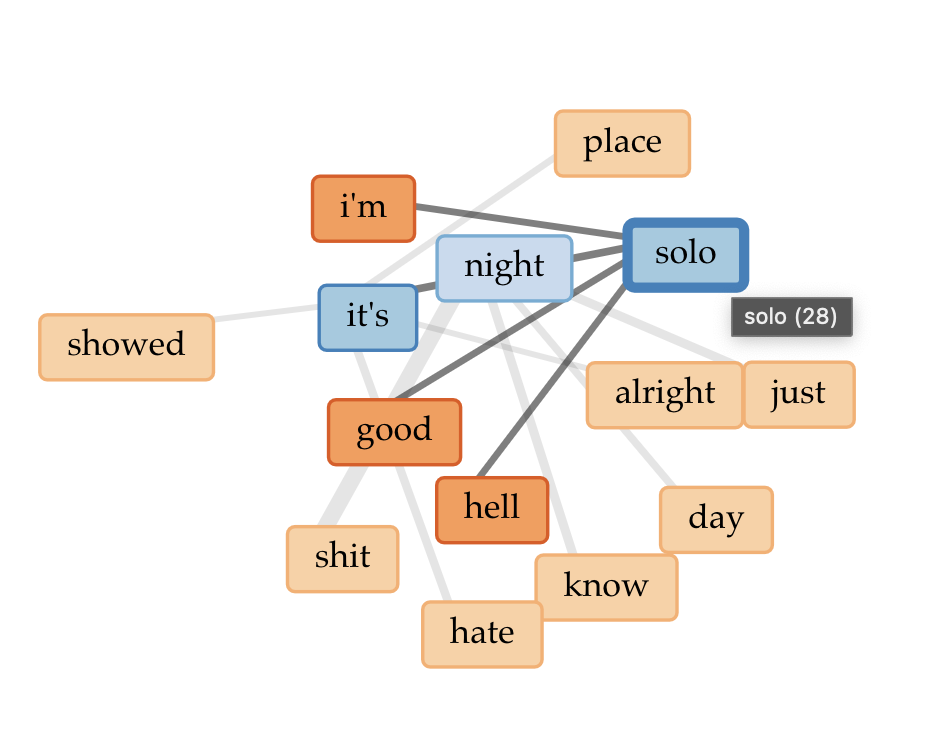
overall word linkslinks to words “solo” and “night”cirrus
Some notes:
Blond/e appears to be on his own, and learning to navigate that
In the cirrus, I come to understand Channel Orange to be about thinking and looking for real love, and being lost in the process.
As a whole, Blond/e could be interpreted as a farewell to a past fond lover, and trying to make it through the days (and nights)
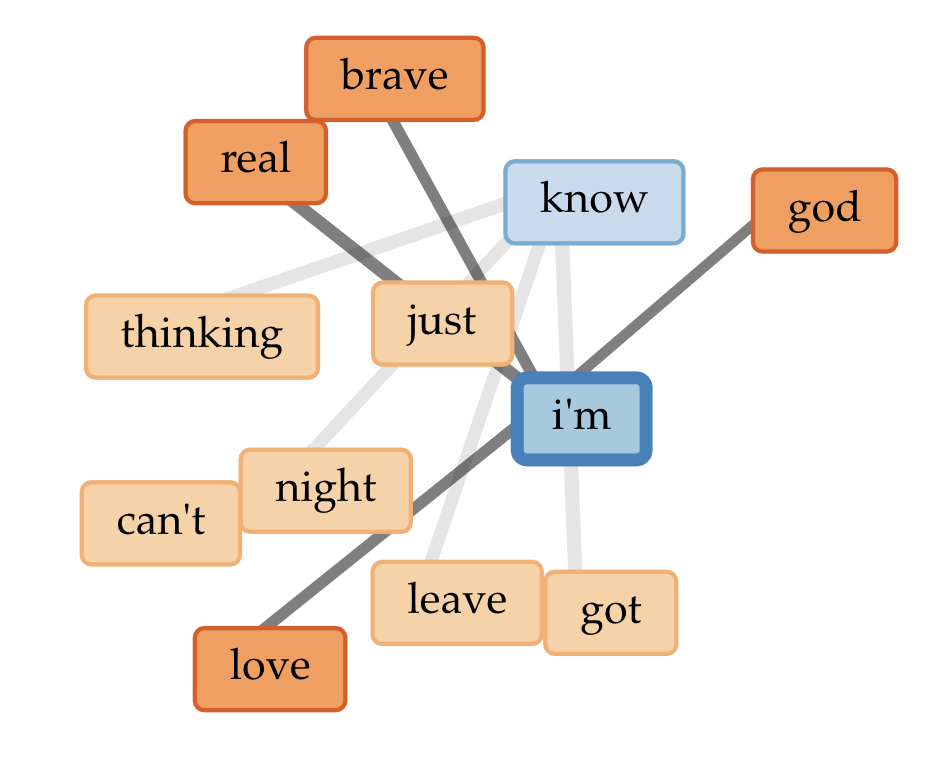
Blond/e Part I
cirrusoverall word links
A note:
In the first part of Blond/e, there tends to be more words regarding struggle, such as solo, night, hell, leave, etc., as well as reference to marijuana to likely cope with heartbreak.
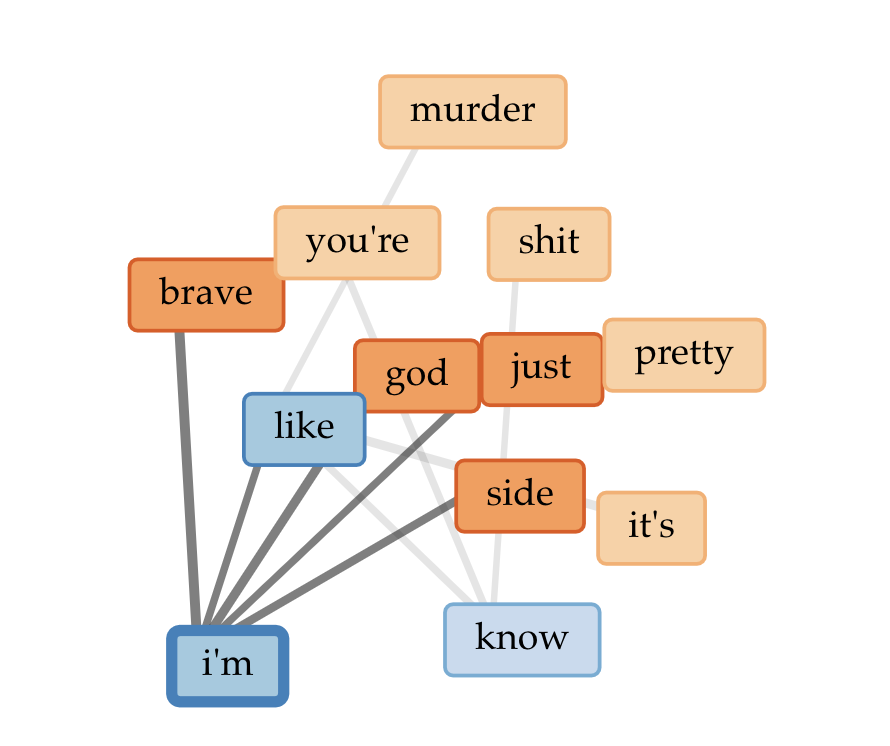
Blond/e Part II
cirrusoverall word links
Some notes:
In the second part of Blond/e, there is more references to day (which ties back in to my original statement about the two album parts representing duality)
In the overall word links, there are also links to Frank being “brave” and thinking about “god” – knowing the album myself, I interpret references to god to deal with learning to let go (hence his song “Godspeed”)
Channel Orange + Blond/e
cirrusword links
Some notes:
Overall when combining the two albums, there seems to be prevalent references to love, god, and night/day.
Overall, playing around with Voyant was a fun experience. I hope to explore more, especially with regards to music analysis. I’m wondering if there’s similar analysis tools that can incorporate mining both text AND audio on bigger scales (though I know with audio files, it’s more difficult due to data constraints potentially). I wish I had more time to analyze the visualizations, and to dig deeper into formulating some insights that align (or contradict!) with my own personal close listening.
Comparing Close and Distant reading outcomes of Virginia Woolf’s Mrs. Dalloway.
For the text analysis praxis, I chose to test out an observation made while close reading Virginia Woolf’s Mrs. Dalloway. For another DH class, I’ve been working on a group project investigating annotation methods using the Mrs. Dalloway as the basis. Despite Woolf suggesting that she simply let the novel flow through her with no great structure in mind, when reading it’s hard to not feel the seemingly concrete structure on top of which flows the seemingly meandering stream of consciousness dance. Of course that stream of consciousness surfaces themes again and again via the minds of various characters until it becomes plain that Woolf wants us to explore certain aspects of our humanity—youth and age, spontaneity and duty among them.
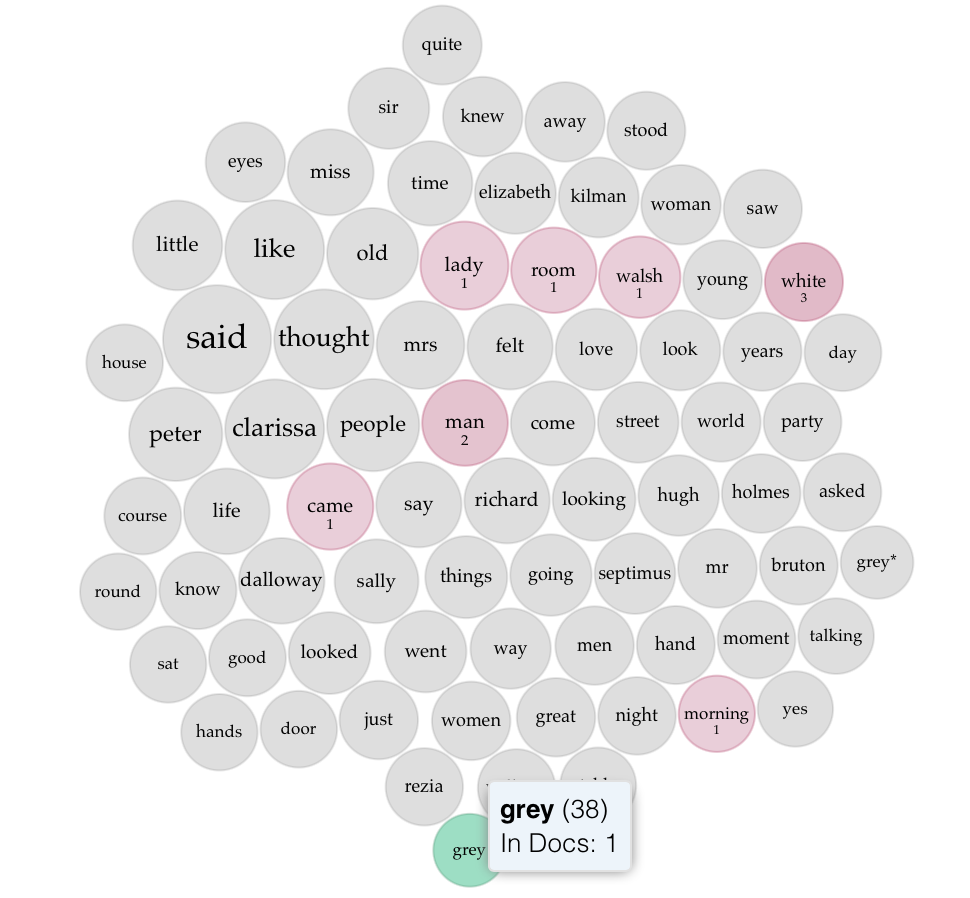
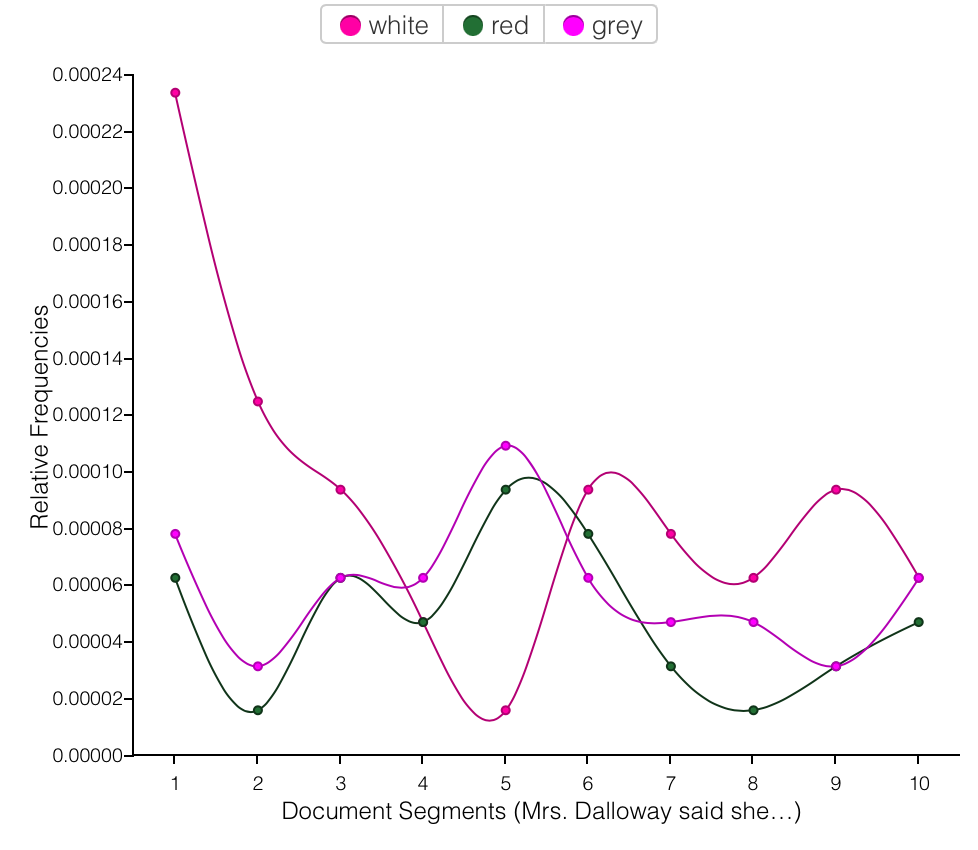
When close reading I felt and remarked that the color grey turned out repeatedly. At first I suspected that the London setting and widely accepted stereotypical assumptions of English weather made me more attuned it (ahh yes, confirmation of that stereotype, I’m picturing the right thing) —maybe even made me overestimate its prevelance. But then I began to notice it being applied to all manner of things—but most often in a manner to denote stature, wisdom, age, and respectability. I also began to nice the mention of roses—a kind of sprinkling evenly throughout the text in relationship to various characters. These flowers were derided, gifted, and displayed—even used by Septimus, a character with a tenuous connection to this Earth, to ground himself in the moment and counteract his tendency lose himself to incoherent thought. I decided that Voyant would be a great way to see what the algorithm’s had to say about my observations. Would the reinforced or minimized—would it help suss out a pattern I didn’t observe?
Looking at the frequency of grey (38 mentions), which appears more than any other color in the text after white (58 mentions), I did see a continued usage throughout the text, and the context revealed what I had suspected. It is often used to denote age (grey hair)—and suggest a more regular and fixed time of life. It is, also, used to signal a more refined air—standing in the world. In relation to the text, I’d even go so far as to say it showcased the kind of fixed and respectable striving of 1923 London. Weather does come in, for sure (grey-blue sky), but more often it describes the appearance of understated and refined clothing, vehicles, and homes of established ladies and gentlemen.
Indeed it was—Sir William Bradshaw’s motor car; low, powerful, grey with plain initials’ interlocked on the panel, as if the pomps of heraldry were incongruous, this man beingthe ghostly helper, the priest of science; and, as the motor car was grey, so to matchits sober suavity, grey furs, silver grey rugs were heaped in it, to keep her ladyshipwarm while she waited.
He had worked very hard; he had won his position by sheer ability (being the son of a shopkeeper); loved his profession; made a fine figurehead at ceremonies and spoke well—all of which had by the time he was knighted given him a heavy look, a weary look (the stream of patients being so incessant, the responsibilities and privileges of his profession so onerous), which weariness, together with his grey hairs, increased the extraordinary distinction of his presence and gave him the reputation (of the utmost importance in dealing with nerve cases) not merely of lightning skill, and almost infallible accuracy in diagnosis but of sympathy; tact; understanding of the human soul.
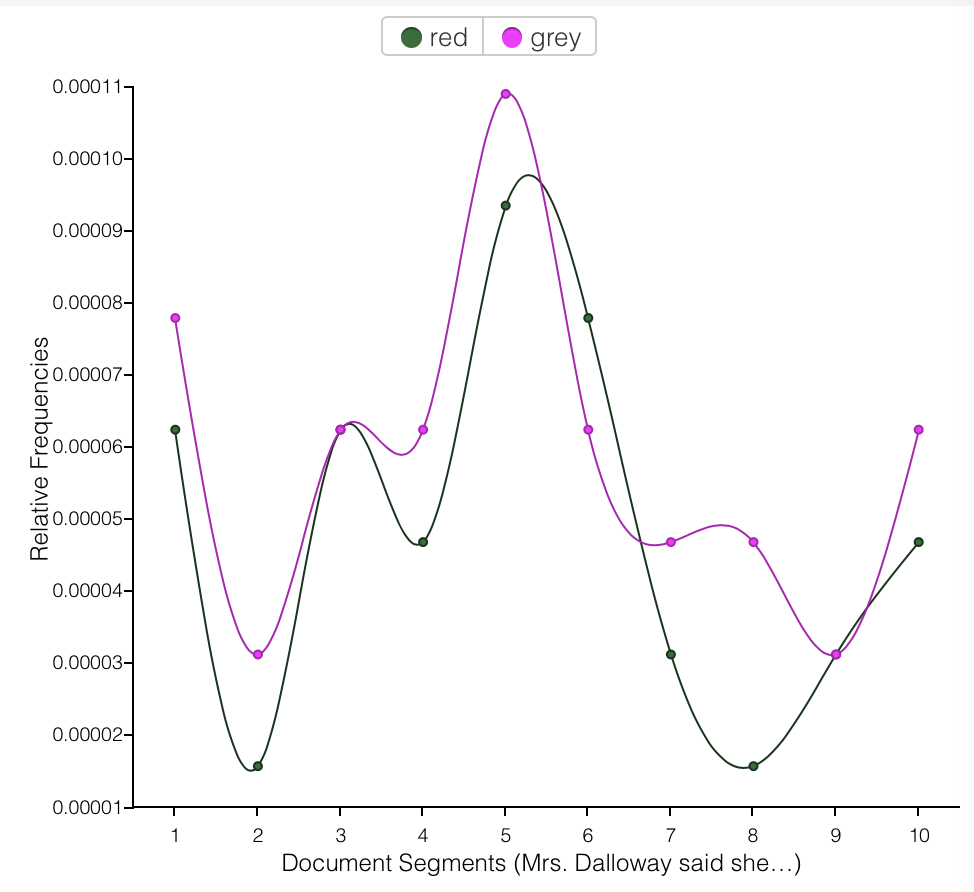
In considering roses, I wondered if it might not be more congruous, given my investigation of the color grey, to shift to investigating the color red. The roses mentioned throughout the book are red—that classic color of love, emotion, youth and intensity. When I made this adjustment something very striking was revealed. The frequency of the mention of red mirrored that of grey—almost as though they went hand in hand. Instead of black and white, Woolf seemed to have leaned into a contrast of grey and red—old vs young, passion vs resignation.
Red and Grey going hand in hand
The striking overlap is even more apparent when contrasted with the color most mentioned in the book— white. There is a clear correlation between grey and red.
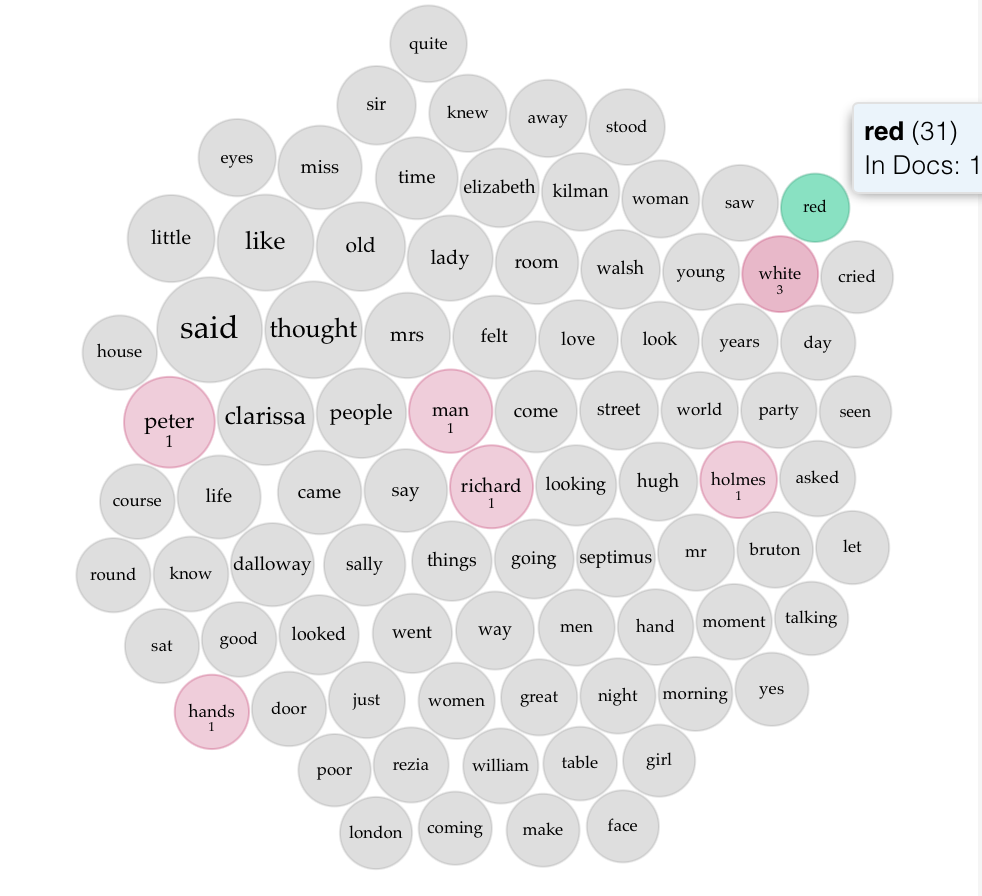
Red and Grey— best buddiesPeter and Richard chase and try to harness the power of red
Investigating red’s term berry doesn’t give too much away, but digging into the context gives everything away. It’s often mentioned in descriptions with almost riotous abundance of color (in stark contrast to drab and monotonous grey) and often paired with descriptions of flowers and bodily features (again with hair and clothing, but also nostrils, lips, and cheeks). Red is seemingly used to the character experience in the present moment of the novel in contrast to the experience of reminiscence that makes up much of the novel.
… and it was the moment between six and seven when every flower—roses, carnations, irises, lilac—glows; white, violet, red, deep orange; every flower seems toburn by itself, softly, purely in the misty beds; and how she loved the grey-white mothsspinning in and out, over the cherry pie, over the evening primroses!
But she’s not married; she’s young; quite young, thought Peter, the red carnation he had seen her wear as she came across Trafalgar Square burning again in his eyes and making her lips red.
…through all the commodities of the world, perishable and permanent, hams, drugs, flowers, stationery, variously smelling, now sweet, now sour she lurched; saw herself thus lurching with her hat askew, very red in the face, full length in a looking-glass; and at last came out into the street.
And that very handsome, very self-possessed young woman was Elizabeth,over there, by the curtains, in red.
Over all this investigation made me curious about mapping and investigating the many many overlapping patterns and structures in the novel. In fact, this exercise and that in my other class has pushed me into a peculiar space of looking at the novel as a specimen to be poked, prodded, and labeled, graphed and displayed. In this way I might possess and express my own experience of it. The idea of thinking one could “master” a novel in this way feels a bit like a delusion. It’s like trying to create a bot of Woolf’s thought process, but when you press go she doesn’t pass the Turing test. I know that there is value to this work—and as I become more comfortable and perhaps apply these tools to non-fiction work as well I can better manage the dissonance that flutters about this exercise.
BONUS:
If you haven’t read Mrs. Dalloway, setting the Voyant Terms Berry to the smallest word sample gives a pretty good summary:
If you visit shrines and temples in Asia, you may often see people praying for good wishes and taking Omikuji (fortunes written on paper strips) from boxes or even coin-slot machines. The Omikuji predicts your fortunes in health, work, study, marriage, etc. There are many kinds of words written on Omikuji to describe fortunes, and I am interested in the method of using classical Japanese poetry (waka) as divination.
Figure 1
I decided to run some fortune-telling poems with Voyant to see the results. The Omikuji strips are usually rolled up and folded; you will need to unroll them to see the result. Before you read the fortune-telling poems, you will see a general indicator to tell you if you are lucky today. Among many categorization methods, the examples I am using are divided as follows,
Figure 2
Dai-kichi大吉 (excellent luck)
Kichi吉 (good luck)
Chu-kichi中吉 (moderate luck)
Sho-kichi小吉 (a little bit of luck)
Sue-kichi末吉 (bad luck; good luck yet to come)
Failure?
I retrieved the data from the Omikuji-joshidosya website. It is said that 70% of current Omikuji strips in Japan are made by the Nishoyamada Shrine, where the Organization Joshidosha (Women’s Road Company) locates.
Figure 3
My first attempt was a total disappointment. See the Figure 4,
Figure 4
The high-frequency words that appeared in Cirrus, TermsBerry, and Trends are single hiragana characters instead of objects’ names and verbs. These words are similar to determiners and prepositions (stopwords in Voyant) in English (the, a, in, to, form, etc.). I then also realized that stopwords are not the only problem in analyzing Japanese text. Text segmentation is also different in Japanese: this issue is already super complicated in modern Japanese, not to mention that the poems in my mini-project are written in classical Japanese. So I tried to refer to the article “Basic Python for Japanese Studies: Using fugashi for Text Segmentation” and see if I could reframe the textual structure of my text for Voyant. For example, I could clean my text before uploading it to Voyant by removing auxiliary verbs, particles, suffixes, prefixes, etc. I also learned about a more manageable solution about Japanese version of stopwords from Japanese DH scholar Nagasaki Kiyonori in his post.
Inspired by Nagasaki Kiyonori, I started to create a stopword list by myself. (Figure 5) The default setting of the stopword list in Voyant Japanese mode is based on modern Japanese. See some examples here,
あそこ あの あのかた あの人 あります あれ います え おります から
何 彼 彼女 我々 私 私達 貴方 貴方方
Unlike modern Japanese or Japanese in the Meiji period (1868–1912), auxiliary verbs and particles are almost used in a completely different system in classical Japanese. See some examples in my stopword list here,
が て して で つつ つ ぬ たり り き けり む
Figure 5
But I am glad I chose poetry to do the Voyant experiment because the waka poetry has a relatively easier text segmentation method: one poem always breaks into phrases of 5/7/5/7/7.
Okay, now we have a feasible approach! The next question is about the purpose of this analysis. Should I do a full-text analysis, or should I do several studies with questions that could be asked about those poems? For example, what seasons and figurative language are chosen for good luck and bad luck respectively?
I decided to do a comparison of imagery/actions used in the excellent luck group and the bad luck group. See the number of poems in each group:
Keywords: autumn, quiet, see, moon, shadow, flower, scatter, reality, top of a tree
Figure 7
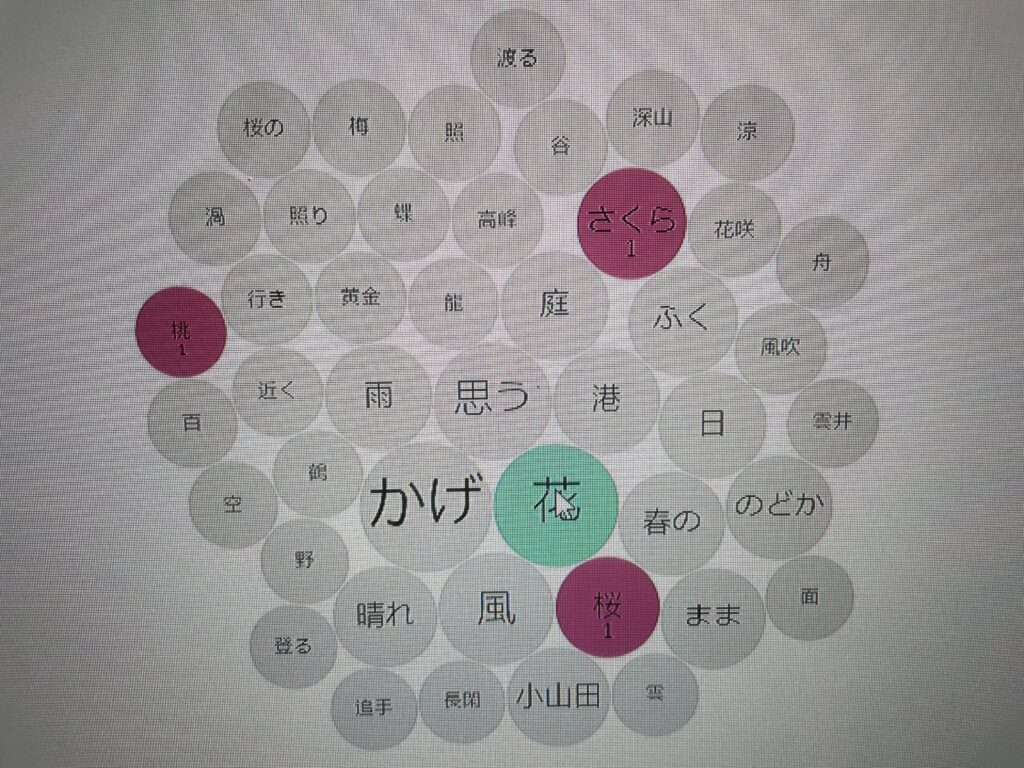
The keywords mentioned above have already shown us a sharp comparison between what the creators believe as good luck and bad luck. I am very satisfied with the result, even though I know there are a lot to be improved. I also went to try TermsBerry and Trends in Voyant and realized that I can do further studies using these features. For example although the keyword “flower” and “shadow” both appear in two groups, what associations they have that make them different in good and back luck groups? The example in Figure 8 shows a clear association between flower, sakura (both in hiragana and kanji characters), and peach flower,
Figure 8
Conclusion
The Getting Started with Text Mining is very helpful. I started my mini-project without big data but with the idea that I need to prepare my data (cleaning and removing). If I want to use Voyant to do deeper and larger scale analysis of poems and classical Japanese texts, it definitely requires a huge preparation work. For example, I believe if I do more stopwords considering conjugations, the result probably will be more accurate. I think this tool is great for learning intertextuality and imagery in poetry writing.
There are also Sinitic poetry (kanshi 漢詩) fortune-telling Omikuji! Oh, that would be in a totally different linguist structure, but worth a try next time.
Throughout this week’s readings, I noticed the separation between those who analyze and those who provide the “content” that is analyzed, i.e., the separation between the distant readers/researchers and the authors.
Shall these two never meet?
As a person who writes, I began to wonder whether distant reading my own novel draft might yield some productive insight.
While writing, I often find myself in forest-for-the-trees situations, meaning I am deeply in the mud of the moment of my creation (the frog’s perspective) and feel like I am losing my grasp on the story’s overall arc (the bird’s perspective).
To stay connected to the bird’s eye view, authors who work on longer creative projects (and I suppose longer academic projects, too) will often have either a pinboard with index cards or a writing program like Scrivener with features showing the spine of a story digitally.
However, both of these approaches (index card and/or writing software) are still tied to chronology. And one of the intriguing aspects of distant reading is its promise of simultaneity, of translating a time-based piece into a single image. (Or if not entirely ditching chronology, distant reading at least speeds things up.)
How much of a literary work’s overall concept trickles down/is visible in its more fundamental building blocks (words and sentences)? This is a point of curiosity, a question I had not considered before familiarizing myself with distant reading.
I decided to use Voyant and Word Tree to learn a bit more about my own text-in-progress and see how its micro and macro aspects inform each other.
I uploaded the first chapter of a novel to Voyant I am working on and tried to see whether anything interesting would emerge in the “reveal”. I did not have any specific questions, only many vague curiosities. My belief (based on various experiments conducted for Praxis Assignments throughout the semester) remains that having good initial questions is necessary to find a way for these tools to serve us well. Hopefully, the questions get refined in the process of working with the tools, but an initial curiosity is productive and propulsive.
Here is what I learned about my text:
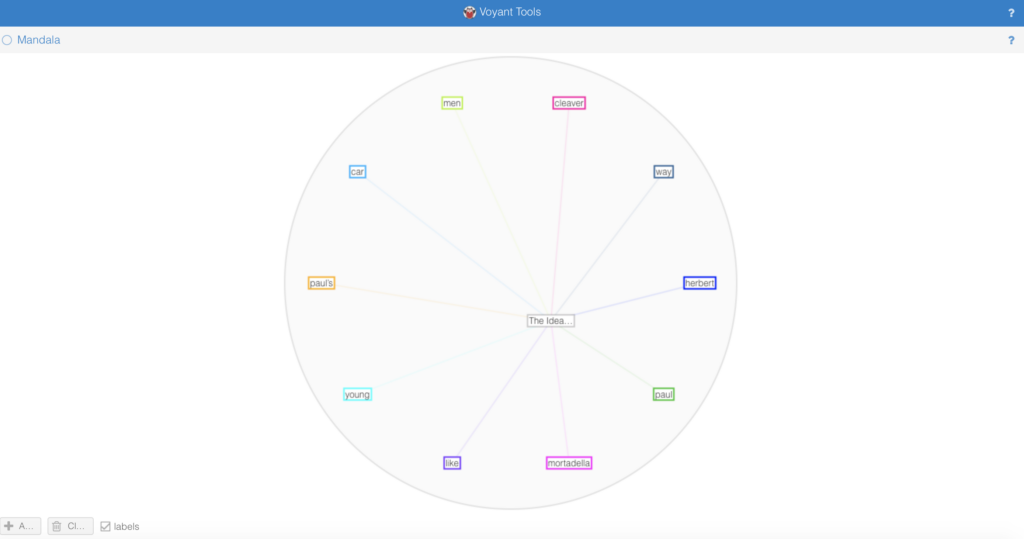
Most insightful was the Mandala feature in Voyant: It centered the chapter title “The Idea” and showed a list of salient/defining terms within the chapter. The resulting diagram gave me a snapshot of the chapter as a network. It was satisfying to see the story’s main ingredients, almost as if someone had reverse-engineered the text and created the beginnings of a recipe.
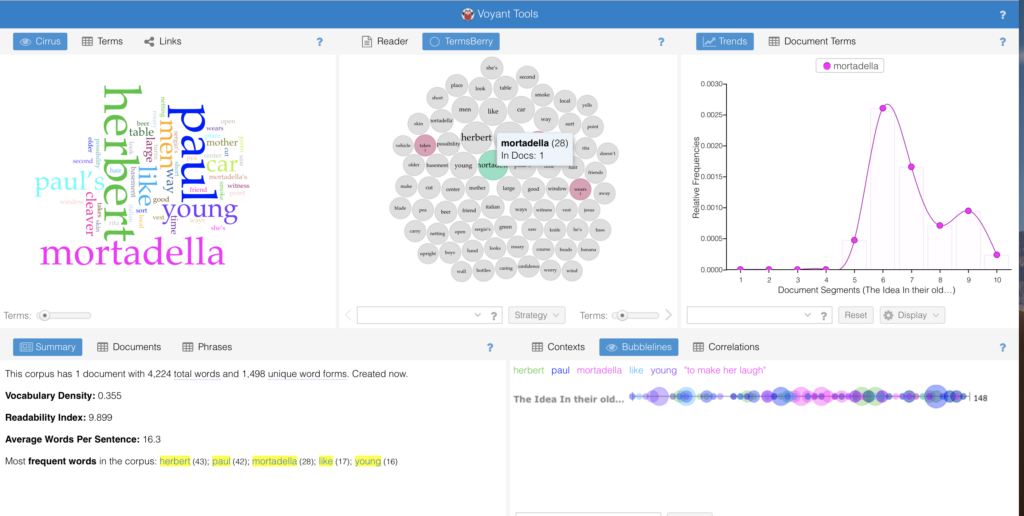
Via the Cirrus feature, I learned that I had certainly established my protagonists/main players in the first chapter. Via Trends I saw that the arcs of the main players intersected in ways that confirmed my intentions and intuitions.
So far, I had received mostly confirmations.
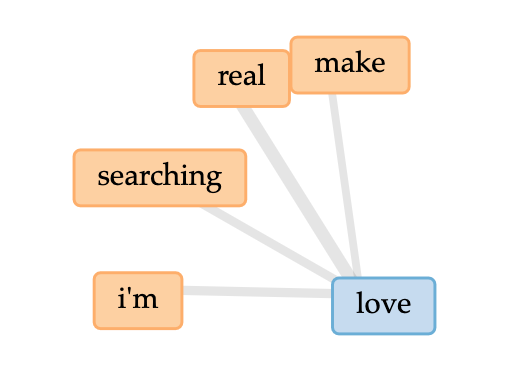
More interesting insight came from looking at the “second tier” of usages, the second largest words in the cloud. I noticed that the program treats the possessive of a noun as a distinct entity. I.e., “Paul” and “Paul’s” are different entities as far as Voyant is concerned. Considering both forms together influences (and in this case amplifies) the overall presence of Paul — which aligns with my intentions but was more difficult to see. The strong presence of “Paul’s” also says something about Paul that I hadn’t explicitly considered: He owns more than others. (More characteristics or more goods? Tbd.) I can see fruitful research questions emerging around the use of the possessive form in my text and the texts of others.
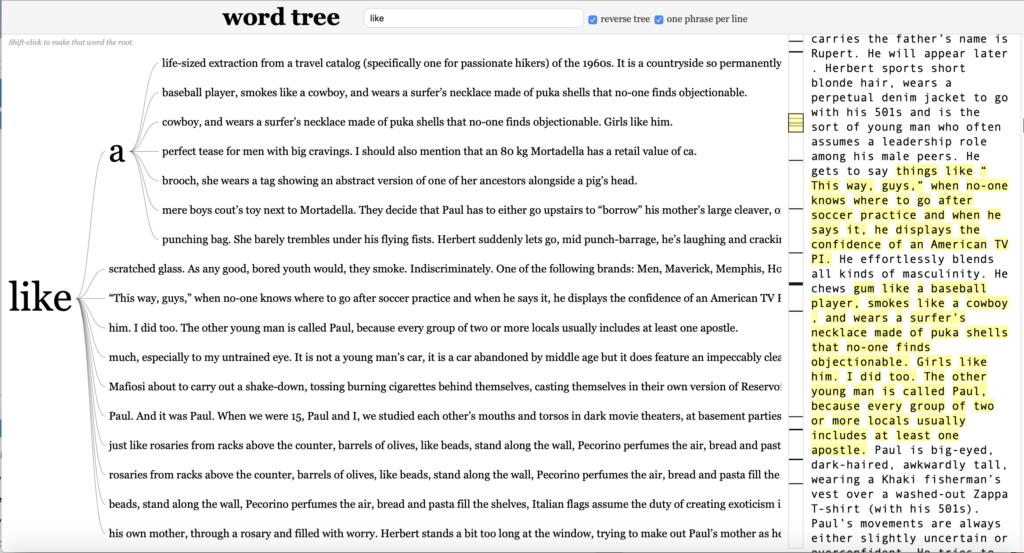
Another aspect that surprised me was the frequent presence of the word “like”. I would not have anticipated this. Here, Word Tree provided an opportunity to look at the context of these “likes” in more detail.
Based on the specific usages, which I could easily surveil via the word tree above, I might consider stylistic changes. Or perhaps I might notice that simile carries outsized responsibility in my text. The frequency of “like” might point to a theme I could make more explicit in revision. (I am thinking about this.)
In summary:
I can see Voyant being especially helpful in the later stages of the revision process for a novel & when evaluating and implementing editorial feedback. Even when using tools like Voyant on your own writing, the insights distant reading affords are most useful paired with close reading. The data visualization can be an impetus for returning to specific sections and close-reading those. (See also the Richard Jean So and Edwin Roland text “Race and Distant Reading” which details a constructive relationship between close and distant reading by looking more closely at Balwin’s Novel “Giovanni’s Room”)
And one sidebar Q:
I am wondering how Voyant’s Cirrus chooses colors. My text is very much about gender, and I noticed that nouns I had designated male kept coming up as blue and green, female coded nouns as pink. Hmmm. Coincidence? This observation made me want to try the software with a text in a very gendered language (like German).
For my text analysis assignment, I decided to use Voyant to look at one of the English language’s great historical works: The History of the Decline and Fall of the Roman Empire by Edward Gibbon,published in six volumes (further divided into 71 chapters) over thirteen years from 1776 to 1789. Gibbon’s magisterial study spans a period of over 1,300 years, examining the Roman-Mediterranean world from the height of the classical empire to the fall of Constantinople, capital of the eastern Roman empire (which western authors have anachronistically called the ‘Byzantine’ empire since early modernity), to the Ottoman armies of Mehmet II in 1453. Gibbon’s scholarly rigor, sense of historical continuity, and dispassionate, meticulous examination of original, extant sources contributed to the development of the historical method in western scholarship. Nevertheless, some of Gibbon’s conclusions in the Decline and Fall are also a product of the eighteenth century in which the author lived and wrote, and Gibbon’s writing is occasionally punctuated with moralizing statements (briefly touched on below).
The majority of text analysis experiments seem to focus on works of fiction, paying particular attention to their stylistic and aesthetic dimensions. I asked myself: what about an historical work, which is also a narrative construction? Would running Decline and Fall through Voyant allow a reader to observe trends in the stylistic or moralizing dimensions of Gibbon’s grand historical narrative, beyond what might already be grasped by an ordinary reading the text? (disclosure: I have by no means read all six volumes of Decline and Fall in their entirety).
I used a plaintext file of Decline and Fall from Project Gutenberg that features an 1836-45 revised American edition containing the text of all six volumes. Prior to uploading this file in Voyant, I removed the hundreds of instances of the word ‘return’ in parentheses (which in the HTML version of the file link to the paragraph location in the text), in addition to the preface and legal note at the end of the work authored by Project Gutenberg. After uploading the file, I added additional stopwords to Voyant’s auto-detected list. The terms I removed relate to chapter headings (e.g., Roman numerals), citations (‘tom’ for tome, ‘orat’ for oration, ‘epist’ for epistle, ‘hist’ for historia’, ‘edit’ for edition and so on), and occasional Latinate (‘ad’, ‘et’) and French (‘sur, ‘des’) words. To this end, the word cloud tool was helpful for identifying terms that should be added to the stop-word list.
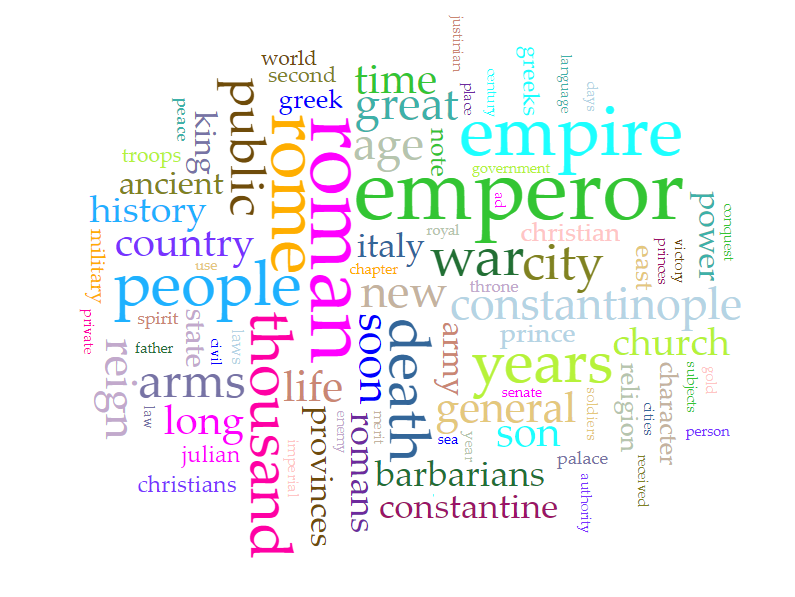
The resulting word cloud was, to say the least, neither surprising nor particularly revealing nor useful, most of the terms referring to the work’s predominant subjects:
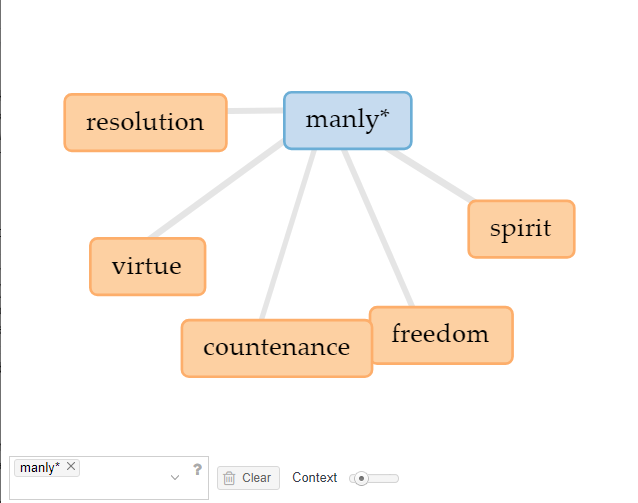
Standing out as one of the only abstract terms visible in the cloud limited to the top 75 words, however, was “character,” with 828 occurrences. Navigating to the ‘Contexts’ tab, I generated a concordance displaying instances of ‘character,’ which revealed a plethora of specific adjectives used in Gibbon’s text, for example, “manly.” Running ‘manly’ through the ‘links’ generator reveals a network of terms that reflect classical Roman definitions of masculine virtue (‘virtue,’ ‘spirit,’ ‘resolution,’ ‘freedom’) and one usage related to physical appearance (‘countenance’):
These results are once again neither surprising nor interesting, since the ancient (male) writers informing Gibbon’s work were themselves concerned with writing about the meritorious qualities and/or vices of individual male leaders for moralizing, didactic purposes, be they emperors, generals or bishops. This calls to mind Michael Witmore’s observation that “what makes a text a text–its susceptibility to varying levels of address–is a feature of book culture and the flexibility of the textual imagination” (2012). These particular examples may demonstrate the influence of classical authors on Gibbon’s narrative, but they do not necessarily convey anything about what is original in Gibbon’s prose (or, differently stated, original to Gibbon’s contemporary setting).
Perhaps one could get closer to an analysis that better reflects Gibbon’s original, polemical thesis and writing style by first 1) identifying a comprehensive list of moralizing terms (including adjectives like ‘superstitious’ and its variants) harvested from the whole text, and then 2) analyzing the occurrences of those terms in the text, and 3) looking for trends in how those terms are employed throughout the text to describe different social, ethnic, religious or occupational groups. As an enlightenment scholar critical of organized religion, Gibbon maintained that the rise of Christianity led to the fall of the western empire by making its denizens less interested in the present life, including in things civic, commercial, and military, the latter of which would have obvious consequences for the defense of the empire against invasion (Gibbon’s thesis is not generally shared by scholars today). Would such an experiment reveal more exactingly where Gibbon’s moralizing emphases change, based on the chapter or volume of the text where such terms occur?
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: