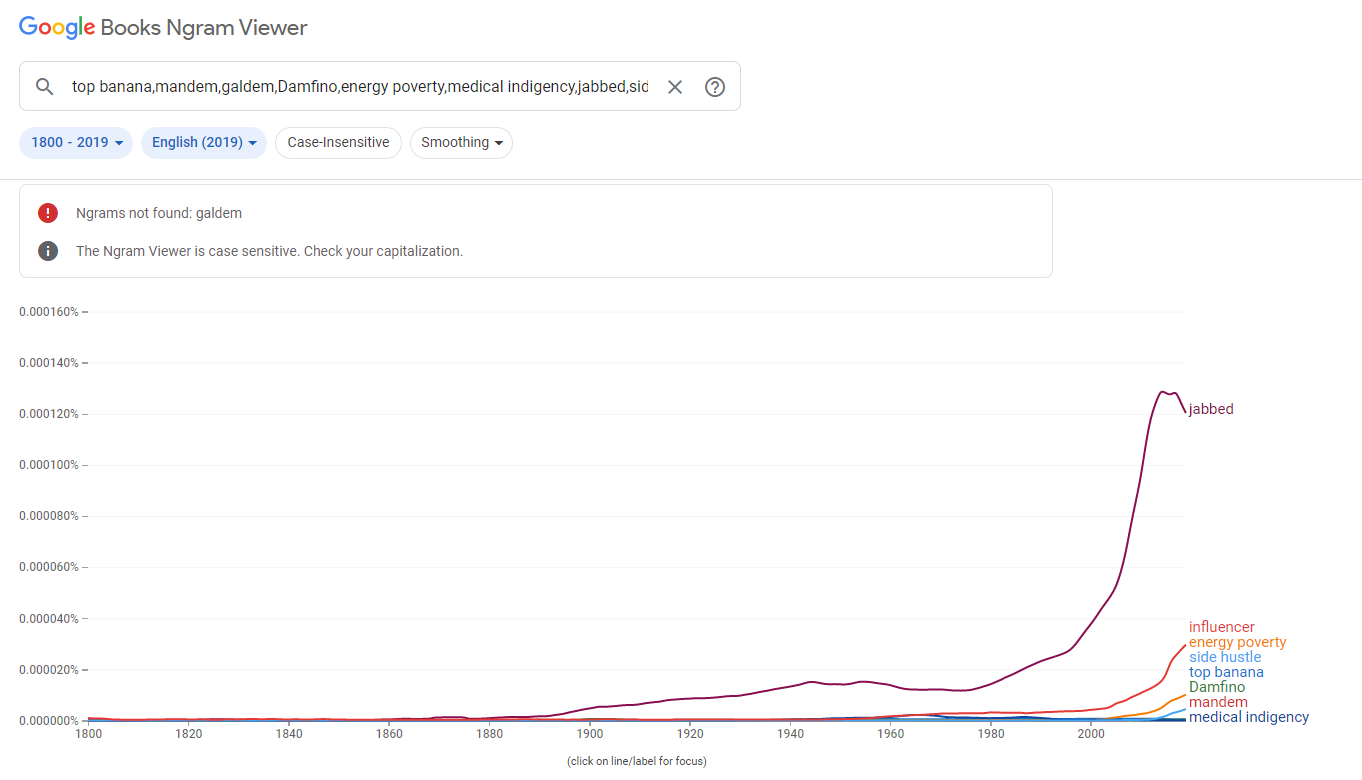
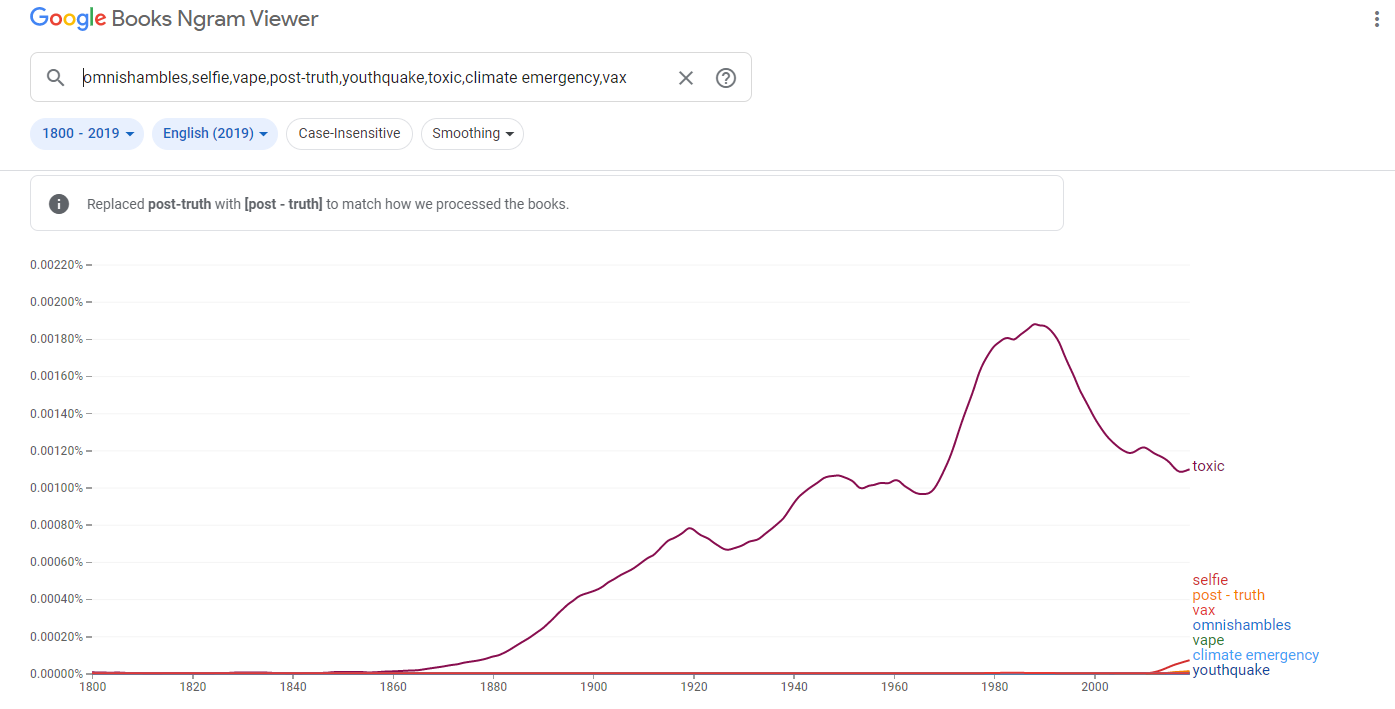
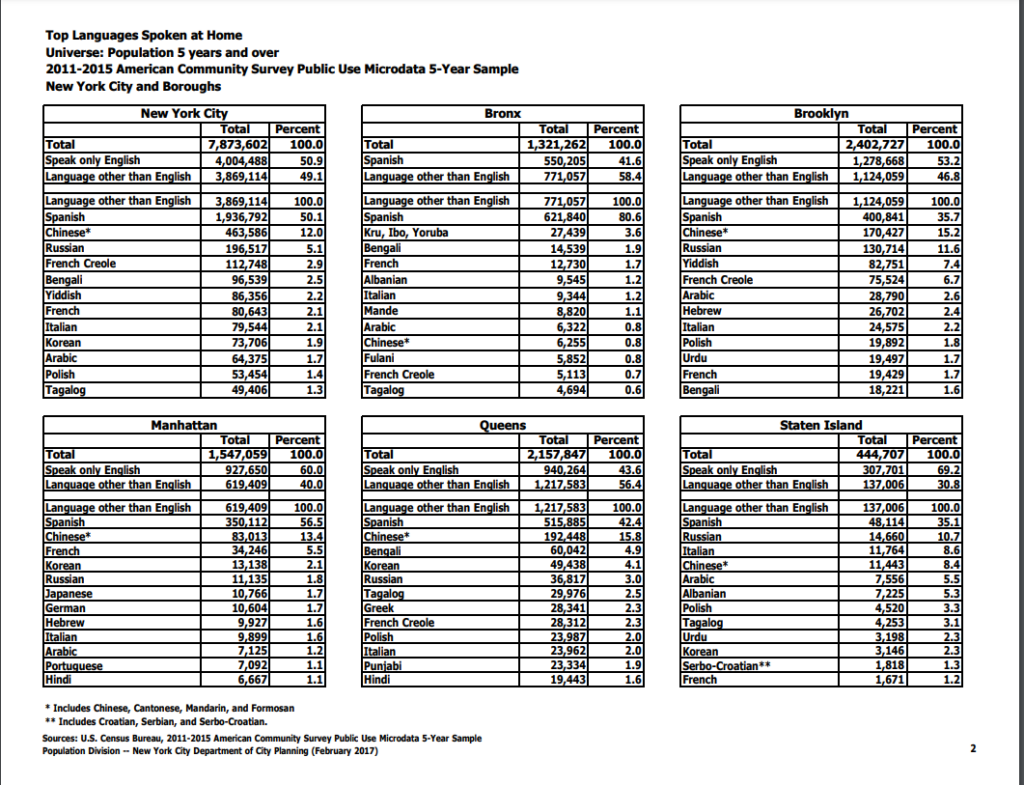
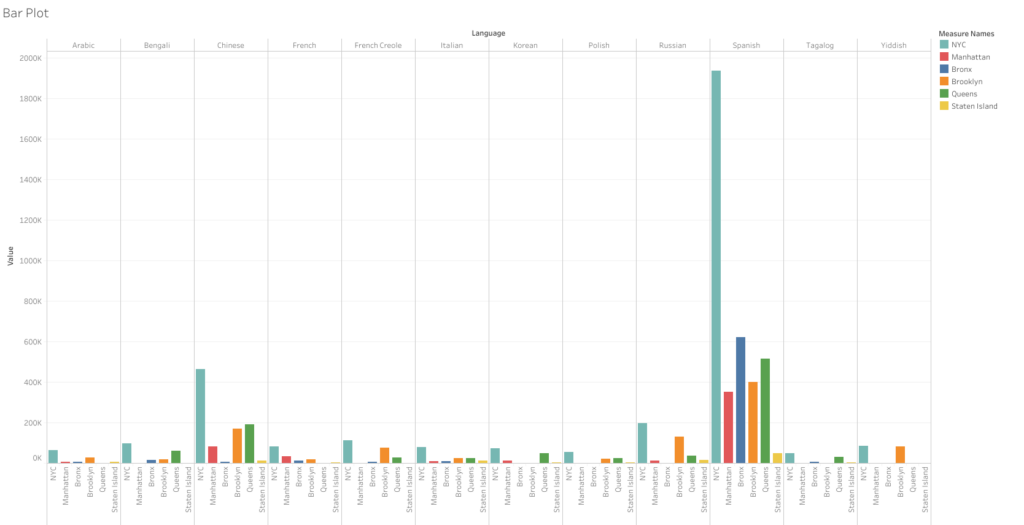
For this assignment, I chose to annotate two similar but somewhat oppositional concepts presented in The Fourth Dimensional Human‘s “Introduction” chapter. My first annotation tackles the following excerpt from the text.
…our daily lives are a series of nets, any of which could be scored and bent at the perpendicular, and thus extended into this other dimension. Increasingly, the moments of our lives audition for digitisation [sic]. A view from the window, a meeting with friends, a thought, an instance of leisure or exasperation — they are all candidates, contestants, even for a dimensional upgrade.
xv
My annotation is somewhat of an instructional design prompt aiming to create discussion.
- Thinking about our analog existence (i.e., the hobbies, chores, routines, and activities in our lives that are not part of the digital existence), what are experiences that could be effectively improved by digitization that have not yet transcended to the “fourth dimension”? Conversely, what aspects of our current analog existence could never be digitized for improvement?
I chose this annotation because I think this is a somewhat crucial part of the text. As readers, we leave the situational narrative and are introduced into the concept of our current-day lives being upended by this concept of the fourth dimension through digitization. The quote I chose to remark on orients the reader and provides examples of how digitization can enter any slice of life. I felt this was a proper point to provide some context into what the author is driving at and to allow the reader to ponder the questions asked in the annotation.
The next part of the text that I annotated was somewhat necessary as a huge Seinfeld fan. The reference to the reverse peephole and that analogy of how it aligns with our current “fourth dimension” living situations was extremely on point to me. So I wanted to orient the student readers to this concept.
The reverse peephole is, in this sense, visionary in its anticipation of the digital revolution, a definitive anxiety of which is that our peepholes have been reversed without our knowing.
xvii
- In today’s world, there are fourth dimensional peepholes spread out across the modern home. In a sense, our homes are reversed much like Kramer’s. What are some examples of a way modern homes have been “reversed” from their analog past? What are the pros and cons to these reversals?
I wanted to get the student reader thinking about the benefits and downfalls of the digital invasion with homes. I want them to think about the benefits of having cameras on devices, “always on” audio assistants (e.g., Siri, Google Assistant, and Alexa) and to tackle whether these are overall assets versus intrusions into our lives. I think this plays off my other annotation well. First, students will consider what they can and cannot digitize effectively. Then, they are asked to consider whether the already-digitized aspects of their lives are mostly positive or negative. This, I think, promotes some of the concepts the author is tackling.