
Franco Moretti’s call for abandoning close reading caused a stir in literary scholarship. Moretti’s intention was to leverage big data to find hidden patterns. This is extremely controversial for assessing a complex state like emotions. What is an emotion? Emotions are psychological states that are unique to each person. “Emotions are defined in various ways depending on who you ask.” – Gendron, 2010. Then how to quantify emotion or is it even possible to quantify emotion? In the world of AI, chatbots, and metrics, how do machine understands emotion? Is it even ethical to use machines for quantifying emotions?
Nevertheless, I have chosen “Frankenstein” by Mary Shelly for this visualization to explore distant reading and analyze emotion to show the masterpiece through the lens of computational analysis. A dictionary-based approach has been used for this purpose. A dictionary is equipped with words and their classified emotion. Texts are prepared, preprocessed, and cleaned using python libraries. The Texts are parsed into word tokens and classified based on the dictionary to generate emotion scores.




This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.
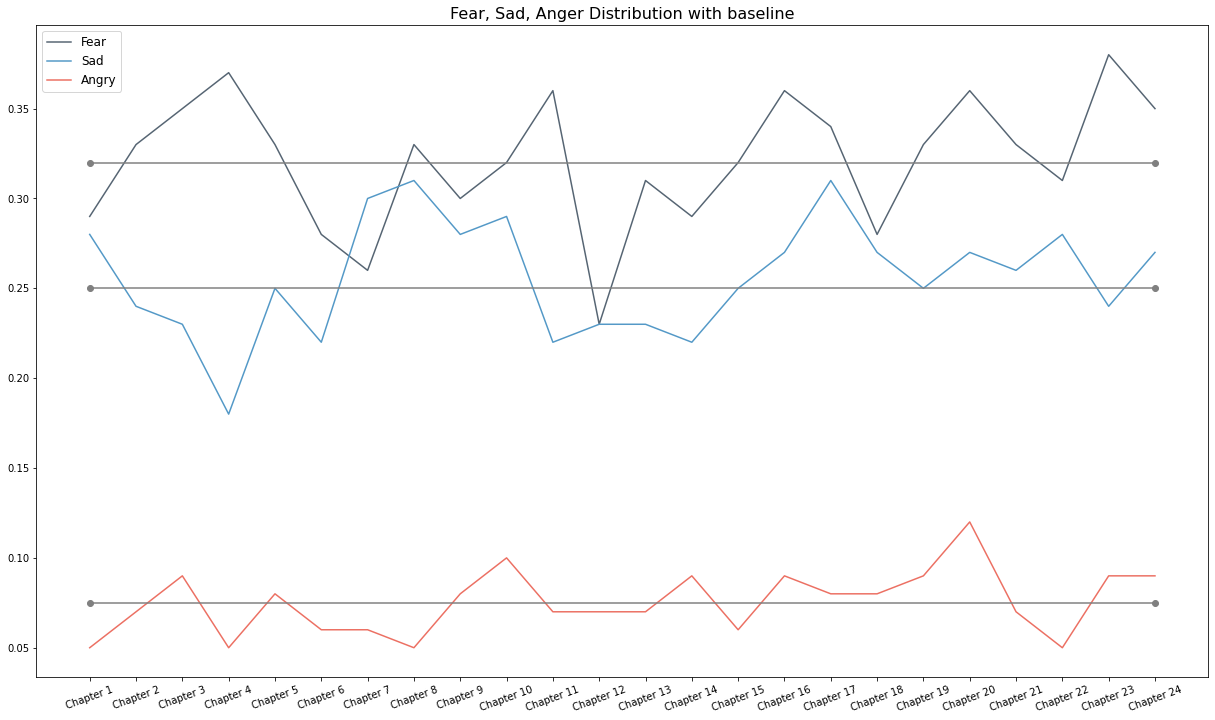
Thanks Zico, this is super interesting. Out of curiosity, can you help me to read the y-axis. How are the scores organised? Do they go from 5% to 35%? What are the ranges (or corridors) that classify the emotions in the book? I hope my questions make sense; I just want to make sure I fully understand the charts. Thank you!
Gemma, thanks for the question. Y axis is the emotion score. For example,
emotion score for happy = number of happy words found in the text (in this case chapter) based on the dictionary classification / total number of tokens after preprocessing the text
There is no range, say for example out of 2500 tokens in chapter 1250 is classified as happy. Then emotion score for happy is 0.5.
This is how a dictionary looks
|happy | Angry | Surprise | Sad| Fear
———————————————————————-
abandon | 0 | 0 | 0 | 1 | 1
abandon classified as sad and fear.
Here is one paper from Saif M. Mohammad and Peter D. Turney “Crowdsourcing a Word–Emotion Association Lexicon”. They developed a dictionary through crowdsourcing.
https://arxiv.org/pdf/1308.6297.pdf